06自定义函数
本文最后更新于 2021-08-05 11:42:59
自定义UDF函数
1.创建一个Maven工程Hive
2.导入依赖
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
<scope>provided</scope>
</dependency>
</dependencies>3.创建一个类
package xxx.xxx.xxx;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
4.打成jar包上传到服务器/xxx/xxx/xxx/udf.jar
5.将jar包添加到hive的classpath
hive (default)> add jar /xxx/xxx/xxx/udf.jar;
或则是放到hvie的lib或auxlib下
6.创建临时函数与开发好的java class关联
hive (default)> create temporary function mylower as "xxx.xxx.xxx.Lower";
没有加temporary 就是永久函数 ,加了 重启hive就没了
7.即可在hql中使用自定义的函数
hive (default)> select ename, mylower(ename) lowername from emp;
UDF
UDF
@Description(
name = "hello",
value = "_FUNC_(str) - from the input string"
+ "returns the value that is \"Hello $str\" ",
extended = "Example:\n"
+ " > SELECT _FUNC_(str) FROM src;"
)
public class HelloUDF extends UDF{
public String evaluate(String str){
try {
return "Hello " + str;
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return "ERROR";
}
}
//evaluate 可以重载
}GenericUDF
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.serde2.objectinspector.ListObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.BooleanWritable;
@Description(name = "array_contains",
value = "_FUNC_(array, value) - Returns TRUE if the array contains value.",
extended = "Example:\n > SELECT _FUNC_(array(1, 2, 3), 2) FROM src LIMIT 1;\n true")
public class GenericUDFArrayContains extends GenericUDF {
private static final int ARRAY_IDX = 0;
private static final int VALUE_IDX = 1;
private static final int ARG_COUNT = 2;
private static final String FUNC_NAME = "ARRAY_CONTAINS";
private transient ObjectInspector valueOI;
private transient ListObjectInspector arrayOI;
private transient ObjectInspector arrayElementOI;
private BooleanWritable result;
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 2) {
throw new UDFArgumentException("The function ARRAY_CONTAINS accepts 2 arguments.");
}
if (!(arguments[0].getCategory().equals(ObjectInspector.Category.LIST))) {
throw new UDFArgumentTypeException(0, "\"array\" expected at function ARRAY_CONTAINS, but \""
+ arguments[0].getTypeName() + "\" " + "is found");
}
this.arrayOI = ((ListObjectInspector) arguments[0]);
this.arrayElementOI = this.arrayOI.getListElementObjectInspector();
this.valueOI = arguments[1];
if (!(ObjectInspectorUtils.compareTypes(this.arrayElementOI, this.valueOI))) {
throw new UDFArgumentTypeException(1,
"\"" + this.arrayElementOI.getTypeName() + "\"" + " expected at function ARRAY_CONTAINS, but "
+ "\"" + this.valueOI.getTypeName() + "\"" + " is found");
}
if (!(ObjectInspectorUtils.compareSupported(this.valueOI))) {
throw new UDFArgumentException("The function ARRAY_CONTAINS does not support comparison for \""
+ this.valueOI.getTypeName() + "\"" + " types");
}
this.result = new BooleanWritable(false);
return PrimitiveObjectInspectorFactory.writableBooleanObjectInspector;
}
public Object evaluate(GenericUDF.DeferredObject[] arguments) throws HiveException {
this.result.set(false);
Object array = arguments[0].get();
Object value = arguments[1].get();
int arrayLength = this.arrayOI.getListLength(array);
if ((value == null) || (arrayLength <= 0)) {
return this.result;
}
for (int i = 0; i < arrayLength; ++i) {
Object listElement = this.arrayOI.getListElement(array, i);
if ((listElement == null)
|| (ObjectInspectorUtils.compare(value, this.valueOI, listElement, this.arrayElementOI) != 0))
continue;
this.result.set(true);
break;
}
return this.result;
}
public String getDisplayString(String[] children) {
assert (children.length == 2);
return "array_contains(" + children[0] + ", " + children[1] + ")";
}
}@Description(name = "nvl",
value = "_FUNC_(value,default_value) - Returns default value if value is null else returns value",
extended = "Example:\n"
+ " > SELECT _FUNC_(null,'bla') FROM src LIMIT 1;\n" + " bla")
public class GenericUDFNvl extends GenericUDF {
private transient GenericUDFUtils.ReturnObjectInspectorResolver returnOIResolver;
private transient ObjectInspector[] argumentOIs;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
argumentOIs = arguments;
if (arguments.length != 2) {
throw new UDFArgumentLengthException(
"The operator 'NVL' accepts 2 arguments.");
}
returnOIResolver = new GenericUDFUtils.ReturnObjectInspectorResolver(true);
//判断两个类型是否相同
if (!(returnOIResolver.update(arguments[0]) && returnOIResolver
.update(arguments[1]))) {
throw new UDFArgumentTypeException(1,
"The first and seconds arguments of function NLV should have the same type, "
+ "but they are different: \"" + arguments[0].getTypeName()
+ "\" and \"" + arguments[1].getTypeName() + "\"");
}
//输入什么类型 输出什么类型
return returnOIResolver.get();
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
Object retVal = returnOIResolver.convertIfNecessary(arguments[0].get(),
argumentOIs[0]);
if (retVal == null ){
retVal = returnOIResolver.convertIfNecessary(arguments[1].get(),
argumentOIs[1]);
}
return retVal;
}
@Override
public String getDisplayString(String[] children) {
StringBuilder sb = new StringBuilder();
sb.append("NVL(");
sb.append(children[0]);
sb.append(',');
sb.append(children[1]);
sb.append(')');
return sb.toString() ;
}
}UDAF
public class MaxNumberUDAF extends UDAF {
public static class MaxiNumberIntUDAFEvaluator implements UDAFEvaluator {
//最终结果
private FloatWritable result;
//负责初始化计算函数并设置它的内部状态,result是存放最终结果的
public void init() {
result=null;
}
//每次对一个新值进行聚集计算都会调用iterate方法
public boolean iterate(FloatWritable value)
{
if(value==null)
return false;
if(result==null)
result=new FloatWritable(value.get());
else
result.set(Math.max(result.get(), value.get()));
return true;
}
//Hive需要部分聚集结果的时候会调用该方法
//会返回一个封装了聚集计算当前状态的对象
public FloatWritable terminatePartial()
{
return result;
}
//合并两个部分聚集值会调用这个方法
public boolean merge(FloatWritable other)
{
return iterate(other);
}
//Hive需要最终聚集结果时候会调用该方法
public FloatWritable terminate()
{
return result;
}
}
}AbstractGenericUDAFResolver
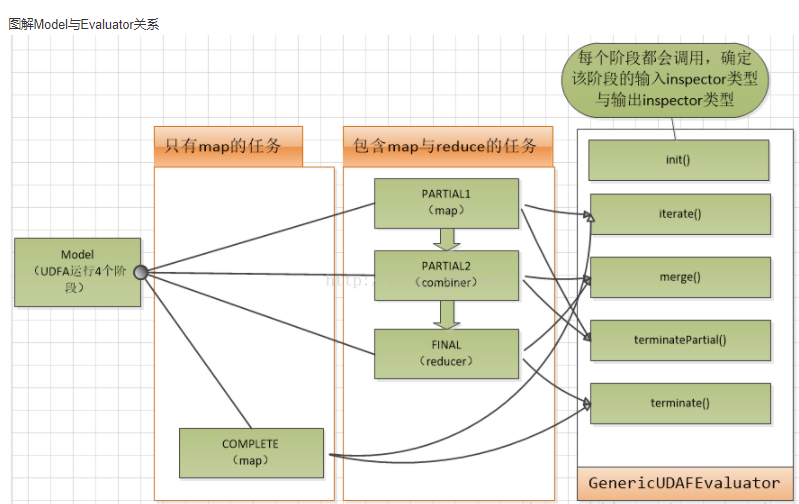

这张图中没有包含COMPLETE,从上面代码中COMPLETE的注释可以看出来,COMPLETE表示直接从原始数据聚合到最终结果,也就是说不存在中间需要先在map端完成部分聚合结果,然后再到reduce端完成最终聚合一个过程,COMPLETE出现在一个完全map only的任务中,所以没有和其他三个阶段一起出现
PARTIAL1
- iterate(AggregationBuffer agg, Object[] parameters)
AggregationBuffer是一个需要你实现的数据结构,用来临时保存聚合的数据,parameters是传递给udaf的实际参数,这个方法的功能可以描述成: 拿到一条条数据记录方法在parameters里,然后聚合到agg中,怎么聚合自己实现,比如agg就是一个数组,你把所有迭代的数据保存到数组中都可以。agg相当于返回结果, - terminatePartial(AggregationBuffer agg)
iterate迭代了map中的数据并保存到agg中,并传递给terminatePartial,接下来terminatePartial完成计算,terminatePartial返回Object类型结果显然还是要传递给下一个阶段PARTIAL2的,但是PARTIAL2怎么知道Object到底是什么?前面提到HIVE都是通过ObjectInspector来获取数据类型信息的,但是PARTIAL2的输入数据ObjectInspector怎么来的?显然每个阶段输出数据对应的ObjectInspector只有你自己知道,上面代码中还有一个init()方法是需要你实现了(init在每一个阶段都会调用一次 ),init的参数m表明了当前阶段(当前处于PARTIAL1),你需要在init中根据当前阶段m,设置一个ObjectInspector表示当前的输出oi就行了,init返回一个ObjectInspcetor表示当前阶段的输出数据类信息(也就是下一阶段的输入数据信息)。
PARTIAL2
PARTIAL2的输入是基于PARTIAL1的输出的,PARTIAL1输出即terminatePartial的返回值。
- merge(AggregationBuffer agg, Object partial)
agg和partial1中的一样,既是参数,也是返回值。partial就是partial1中terminatePartial的返回值,partial的具体数据信息需要你根据ObjectInspector获取了。merger就表示把partial值先放到agg里,待会计算。 - terminatePartial
和partial1一样。
FINAL
FINAL进入到reduce阶段,也就是要完成最终结果的计算,和PARTIAL2不同的是它调用terminate,没什么好说的,输出最终结果而已
public class GenericUDAFColConcat extends AbstractGenericUDAFResolver {
public GenericUDAFColConcat() {
}
/**
在getEvaluator中做一些类型检查,并且返回自定义的GenericUDAFEvaluator
*/
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException {
// col_concat这个udaf需要接收4个参数
if(parameters.length != 4){
throw new UDFArgumentTypeException(parameters.length - 1,
"COL_CONCAT requires 4 argument, got " + parameters.length);
}
// 且只能用于连接一下PRIMITIVE类型的列
if(parameters[0].getCategory() != ObjectInspector.Category.PRIMITIVE){
throw new UDFArgumentTypeException(0,
"COL_CONCAT can only be used to concat PRIMITIVE type column, got " + parameters[0].getTypeName());
}
// 分隔符和包围符,只能时char或者STRING
for(int i = 1; i < parameters.length; ++i){
if(parameters[i].getCategory() != ObjectInspector.Category.PRIMITIVE){
throw new UDFArgumentTypeException(i,
"COL_CONCAT only receive type CHAR/STRING as its 2nd to 4th argument's type, got " + parameters[i].getTypeName());
}
PrimitiveObjectInspector poi = (PrimitiveObjectInspector) TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(parameters[i]);
if(poi.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.CHAR &&
poi.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentTypeException(i,
"COL_CONCAT only receive type CHAR/STRING as its 2nd to 4th argument's type, got " + parameters[i].getTypeName());
}
}
// 返回自定义的XXXEvaluator
return new GenericUDAFCOLCONCATEvaluator();
}
// 需要实现AbstractAggregationBuffer用来保存聚合的值
private static class ColCollectAggregationBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer{
// 遍历的列值暂时都方放到列表中保存起来。
private List<String> colValueList ;
private String open;
private String close;
private String seperator;
private boolean isInit;
public ColCollectAggregationBuffer() {
colValueList = new LinkedList<>();
this.isInit = false;
}
public void init(String open, String close, String seperator){
this.open = open;
this.close = close;
this.seperator = seperator;
this.isInit = true;
}
public boolean isInit(){
return isInit;
}
public String concat(){
String c = StringUtils.join(colValueList,seperator);
return open + c + close;
}
}
public static class GenericUDAFCOLCONCATEvaluator extends GenericUDAFEvaluator{
// transient避免序列化,因为这些成员其实都是在init中初始化了,没有序列化的意义
// inputOIs用来保存PARTIAL1和COMPELE输入数据的oi,这个各个阶段都可能不一样
private transient List<ObjectInspector> inputOIs = new LinkedList<>();
private transient Mode m;
private transient String pString;
// soi保存PARTIAL2和FINAL的输入数据的oi
private transient StructObjectInspector soi;
private transient ListObjectInspector valueFieldOI;
private transient PrimitiveObjectInspector openFieldOI;
private transient PrimitiveObjectInspector closeFieldOI;
private transient PrimitiveObjectInspector seperatorFieldOI;
private transient StructField valueField;
private transient StructField openField;
private transient StructField closeField;
private transient StructField seperatorField;
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
// 父类的init必须调用 目的在于设置Mode
super.init(m,parameters);
this.m = m;
pString = "";
for(ObjectInspector p : parameters){
pString += p.getTypeName();
}
if(m == Mode.PARTIAL1 || m == Mode.COMPLETE){
// 在PARTIAL1和COMPLETE阶段,输入数据都是原始表中数据,而不是中间聚合数据,这里初始化inputOIs
inputOIs.clear();
for(ObjectInspector p : parameters){
inputOIs.add((PrimitiveObjectInspector)p);
}
}else {
// FINAL和PARTIAL2的输入数据OI都是上一阶段的输出,而不是原始表数据,这里parameter[0]其实就是上一阶段的输出oi,具体情况看下面
soi = (StructObjectInspector)parameters[0];
valueField = soi.getStructFieldRef("values");
valueFieldOI = (ListObjectInspector)valueField.getFieldObjectInspector();
openField = soi.getStructFieldRef("open");
openFieldOI = (PrimitiveObjectInspector) openField.getFieldObjectInspector();
closeField = soi.getStructFieldRef("close");
closeFieldOI = (PrimitiveObjectInspector)closeField.getFieldObjectInspector();
seperatorField = soi.getStructFieldRef("seperator");
seperatorFieldOI = (PrimitiveObjectInspector)seperatorField.getFieldObjectInspector();
}
// 这里开始返回各个阶段的输出OI
if(m == Mode.PARTIAL1 || m == Mode.PARTIAL2){
// 后面的terminatePartial实现中,PARTIAL1 PARTIAL2的输出数据都是一个列表,我把中间聚合和结果values, 以及open,close, seperator
// 按序方到列表中,所以这个地方返回的oi是一个StructObjectInspector的实现类,它能够获取list中的值。
ArrayList<ObjectInspector> foi = new ArrayList<>();
foi.add(ObjectInspectorFactory.getStandardListObjectInspector(PrimitiveObjectInspectorFactory.javaStringObjectInspector));
foi.add(
PrimitiveObjectInspectorFactory.javaStringObjectInspector
);
foi.add(
PrimitiveObjectInspectorFactory.javaStringObjectInspector
);
foi.add(
PrimitiveObjectInspectorFactory.javaStringObjectInspector
);
ArrayList<String> fname = new ArrayList<String>();
fname.add("values");
fname.add("open");
fname.add("close");
fname.add("seperator");
return ObjectInspectorFactory.getStandardStructObjectInspector(fname, foi);
}else{
// COMPLETE和FINAL都是返回最终聚合结果了,也就是String,所以这里返回javaStringObjectInspector即可
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
}
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
return new ColCollectAggregationBuffer();
}
@Override
public void reset(AggregationBuffer aggregationBuffer) throws HiveException {
((ColCollectAggregationBuffer)aggregationBuffer).colValueList.clear();
}
// PARTIAL1和COMPLETE调用,iterate里就是把原始数据(参数objects[0])中的值保存到aggregationBuffer的列表中
@Override
public void iterate(AggregationBuffer aggregationBuffer, Object[] objects) throws HiveException {
assert objects.length == 4;
ColCollectAggregationBuffer ccAggregationBuffer = (ColCollectAggregationBuffer)aggregationBuffer;
ccAggregationBuffer.colValueList.add(
PrimitiveObjectInspectorUtils.getString(objects[0], (PrimitiveObjectInspector)inputOIs.get(0)));
if(!ccAggregationBuffer.isInit()){
ccAggregationBuffer.init(
PrimitiveObjectInspectorUtils.getString(objects[1], (PrimitiveObjectInspector)inputOIs.get(1)),
PrimitiveObjectInspectorUtils.getString(objects[2],(PrimitiveObjectInspector)inputOIs.get(2)),
PrimitiveObjectInspectorUtils.getString(objects[3],(PrimitiveObjectInspector)inputOIs.get(3))
);
}
}
// PARTIAL1和PARTIAL2调用
// 返回值传递给给merge中的partial
@Override
public Object terminatePartial(AggregationBuffer aggregationBuffer) throws HiveException {
ColCollectAggregationBuffer ccAggregationBuffer = (ColCollectAggregationBuffer)aggregationBuffer;
List<Object> partialRet = new ArrayList<>();
partialRet.add(ccAggregationBuffer.colValueList);
partialRet.add(ccAggregationBuffer.open);
partialRet.add(ccAggregationBuffer.close);
partialRet.add(ccAggregationBuffer.seperator);
return partialRet;
}
// PARTIAL2和FINAL调用,参数partial对应上面terminatePartial返回的列表,
@Override
public void merge(AggregationBuffer aggregationBuffer, Object partial) throws HiveException {
ColCollectAggregationBuffer ccAggregationBuffer = (ColCollectAggregationBuffer)aggregationBuffer;
if(partial != null){
// soi在init中初始化了,用它来获取partial中数据。
List<Object> partialList = soi.getStructFieldsDataAsList(partial);
// terminalPartial中数据被保存在list中,这个地方拿出来只是简单了合并两个list,其他不变。
List<String> values = (List<String>)valueFieldOI.getList(partialList.get(0));
ccAggregationBuffer.colValueList.addAll(values);
if(!ccAggregationBuffer.isInit){
ccAggregationBuffer.open = PrimitiveObjectInspectorUtils.getString(partialList.get(1), openFieldOI);
ccAggregationBuffer.close = PrimitiveObjectInspectorUtils.getString(partialList.get(2), closeFieldOI);
ccAggregationBuffer.seperator = PrimitiveObjectInspectorUtils.getString(partialList.get(3), seperatorFieldOI);
}
}
}
// FINAL和COMPLETE调用,此时aggregationBuffer中用list保存了原始表表中一列的所有值,这里完成连接操作,返回一个string类型的连接结果。
@Override
public Object terminate(AggregationBuffer aggregationBuffer) throws HiveException {
return ((ColCollectAggregationBuffer)aggregationBuffer).concat();
}
}
}UDTF
public class FeatureParseUDTF extends GenericUDTF {
private PrimitiveObjectInspector stringOI = null;
@Override
public StructObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// 异常检测
if (objectInspectors.length != 1) {
throw new UDFArgumentException("NameParserGenericUDTF() takes exactly one argument");
}
if(objectInspectors[0].getCategory()!=ObjectInspector.Category.PRIMITIVE&&((PrimitiveObjectInspector) objectInspectors[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("NameParserGenericUDTF() takes a string as a parameter");
}
//输入
stringOI = (PrimitiveObjectInspector) objectInspectors[0];
// 输出
List<String> fieldNames = new ArrayList<String>(2);
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>(2);
// 输出列名
fieldNames.add("name");
fieldNames.add("value");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] record) throws HiveException {
final String feature = stringOI.getPrimitiveJavaObject(record[0]).toString();
ArrayList<Object[]> results = parseInputRecord(feature);
Iterator<Object[]> it = results.iterator();
while (it.hasNext()){
Object[] r= it.next();
forward(r);
}
}
/**
* 解析函数,将json格式字符格式化成多行数据
* @param feature
* @return
*/
public ArrayList<Object[]> parseInputRecord(String feature){
ArrayList<Object[]> resultList = null;
try {
JSONObject json = JSON.parseObject(feature);
resultList = new ArrayList<Object[]>();
for (String nameSpace : json.keySet()) {
JSONObject dimensionJson = json.getJSONObject(nameSpace);
for (String dimensionName : dimensionJson.keySet()) {
JSONObject featureJson = dimensionJson.getJSONObject(dimensionName);
for (String featureName : featureJson.keySet()) {
String property_name = nameSpace + ":" + dimensionName + ":" + featureName;
Object[] item = new Object[2];
item[0] = property_name;
item[1] = featureJson.get(featureName);
resultList.add(item);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return resultList;
}
@Override
public void close() throws HiveException {
}
}@Description(name = "explode",
value = "_FUNC_(a) - separates the elements of array a into multiple rows,"
+ " or the elements of a map into multiple rows and columns ")
public class GenericUDTFExplode extends GenericUDTF {
private transient ObjectInspector inputOI = null;
@Override
public void close() throws HiveException {
}
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentException("explode() takes only one argument");
}
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
switch (args[0].getCategory()) {
case LIST:
inputOI = args[0];
fieldNames.add("col");
fieldOIs.add(((ListObjectInspector)inputOI).getListElementObjectInspector());
break;
case MAP:
inputOI = args[0];
fieldNames.add("key");
fieldNames.add("value");
fieldOIs.add(((MapObjectInspector)inputOI).getMapKeyObjectInspector());
fieldOIs.add(((MapObjectInspector)inputOI).getMapValueObjectInspector());
break;
default:
throw new UDFArgumentException("explode() takes an array or a map as a parameter");
}
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);
}
private transient final Object[] forwardListObj = new Object[1];
private transient final Object[] forwardMapObj = new Object[2];
@Override
public void process(Object[] o) throws HiveException {
switch (inputOI.getCategory()) {
case LIST:
ListObjectInspector listOI = (ListObjectInspector)inputOI;
List<?> list = listOI.getList(o[0]);
if (list == null) {
return;
}
for (Object r : list) {
forwardListObj[0] = r;
forward(forwardListObj);
}
break;
case MAP:
MapObjectInspector mapOI = (MapObjectInspector)inputOI;
Map<?,?> map = mapOI.getMap(o[0]);
if (map == null) {
return;
}
for (Entry<?,?> r : map.entrySet()) {
forwardMapObj[0] = r.getKey();
forwardMapObj[1] = r.getValue();
forward(forwardMapObj);
}
break;
default:
throw new TaskExecutionException("explode() can only operate on an array or a map");
}
}
@Override
public String toString() {
return "explode";
}
}