01print&String
本文最后更新于 2022-05-26 11:25:30
print()方法
# 输出字符串
print("hello word")
# 输出数字
print(123)
# 输出表达式
print(123 + 123)
print("fff" + "vvv")
# 完整输出
# sep 分割符
# file 指定输出
# end 指定结尾
# flush 动态刷新
print("aa", "bbb", "cc", sep="_", file=sys.stdout, end="vvv\n", flush=False)
# 默认以空格为分割符
# print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
print("1", "2", "3")
# 不换行
print('1111', end='')
print('222')
# hello word
# 123
# 246
# fffvvv
# aa_bbb_ccvvv
# 1 2 3
# 1111222格式化输出
%格式化
print('hello %s' % 'king')
print('h%s %s' % ('hello', 'world'))
str1 = "the length of (%s) is %d" % ('king', len('king'))
print(str1)
# hello king
# hhello world
# the length of (king) is 4| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
format格式化
占位符
# 格式化输出 format
print('{} {}'.format('WW', 'QQ'))
# 可打乱顺序
print('{1} {0}'.format('AA', 'SS'))
# 可重复
print('{1} {0} {1}'.format('AA', 'SS'))
# 带关键字
print('{a} {b}'.format(a='bb', b='pp'))
# 可在字符串前加f以达到格式化的目的,在{}里加入对象
salary = 9999.99
print(f'My salary is {salary:10.3f}')
# WW QQ
# SS AA
# SS AA SS
# bb pp
# My salary is 9999.990格式转换
# 格式转换
print('{0:b}'.format(10)) # 'b' - 二进制。将数字以2为基数进行输出。
# 1010- ‘b’ - 二进制。将数字以2为基数进行输出。
- ‘c’ - 字符。在打印之前将整数转换成对应的Unicode字符串。
- ‘d’ - 十进制整数。将数字以10为基数进行输出。
- ‘o’ - 八进制。将数字以8为基数进行输出。
- ‘x’ - 十六进制。将数字以16为基数进行输出,9以上的位数用小写字母。
- ‘e’ - 幂符号。用科学计数法打印数字。用’e’表示幂。
- ‘g’ - 一般格式。将数值以fixed-point格式输出。当数值特别大的时候,用幂形式打印。
- ‘n’ - 数字。当值为整数时和’d’相同,值为浮点数时和’g’相同。不同的是它会根据区域设置插入数字分隔符。
- ‘%’ - 百分数。将数值乘以100然后以fixed-point(‘f’)格式打印,值后面会有一个百分号。
格式
print('{} is {:.2f}'.format(1.123, 1.123)) # 取2位小数
print('{:<30}'.format('left aligned')) # 左对齐(默认)
print('{:>30}'.format('right aligned')) # 右对齐
print('{:^30}'.format('centered')) # 中间对齐
print('{:*^30}'.format('centered')) # 使用“*”填充
print('{:0=30}'.format(11)) # 还有“=”只能应用于数字,这种方法可用“>”代替
print('{:+f}; {:+f}'.format(3.14, -3.14)) # 总是显示符号
print('Correct answers: {:.2%}'.format(7 / 8)) # 打印百分号
# 格式化时间
# import datetime
d = datetime.datetime(2010, 7, 4, 12, 15, 58)
print('{:%Y-%m-%d %H:%M:%S}'.format(d))
# 1.123 is 1.12
# left aligned
# right aligned
# centered
# ***********centered***********
# 000000000000000000000000000011
# +3.140000; -3.140000
# Correct answers: 87.50%
# 2010-07-04 12:15:58
字符串前缀
# r: 不转义反斜杠
print(r'input\n')
# f:字符串内支持大括号内的python 表达式
print(f'{name} done in {time.time() - t0:.2f} s')
# b:后面字符串是bytes 类型。
# u/U:表示unicode字符串
print(u'我是含有中文字符组成的字符串。')String
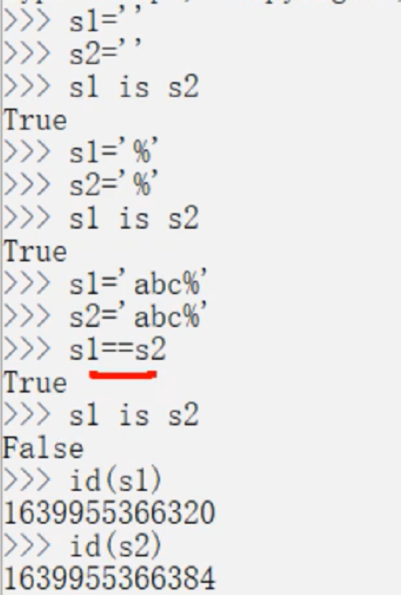
驻留机制
- 字符串的长度为0或1时
- 符合标识符的字符串
- 字符串在编译时进行驻留,而非运行时
- [-5,256]之间的整数
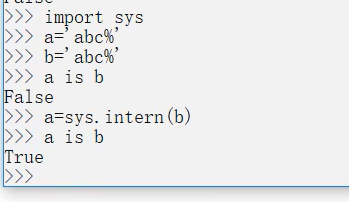
sys中的intern()强制2个字符串指向同一个对象
Pycharm对字符串进行了优化处理
在字符串拼接时建议使用join,而不是+ . join时先计算出所有字符中的长度,再拷贝,只new一次,效率比+高
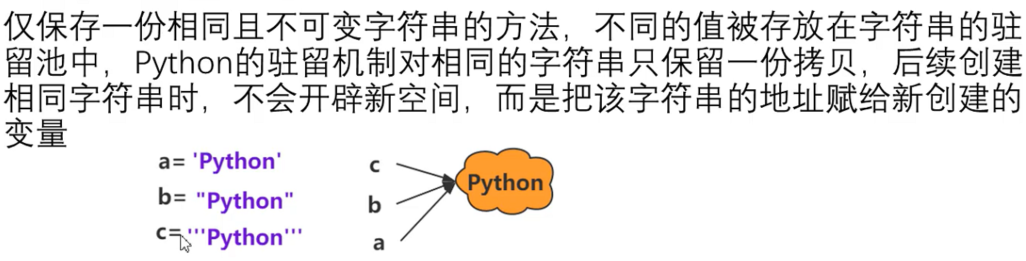
优点:在使用相同值得字符串时。可以直接从常量池中拿,避免频繁得创建和销毁,提高效率

字符串常用方法
查询指定字字符串的下标
var1= "hello,world"
# 寻找指定字符串的下标
# 没找到抛异常
# 返回第一个 `,`的下标
print(var1.index(","))
# 返回第一个 `,`的下标,start=1,end=3,在下标1-3中找
# var1.index(",",1,3)
# 返回最后一个`l`的下标
print(var1.rindex("l"))
# 没有找到返回-1
print(var1.find(","))
print(var1.rfind("l"))字符串的大小写转换
var2 = "tOm cat"
# 转大写
print(var2.upper())
# 转小写
print(var2.lower())
# 大小写交换
print(var2.swapcase())
# 把第一个字符转换为大写,其余转换为小写
print(var2.capitalize())
# 把每个单词的第一个字符转换为大写
print(var2.title())
# TOM CAT
# tom cat
# ToM CAT
# Tom cat
# Tom Cat字符串对齐
var3 = "king"
# 居中 par1->长度 par2->占位符默认是空格
print(var3.center(20, "*"))
# 左对齐 par1->长度 par2->占位符默认是空格
print(var3.ljust(20, "*"))
# 右对齐 par1->长度 par2->占位符默认是空格
print(var3.rjust(20, "*"))
var4="-1001"
# 左侧填充0, 有-,+号提到最前面
print(var4.zfill(10))
# ********king********
# king****************
# ****************king
# -000001001字符串切割
var5="king|tom|jack"
# 从左往右切分,以|为切割符
print(var5.split(sep="|"))
# 从左往右切分,以|为切割符 最多切成两个部分
print(var5.split(sep="|", maxsplit=1))
# ['king', 'tom', 'jack']
# ['king', 'tom|jack']
# 从右往左切分,以|为切割符
print(var5.rsplit(sep="|"))
# 从右往左切分,以|为切割符 最多切成两个部分
print(var5.rsplit(sep="|", maxsplit=1))
# ['king', 'tom', 'jack']
# ['king|tom', 'jack']判断字符串
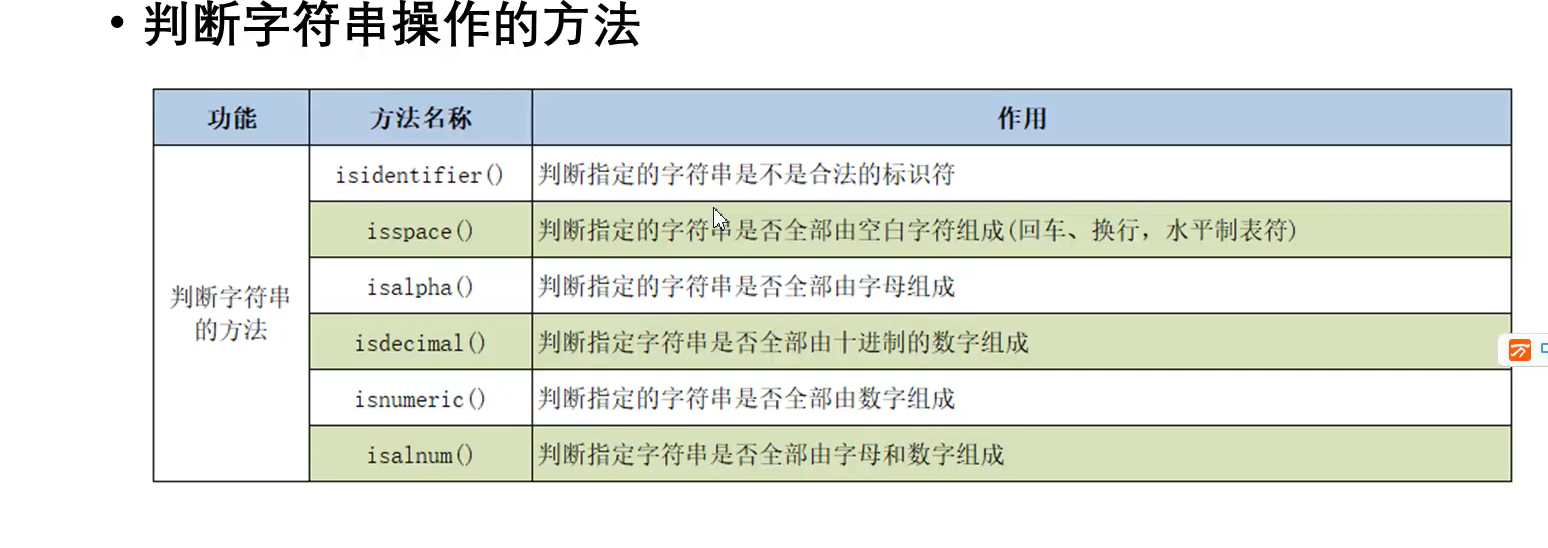
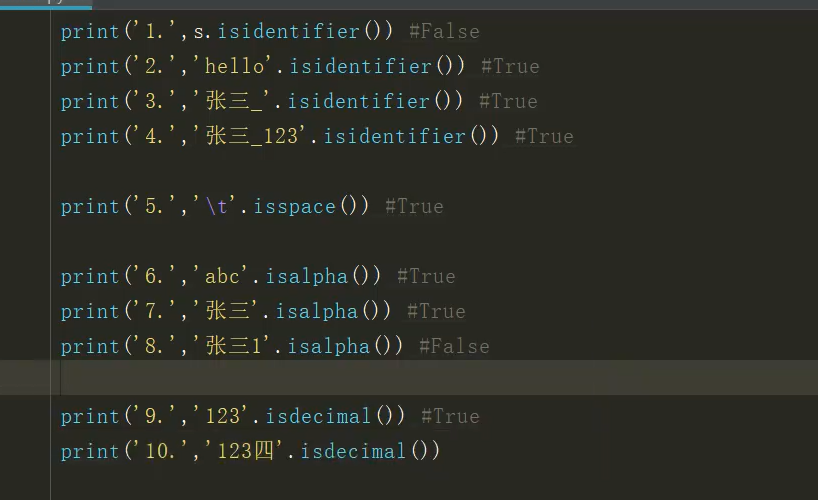
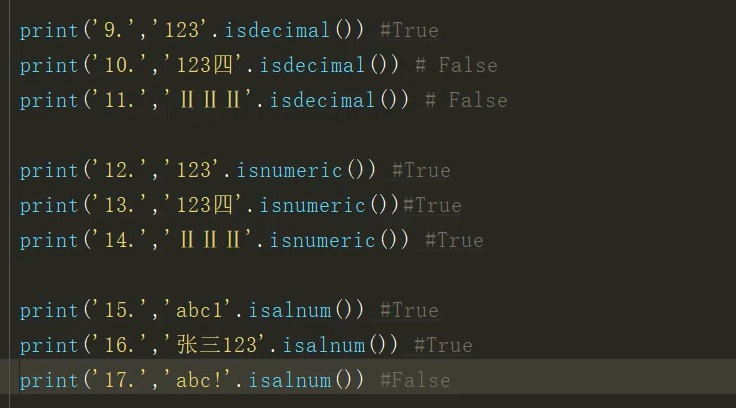
字符串替换连接
var6 = "hello,python"
# 替换
print(var6.replace("python", "java"))
var7 = "hello,python,python,python"
# 最多替换两个 默认-1 替换所有
print(var7.replace("python", "java", 2))
# hello,java
# hello,java,java,python
# 连接成字符串
list = ["king", "tom", "jack"]
print("|".join(list))
print("".join(list))
# king|tom|jack
# kingtomjack字符串编解码
var8 = "哈擦手机擦拭"
encode1 = var8.encode(encoding="GBK")
encode2 = var8.encode(encoding="UTF-8")
print(encode1)
print(encode2)
print(encode1.decode(encoding="GBK"))
print(encode2.decode(encoding="UTF-8"))
# b'\xb9\xfe\xb2\xc1\xca\xd6\xbb\xfa\xb2\xc1\xca\xc3'
# b'\xe5\x93\x88\xe6\x93\xa6\xe6\x89\x8b\xe6\x9c\xba\xe6\x93\xa6\xe6\x8b\xad'
# 哈擦手机擦拭
# 哈擦手机擦拭01print&String
https://jiajun.xyz/2020/10/23/python/01base/01print&String/