01基础介绍
本文最后更新于 2021-08-05 11:42:59
HIVE基础介绍
- hive是一款数据仓库软件
- hive可以使用sql来促进对已经在分布式设备中的数据进行读写和管理等操作
- hive在使用时,需要对已经存储的数据进行结构的投影
- hive只能分析结构化数据
- hive在hadoop上,使用hive的前提是先安装Hadoop
优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
- Hive的HQL表达能力有限
- 迭代式算法无法表达
- 数据挖掘方面不擅长
- Hive的效率比较低
- Hive自动生成的MapReduce作业,通常情况下不够智能化
- Hive调优比较困难,粒度较粗
特点
- hive并不是关系型数据库
- 不是基于OLTP(在线事务处理)设计,OLTP软件侧重事务的处理和在线访问
- Hive无法做到实时查询,不支持行级别更新(update,delete)
- Hive要分析的数据存储在HDFS,hive为数据创建的表结构(schema),存储在关系型数据库
- Hive基于OLAP(在线分析处理)设计,侧重分析,不追求效率
- Hive使用类sql,称为HQL对数据分析
- Hive底层使用MapReduce
- Hive容易使用,可扩展
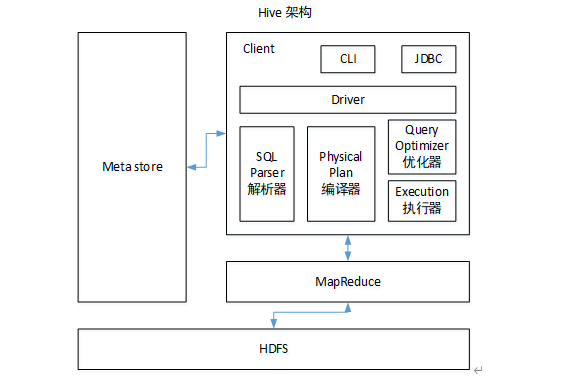
架构
HIVE安装
HDFS中创建目录并赋予权限 (可以修改hive-site配置文件修改该路径)
hive.metastore.warehouse.dir
#存放hive中具体数据目录
hadoop fs -mkdir /data/hive/warehouse
#存放hive运行产生的临时文件
hadoop fs -mkdir /data/hive/tmp
#存放hive日志文件
hadoop fs -mkdir /data/hive/log
#修改文件权限
hadoop fs -chmod -R 777 /data/hive/warehouse
hadoop fs -chmod -R 777 /data/hive/tmp
hadoop fs -chmod -R 777 /data/hive/log下载hive
解压
配置环境变量
#配置hive
export HIVE_HOME=/usr/local/soft/hadoop/hive/apache-hive-2.3.7-bin
export PATH=$PATH:$HIVE_HOME/bin报错 :java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
原因:hive内依赖的guava.jar和中版本不一致
解决办法: hadoop中share/hadoop/common/lib 和hive lib中的guava.jar保留高版本
添加mysql驱动到lib下
修改conf/hive-site.xml
复制 hive-default.xml.template,在里面搜索修改一下配置 不要写在开头 会被后面覆盖
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168..129.105:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--修改hdfs中存储位置 不是必须-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!--在cli模式下显示表名和字段名-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--在cli模式下显示库名-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>执行schematool -dbType mysql -initSchema
报错:Exception in thread “main” java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at org.apache.hadoop.fs.Path.initialize(Path.java:263)
at org.apache.hadoop.fs.Path.
解决办法:
<property>
<name>hive.querylog.location</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
<description>Location of Hive run time structured log file</description>
</property>
<!--将文件中所有的 ${system:java.io.tmpdir} ${system:user.name} 替换-->HIVE日志
Hive的log默认存放在/tmp/root/hive.log目录下(当前用户名下)
修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为hive-log4j.properties
hive.log.dir=/opt/module/hive/logs
HIVE运行
修改core-site.xml
<!--在hadoop的配置文件core-site.xml中添加如下属性:-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
HIVE存储位置
数据
在hdfs中,默认在/user/hive/warehouse路径下
元数据
数据库元数据 在DBS表中
表元数据在TBLS中
列元数据在COLUMNS_V2 中