06mr单计数
本文最后更新于 2021-08-05 11:42:59
mr单词计数
WordCountDriver.java
package priv.king.mapReducee2;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import priv.king.mapReduce.WordCountMapper;
import priv.king.mapReduce.WordCountReducer;
/**
* @author king
* TIME: 2020/8/31 - 20:16
**/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
//获取Job对象
// Configuration con = new Configuration();
// Job.getInstance(con);
Job job = Job.getInstance();
//指定job jar包运行的主类
job.setJarByClass(WordCountDriver.class);
//指定所用的Mapper 和Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//job.setOutputFormatClass();
//指定mapper阶段的输出 k v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的k v
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 对进入同一个reduce的 键 或键的部分 进行排序,按照情况需要;
// job.setSortComparatorClass();
// 在reduce的时候(连续两个或多个)两个key不同 但是想分到一组里面(values)可以使用GroupingComparatorClass
// 最后返回的key是最后的key
// job.setGroupingComparatorClass();
// 传入参数是Reducer的继承类
// 目的是优化MapReduce作业使用的带宽,在map任务节点上运行
// 相当于是一个迷你的reduce,部分reduce
// job.setCombinerClass();
//设置reduceTask个数
//reduceTask个数和最终输出文件个数成对应关系
//默认只有一个
//数据分区
//默认分区规则为 mapper输出key value中的key.hashCode%reduceTaskNum
job.setNumReduceTasks(1);
job.setPartitionerClass(MyPartitioner.class);
//指定待处理数据位置
FileInputFormat.setInputPaths(job,"/java_upload");
//指定最终结果输出路径
FileOutputFormat.setOutputPath(job,new Path("/java_upload/result"));
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}WordCountMapper.java
package priv.king.mapReduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author king
* TIME: 2020/8/31 - 18:23
*
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN 输入数据类型 在默认数据读取组件下叫 TextInputFormat,一行一行读取数据,传递给mapper,KEYIN标识每一行数据的起始偏移量,数据类型为LongWritable
* VALUEIN 在默认数据读取组件下 为一行内容 数据类型为String(Text)
* KEYOUT 输出类型,单词计数的key为单词 为String(Text)
* VALUEOUT 输出单词的次数
**/
public class WordCountMapper extends Mapper<LongWritable, Text,Text,IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(" ");
for (String s : split) {
context.write(new Text(s),new IntWritable(1));
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}WordCountReducer.java
package priv.king.mapReduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @author king
* TIME: 2020/8/31 - 20:11
**/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
sum+=iterator.next().get();
}
context.write(key,new IntWritable(sum));
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}Combiner
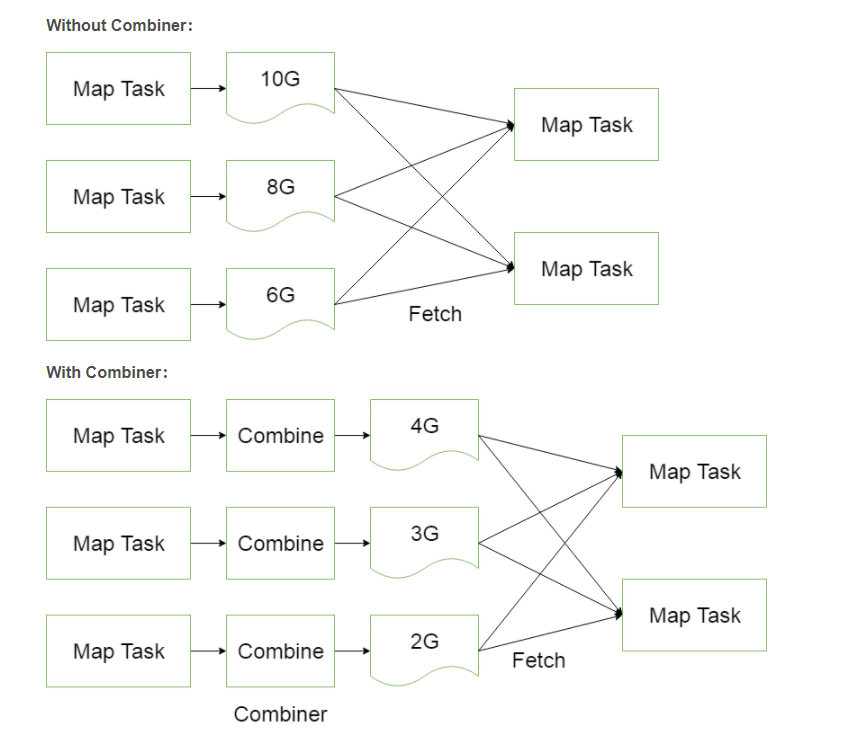
package com.darren.hadoop.wordcount.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCoundCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
int count = value.get();
sum += count;
}
context.write(key, new IntWritable(sum));
}
}06mr单计数
https://jiajun.xyz/2020/10/10/bigdata/01hadoop/06mr单计数/