12SpringJPA
Spring JPA
配置
<dependency
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>spring.datasource.url=jdbc:mysql://172.16.181.199:3306/newwxdb?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password='xxxxx'
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driverClassName=com.mysql.jdbc.Driver
# 数据源初始化大小,最小,最大
spring.datasource.initialSize=3
spring.datasource.minIdle=3
spring.datasource.maxActive=20
# 配置获取连接等待超时的时间
spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,’wall’用于防火墙
spring.datasource.filters=stat,wall,log4j
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# 验证数据库链接有效性
spring.datasource.validationQuery=SELECT * FROM Test
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
spring.datasource.testWhileIdle=true
spring.jpa.database-platform=org.hibernate.dialect.MySQL5Dialect
spring.jpa.database=MYSQL
spring.jpa.hibernate.ddl-auto=none
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.hbm2ddl.auto=none
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialectspring.datasource.validationQuery
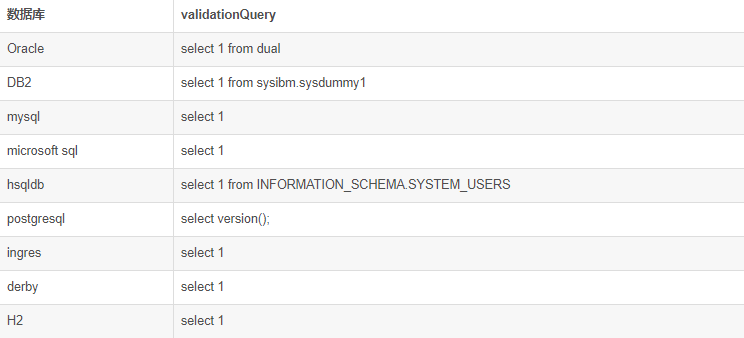
spring.jpa.hibernate.ddl-auto
ddl-auto:create—-每次运行该程序,没有表格会新建表格,表内有数据会清空
ddl-auto:create-drop—-每次程序结束的时候会清空表
ddl-auto:update—-每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
ddl-auto:validate—-运行程序会校验数据与数据库的字段类型是否相同,不同会报错
ddl-auto:none —-不做操作
嵌入式数据库(Oracle、Sybase、MySQL、SQL Server…) 默认为
create-drop数据库服务器(SQLite、Berkeley DB…) 默认为
none
@Table
- 用来定义表的属性
- name:表名
- catalog:对应关系数据库中的catalog
- schema:对应关系数据库中的schema
- UniqueConstraints:定义一个UniqueConstraint数组,指定需要建唯一约束的列.UniqueConstraint定义在Table或SecondaryTable元数据里,用来指定建表时需要建唯一约束的列。
@Entity
@Table(
name="EMPLOYEE",
uniqueConstraints=
@UniqueConstraint(columnNames={"EMP_ID", "EMP_NAME"})
)
public class Employee { ... }@ID 和 @GeneratedValue
- @ID 标识为主键
- @GeneratedValue 定制主键生成策略
JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTO.
- TABLE:使用一个特定的数据库表格来保存主键。
- SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
- IDENTITY:主键由数据库自动生成(主要是自动增长型)
- AUTO:主键由程序控制(也是默认的,在指定主键时,如果不指定主键生成策略,默认为AUTO)
支持情况
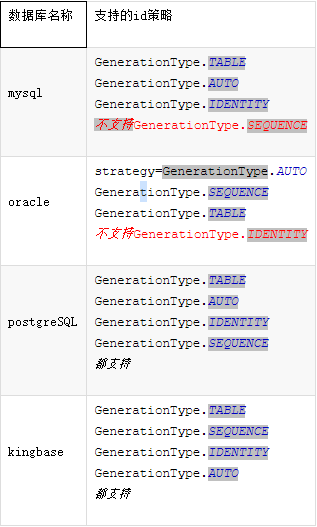
主键产生策略通过GenerationType来指定。GenerationType是一个枚举,它定义了主键产生策略的类型。
- AUTO 自动选择一个最适合底层数据库的主键生成策略。如MySQL会自动对应auto increment。这个是默认选项,即如果只写@GeneratedValue,等价于@GeneratedValue(strategy=GenerationType.AUTO)。
- IDENTITY 表自增长字段,Oracle不支持这种方式。
- SEQUENCE 通过序列产生主键,MySQL不支持这种方式。
- TABLE 通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。不同的JPA实现商生成的表名是不同的,如 OpenJPA生成openjpa_sequence_table表,Hibernate生成一个hibernate_sequences表,而TopLink则生成sequence表。这些表都具有一个序列名和对应值两个字段,如SEQ_NAME和SEQ_COUNT。
如果使用Hibernate对JPA的实现,可以使用Hibernate对主键生成策略的扩展,通过Hibernate的@GenericGenerator实现。

一对一 一对多 多对多查询
一对一 @OneToOne关系映射
- 通过外键的方式
@Entity public class People { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id", nullable = false) private Long id;//id @Column(name = "name", nullable = true, length = 20) private String name;//姓名 @Column(name = "sex", nullable = true, length = 1) private String sex;//性别 @Column(name = "birthday", nullable = true) private Timestamp birthday;//出生日期 @OneToOne(cascade=CascadeType.ALL)//People是关系的维护端,当删除 people,会级联删除 address @JoinColumn(name = "address_id", referencedColumnName = "id") private Address address;//地址 }
@Entity
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;//id
@Column(name = "phone", nullable = true, length = 11)
private String phone;//手机
@Column(name = "zipcode", nullable = true, length = 6)
private String zipcode;//邮政编码
@Column(name = "address", nullable = true, length = 100)
private String address;//地址
//如果不需要根据Address级联查询People,可以注释掉
// @OneToOne(mappedBy = "address", cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false)
// cascade级联操作 保存,更新,删除,刷新
// private People people;
}- 通过关联表
@Entity
public class People {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;//id
@Column(name = "name", nullable = true, length = 20)
private String name;//姓名
@Column(name = "sex", nullable = true, length = 1)
private String sex;//性别
@Column(name = "birthday", nullable = true)
private Timestamp birthday;//出生日期
@OneToOne(cascade=CascadeType.ALL)//People是关系的维护端
@JoinTable(name = "people_address",
joinColumns = @JoinColumn(name="people_id"),
inverseJoinColumns = @JoinColumn(name = "address_id"))//通过关联表保存一对一的关系
private Address address;//地址
}@OneToMany 和 @ManyToOne
- 多端维护关系,一端被维护关系
@Entity
public class Author {
@Id // 主键
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增长策略
private Long id; //id
@NotEmpty(message = "姓名不能为空")
@Size(min=2, max=20)
@Column(nullable = false, length = 20)
private String name;//姓名
@OneToMany(mappedBy = "author",cascade=CascadeType.ALL,fetch=FetchType.LAZY)
//级联保存、更新、删除、刷新;延迟加载。当删除用户,会级联删除该用户的所有文章
//拥有mappedBy注解的实体类为关系被维护端
//mappedBy="author"中的author是Article中的author属性
private List<Article> articleList;//文章列表
}@Entity
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增长策略
@Column(name = "id", nullable = false)
private Long id;
@NotEmpty(message = "标题不能为空")
@Size(min = 2, max = 50)
@Column(nullable = false, length = 50) // 映射为字段,值不能为空
private String title;
@Lob // 大对象,映射 MySQL 的 Long Text 类型
@Basic(fetch = FetchType.LAZY) // 懒加载
@NotEmpty(message = "内容不能为空")
@Size(min = 2)
@Column(nullable = false) // 映射为字段,值不能为空
private String content;//文章全文内容
@ManyToOne(cascade={CascadeType.MERGE,CascadeType.REFRESH},optional=false)//可选属性optional=false,表示author不能为空。删除文章,不影响用户
@JoinColumn(name="author_id")//设置在article表中的关联字段(外键)
private Author author;//所属作者
}@ManyToMany
- 多对多关系中一般不设置级联保存、级联删除、级联更新等操作。
- 可以随意指定一方为关系维护端,在这个例子中,我指定 User 为关系维护端,所以生成的关联表名称为: user_authority,关联表的字段为:user_id 和 authority_id。
- 多对多关系的绑定由关系维护端来完成,即由 User.setAuthorities(authorities) 来绑定多对多的关系。关系被维护端不能绑定关系,即Game不能绑定关系。
- 多对多关系的解除由关系维护端来完成,即由Player.getGames().remove(game)来解除多对多的关系。关系被维护端不能解除关系,即Game不能解除关系。
- 如果 User 和 Authority 已经绑定了多对多的关系,那么不能直接删除 Authority,需要由 User 解除关系后,才能删除 Authority。但是可以直接删除 User,因为 User 是关系维护端,删除 User 时,会先解除 User 和 Authority 的关系,再删除 Authority。
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotEmpty(message = "账号不能为空")
@Size(min=3, max=20)
@Column(nullable = false, length = 20, unique = true)
private String username; // 用户账号,用户登录时的唯一标识
@NotEmpty(message = "密码不能为空")
@Size(max=100)
@Column(length = 100)
private String password; // 登录时密码
@ManyToMany
@JoinTable(name = "user_authority",joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "authority_id"))
//1、关系维护端,负责多对多关系的绑定和解除
//2、@JoinTable注解的name属性指定关联表的名字,joinColumns指定外键的名字,关联到关系维护端(User)
//3、inverseJoinColumns指定外键的名字,要关联的关系被维护端(Authority)
//4、其实可以不使用@JoinTable注解,默认生成的关联表名称为主表表名+下划线+从表表名,
//即表名为user_authority
//关联到主表的外键名:主表名+下划线+主表中的主键列名,即user_id
//关联到从表的外键名:主表中用于关联的属性名+下划线+从表的主键列名,即authority_id
//主表就是关系维护端对应的表,从表就是关系被维护端对应的表
private List<Authority> authorityList;
}@Entity
public class Authority {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(nullable = false)
private String name; //权限名
//mappedBy="authorityList"属性表明Author是关系被维护端
@ManyToMany(mappedBy = "authorityList")
private List<User> userList;
}@Query
/**
* 查询根据参数位置
* @param userName
* @return
*/
@Query(value = "select * from sys_user where userName = ?1",nativeQuery = true)
SysUser findSysUserByUserName(String userName);
/**
* 查询根据Param注解
* @param userName
* @return
*/
@Query(value = "select u from SysUser u where u.userName = :userName")
SysUser findSysUserByUserNameTwo(@Param("userName") String userName);JpaRepository<T,ID>
JpaRepository<T,ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
T getOne(ID id);
@Override
<S extends T> List<S> findAll(Example<S> example);
@Override
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
public interface QueryByExampleExecutor<T> {
<S extends T> Optional<S> findOne(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
<S extends T> long count(Example<S> example);
<S extends T> boolean exists(Example<S> example);
}
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
example
///Sort.Direction是个枚举有ASC(升序)和DESC(降序)
Sort.Direction sort = Sort.Direction.ASC;
///PageRequest继承于AbstractPageRequest并且实现了Pageable
///获取PageRequest对象 index:页码 从0开始 size每页容量 sort排序方式 "id"->properties 以谁为准排序
Pageable pageable = PageRequest.of(index, size, sort, "id");
///要匹配的实例对象
Product exPro = new Product();
exPro.setVendorId(id);
///定义匹配规则 匹配"vendorId"这个属性 exact 精准匹配
ExampleMatcher exampleMatcher = ExampleMatcher.matching().withMatcher("vendorId",ExampleMatcher.GenericPropertyMatchers.exact());
Example<Product> example = Example.of(exPro,exampleMatcher);
Page<Product> page = productService.productRespository.findAll(example,pageable);
///获取总页数
page.getTotalPages();
///获取总元素个数
page.getTotalElements();
///获取该分页的列表
page.getContent();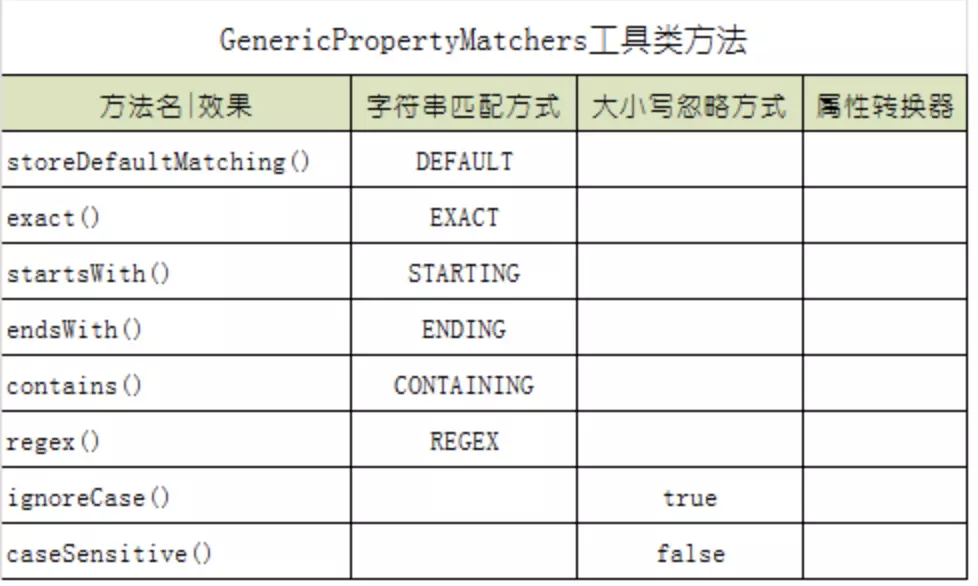
JpaSpecificationExecutor
public interface JpaSpecificationExecutor<T> {
Optional<T> findOne(@Nullable Specification<T> spec);
List<T> findAll(@Nullable Specification<T> spec);
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
long count(@Nullable Specification<T> spec);
}example
public void testSpecificaiton() {
List<Student> stus = studentSpecificationRepository.findAll(new Specification<Student>() {
@Override
public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
//root.get("address")表示获取address这个字段名称,like表示执行like查询,%zt%表示值
Predicate p1 = criteriaBuilder.like(root.get("address"), "%zt%");
Predicate p2 = criteriaBuilder.greaterThan(root.get("id"),3);
//将两个查询条件联合起来之后返回Predicate对象
return criteriaBuilder.and(p1,p2);
}
});
Assert.assertEquals(2,stus.size());
Assert.assertEquals("oo",stus.get(0).getName());
}public void testSpecificaiton2() {
//第一个Specification定义了两个or的组合
Specification<Student> s1 = new Specification<Student>() {
@Override
public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Predicate p1 = criteriaBuilder.equal(root.get("id"),"2");
Predicate p2 = criteriaBuilder.equal(root.get("id"),"3");
return criteriaBuilder.or(p1,p2);
}
};
//第二个Specification定义了两个or的组合
Specification<Student> s2 = new Specification<Student>() {
@Override
public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Predicate p1 = criteriaBuilder.like(root.get("address"),"zt%");
Predicate p2 = criteriaBuilder.like(root.get("name"),"foo%");
return criteriaBuilder.or(p1,p2);
}
};
//通过Specifications将两个Specification连接起来,第一个条件加where,第二个是and
List<Student> stus = studentSpecificationRepository.findAll(Specifications.where(s1).and(s2));
Assert.assertEquals(1,stus.size());
Assert.assertEquals(3,stus.get(0).getId());
}private Specification<ExportSubsidyPersonnel> getWhereClause(final long userId, final String agency, final Date startDate, final Date endDate,
final String jobLevel, final String certificateGrade, final String remark) {
return new Specification<ExportSubsidyPersonnel>() {
@Override
public Predicate toPredicate(Root<ExportSubsidyPersonnel> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Predicate predicate = criteriaBuilder.conjunction();
predicate.getExpressions().add(
criteriaBuilder.and(root.<UserInfo>get("userInfo").in(userId))
);
if (!StringUtils.isEmpty(agency)) {
predicate.getExpressions().add(
criteriaBuilder.and(root.<String>get("agency").in(agency)));
}
predicate.getExpressions().add(
criteriaBuilder.between(root.<Date>get("time"), startDate, endDate)
);
if (!StringUtils.isEmpty(jobLevel)) {
predicate.getExpressions().add(
criteriaBuilder.and(root.<String>get("jobLevel").in(jobLevel)));
}
if (!StringUtils.isEmpty(certificateGrade)) {
predicate.getExpressions().add(
criteriaBuilder.and(root.<String>get("certificateGrade").in(certificateGrade)));
}
if (!Const.UNLIMITED.equals(remark)) {
predicate.getExpressions().add(
criteriaBuilder.and(root.<String>get("remark").in(remark)));
}
return predicate;
}
};
}12SpringJPA
https://jiajun.xyz/2020/10/10/java/spring/12SpringJPA/