01配置Hadoop
本文最后更新于 2021-08-05 11:42:59
Hadoop配置
Hadoop目录结构
- bin:bin目录是Hadoop最基本的管理脚本和使用脚本所在的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop
- etc:Hadoop配置文件所在的目录,包括:core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml等配置文件。
- include:对外提供的编程库头文件(具体的动态库和静态库在lib目录中),这些文件都是用
C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 - lib:包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
- libexec:各个服务对应的shell配置文件所在的目录,可用于配置日志输出目录、启动参数(比如JVM参数)等基本信息。
- sbin:Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务启动/关闭的脚本。
- share:Hadoop各个模块编译后的Jar包所在目录,这个目录中也包含了Hadoop文档。
配置host
# vim /etc/hosts
192.168.79.128 CentOS
192.168.79.129 node1
192.168.79.130 node2
192.168.79.131 node3配置环境变量
#java环境
JAVA_HOME=/usr/local/jdk1.8.0_161
JRE_HOME=$JAVA_HOME/jre
PATH=$JAVA_HOME/bin:$PATH
export PATH
##HADOOP_HOME
export HADOOP_HOME=/usr/local/soft/hadoop/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin配置ssh免密登录
配置hadoop-env.sh
- 设置 JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_161配置 core-site.xml
<configuration>
<!-- 指定hadoop文件系统 ,以及NameNode-->
<!-- hdfs tfs file gfs-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!--指定hadoop运行时产生文件的储存目录 默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop/tmp_file_dir</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--hdfs网页的用户权限-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--指定secondary nameNode-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
</configuration>
配置 mapred-site.xml
<configuration>
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
配置 yarn-site.xml
<configuration>
<!--menodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!--Yarn打印工作日志-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--错误: 找不到或无法加载主类org.apache.hadoop.mapreduce.v2.app.MRAppMaster-->
<!--value为 执行命令 hadoop classpath 的输出-->
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/soft/hadoop/hadoop-3.3.0/etc/hadoop:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/common/lib/*:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/common/*:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/hdfs:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/hdfs/lib/*:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/hdfs/*:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/mapreduce/*:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/yarn:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/yarn/lib/*:/usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/yarn/*</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>配置从节点
# /usr/local/soft/hadoop/hadoop-3.3.0/etc/hadoop/workers
node2
node3
格式化主节点
hadoop namenode -format启动所有
# sbin
start-all.sh
# 启动history节点
mapred --daemon start historyserver错误信息
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root- 复制到所有其他从节点
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh root@node2:/usr/local/soft/hadoop/hadoop-3.3.0/sbin/
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh root@node3:/usr/local/soft/hadoop/hadoop-3.3.0/sbin/启动后查看信息
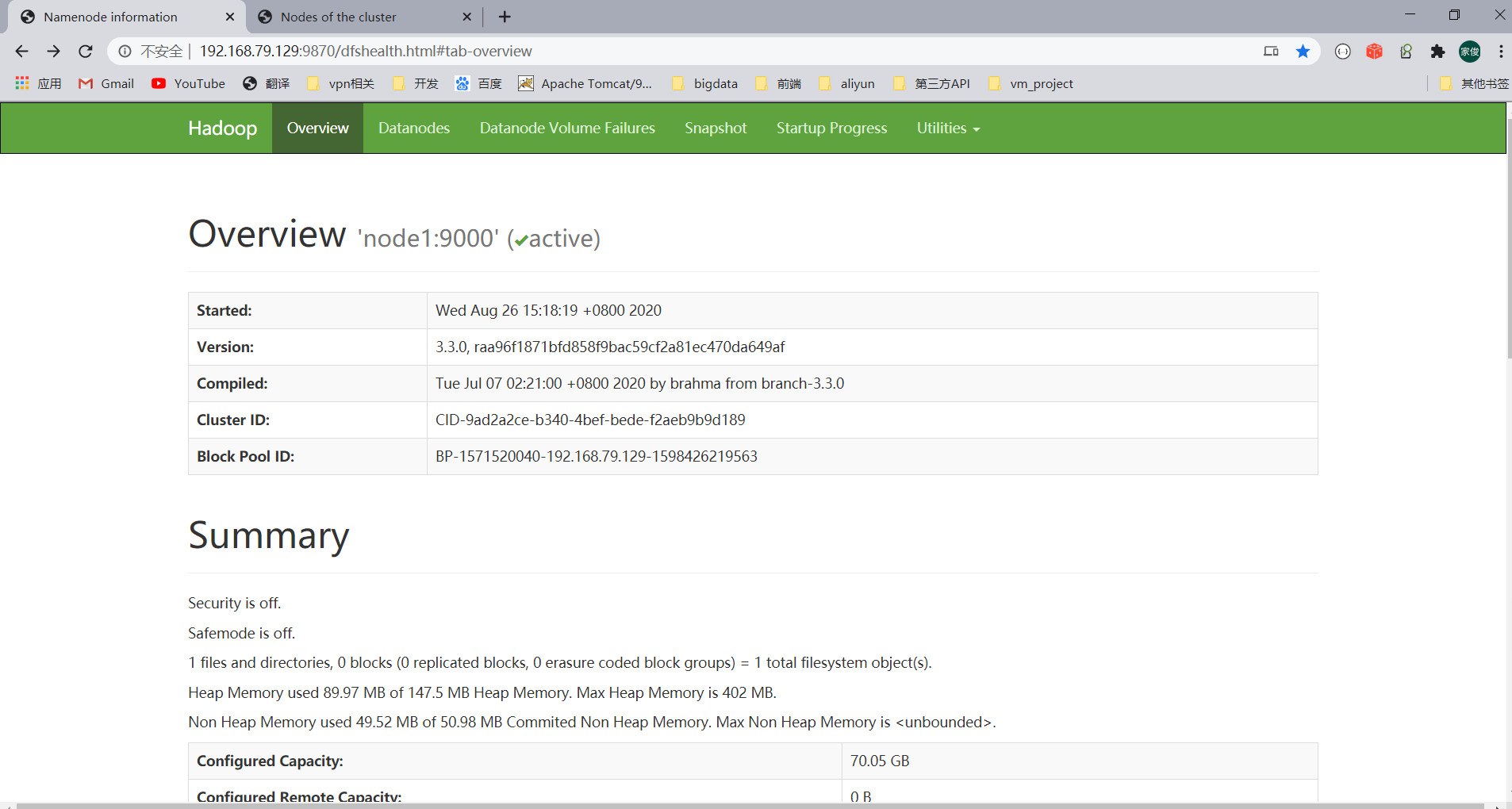
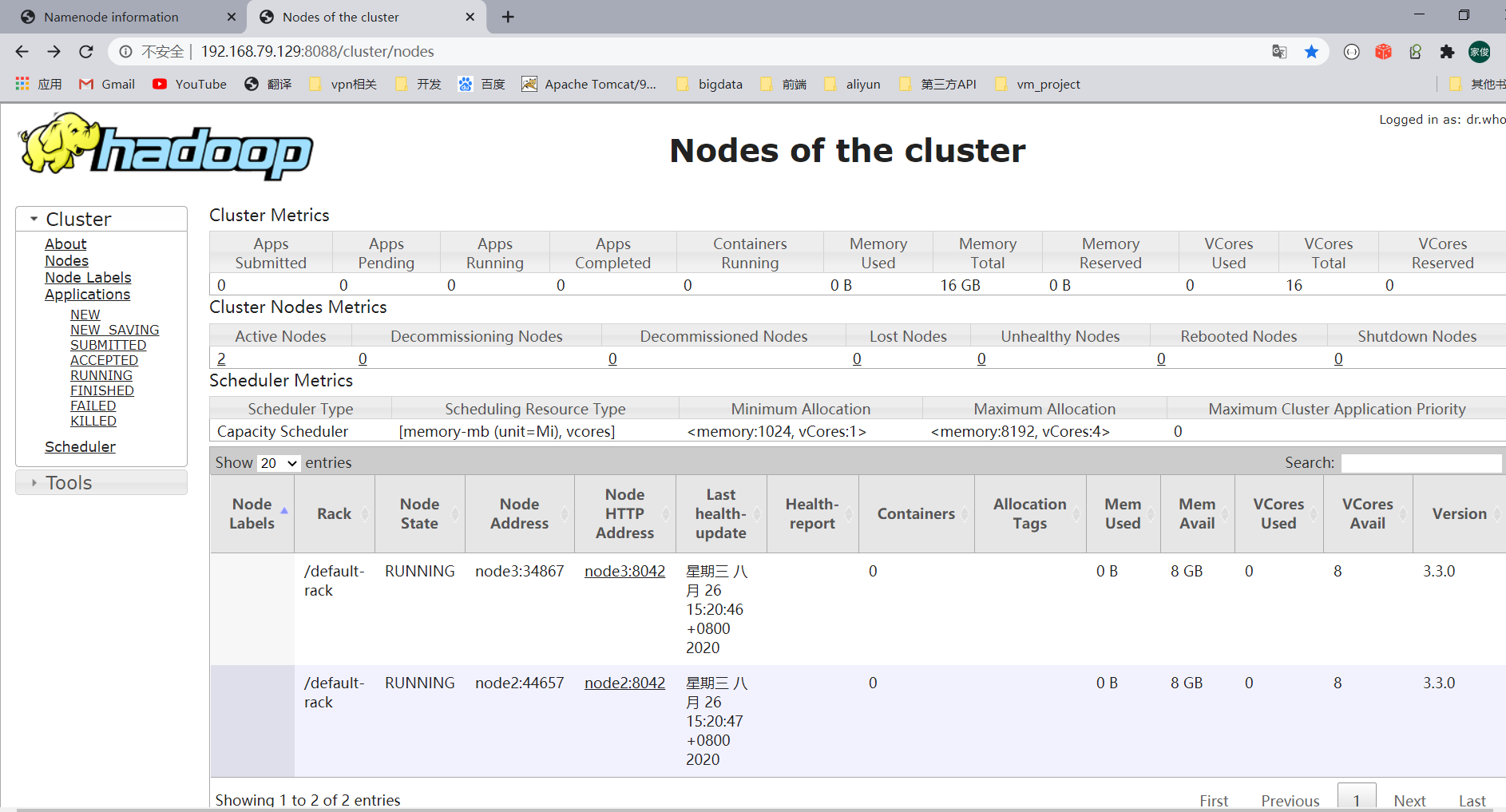
01配置Hadoop
https://jiajun.xyz/2020/10/10/bigdata/01hadoop/01配置Hadoop/