01简介
本文最后更新于 2021-08-05 11:42:59
Hbase简介
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
Hbase面向列存储,构建于Hadoop之上,类似于Google的BigTable,提供对10亿级别表数据的快速随机实时读写!
使用场景:单表超千万,上亿,数据规模大,高并发,不适用于做数据分析
Hbase特点
- 海量存储
- HBase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与HBase的极易扩展性息息相关。正式因为HBase良好的扩展性,才为海量数据的存储提供了便利
- 列式存储
- 这里的列式存储其实说的是列族存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定
- 极易扩展
- HBase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
- 通过横向添加RegionSever的机器,进行水平扩展,提升HBase上层的处理能力,提升Hbsae服务更多Region的能力。
- 高并发
- 由于目前大部分使用HBase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,HBase的单个IO延迟下降并不多。能获得高并发、低延迟的服务
- 稀疏
- 稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
Hbase优点
- HDFS有高容错,高扩展的特点,而Hbase基于HDFS实现数据的存储,因此Hbase拥有与生俱来的超强的扩展性和吞吐量
- HBase采用的是Key/Value的存储方式,这意味着,即便面临海量数据的增长,也几乎不会导致查询性能下降。
- HBase是一个列式数据库,相对于于传统的行式数据库而言。当你的单张表字段很多的时候,可以将相同的列(以regin为单位)存在到不同的服务实例上,分散负载压力。
Hbase缺点
- 架构设计复杂,且使用HDFS作为分布式存储,因此只是存储少量数据,它也不会很快。在大数据量时,它慢的不会很明显
- Hbase不支持表的关联操作,因此数据分析是HBase的弱项。常见的 group by或order by只能通过编写MapReduce来实现!
- Hbase部分支持了ACID
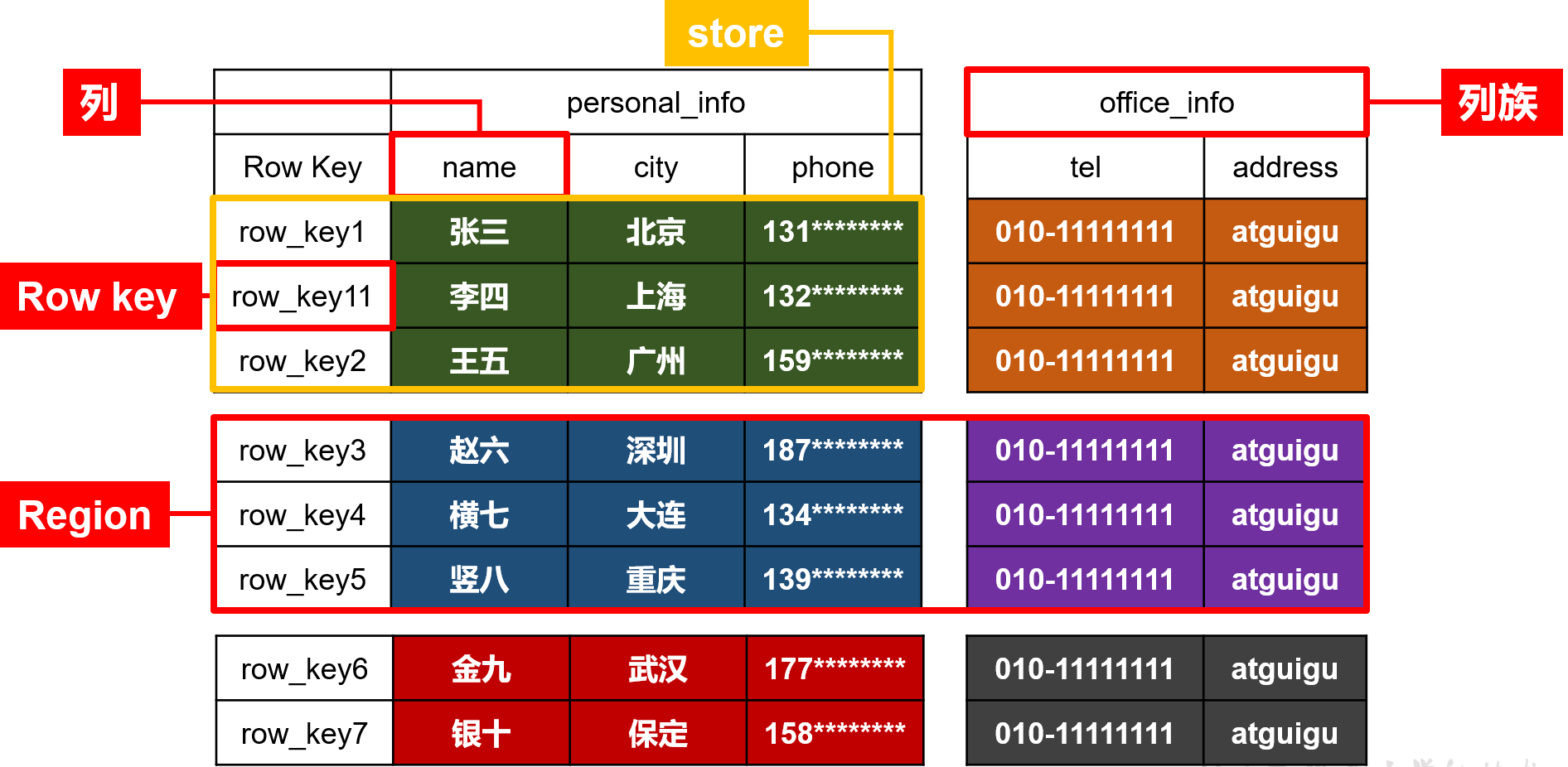
Hbase数据模型
逻辑结构
物理储存结构
概念
NameSpace
- 命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
- 一个表可以自由选择是否有命名空间,如果创建表的时候加上了命名空间后,这个表名字以
<Namespace>:<Table>作为区分
Table
- 类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,数据属性,比如超时时间(TTL),压缩算法(COMPRESSION)等,都在列族的定义中定义,不需要声明具体的列。
- 这意味着,往HBase写入数据时,字段可以动态、按需指定。
Row
- HBase表中的每行数据都由一个RowKey和多个Column(列)组成。一个行包含了多个列,这些列通过列族来分类,行中的数据所属列族只能从该表所定义的列族中选取,不能定义这个表中不存在的列族,否则报错NoSuchColumnFamilyException。
RowKey
- Rowkey由用户指定的一串不重复的字符串定义,是一行的唯一标识!数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
- 如果使用了之前已经定义的RowKey,那么会将之前的数据更新掉!
ColumFamily
- 列族是多个列的集合。一个列族可以动态地灵活定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。
- 列族存在的意义是HBase会把相同列族的列尽量放在同一台机器上,所以说,如果想让某几个列被放到一起,你就给他们定义相同的列族。
- 建议一张表的列族定义的越少越好,列族太多会极大程度地降低数据库性能
ColumQualifier
- Hbase中的列是可以随意定义的,一个行中的列不限名字、不限数量,只限定列族。因此列必须依赖于列族存在!列的名称前必须带着其所属的列族!例如
info:name,info:age。 - 因为HBase中的列全部都是灵活的,可以随便定义的,因此创建表的时候并不需要指定列!列只有在你插入第一条数据的时候才会生成。其他行有没有当前行相同的列是不确定,只有在扫描数据的时候才能得知
- Hbase中的列是可以随意定义的,一个行中的列不限名字、不限数量,只限定列族。因此列必须依赖于列族存在!列的名称前必须带着其所属的列族!例如
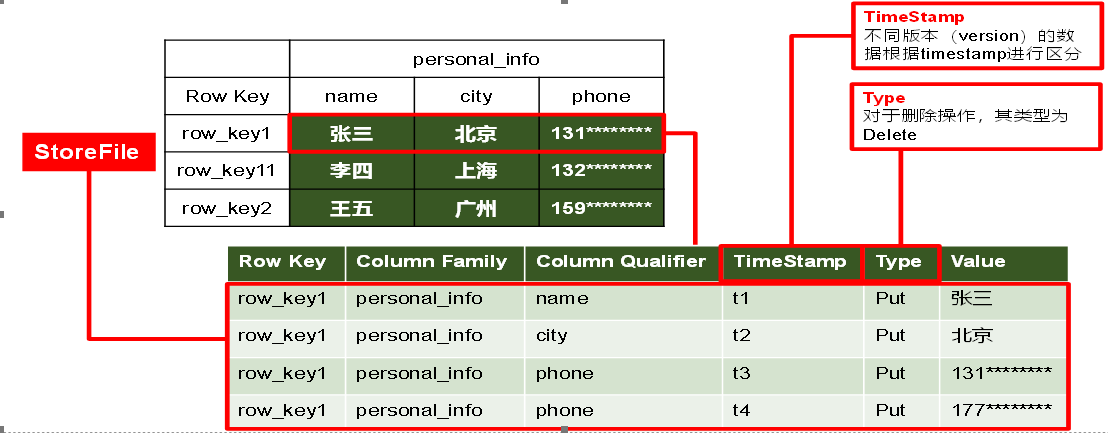
TimeStamp
- 用于标识数据的不同版本(version)。时间戳默认由系统指定,也可以由用户显式指定。
- 在读取单元格的数据时,版本号可以省略,如果不指定,Hbase默认会获取最后一个版本的数据返回
Cell
- 一个列中可以存储多个版本的数据。而每个版本就称为一个单元格(Cell)。
- Cell由{rowkey, column Family:column Qualifier, time Stamp}确定。
- Cell中的数据是没有类型的,全部是字节码形式存贮。
Region
- Region由一个表的若干行组成!在Region中行的排序按照行键(rowkey)字典排序。
- Region不能跨RegionSever,且当数据量大的时候,HBase会拆分Region。
- Region由RegionServer进程管理。HBase在进行负载均衡的时候,一个Region有可能会从当前RegionServer移动到其他RegionServer上。
- Region是基于HDFS的,它的所有数据存取操作都是调用了HDFS的客户端接口来实现的。
架构角色
RegionServer
RegionServer是一个服务,负责多个Region的管理。其实现类为HRegionServer,主要作用如下:
- 对于数据的操作:get, put, delete;
对于Region的操作:splitRegion、compactRegion。
客户端从ZooKeeper获取RegionServer的地址,从而调用相应的服务,获取数据。
Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter,这些操作可能需要跨多个ReginServer,因此需要Master来进行协调!
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
- 即使Master进程宕机,集群依然可以执行数据的读写,只是不能进行表的创建和修改等操作!当然Master也不能宕机太久,有很多必要的操作,比如创建表、修改列族配置,以及更重要的分割和合并都需要它的操作。
Zookeeper
- RegionServer非常依赖ZooKeeper服务,ZooKeeper管理了HBase所有RegionServer的信息,包括具体的数据段存放在哪个RegionServer上。
- 客户端每次与HBase连接,其实都是先与ZooKeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer。Zookeeper中记录了读取数据所需要的元数据表hbase:meata,因此关闭Zookeeper后,客户端是无法实现读操作的!
- HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作
HDFS
- HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
01简介
https://jiajun.xyz/2020/10/31/bigdata/03hbase/01简介/