Presto查询引擎
本文最后更新于 2021-08-05 11:42:59
Presto查询引擎简单了解
Presto是一个分布式的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析
Presto需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等
一条Presto查询可以将多个数据源的数据进行合并分析。比如:select * from a join b where a.id=b.id;,其中表a可以来自Hive,表b可以来自Mysql。
Presto是一个低延迟高并发的内存计算引擎,相比Hive,执行效率要高很多。
架构
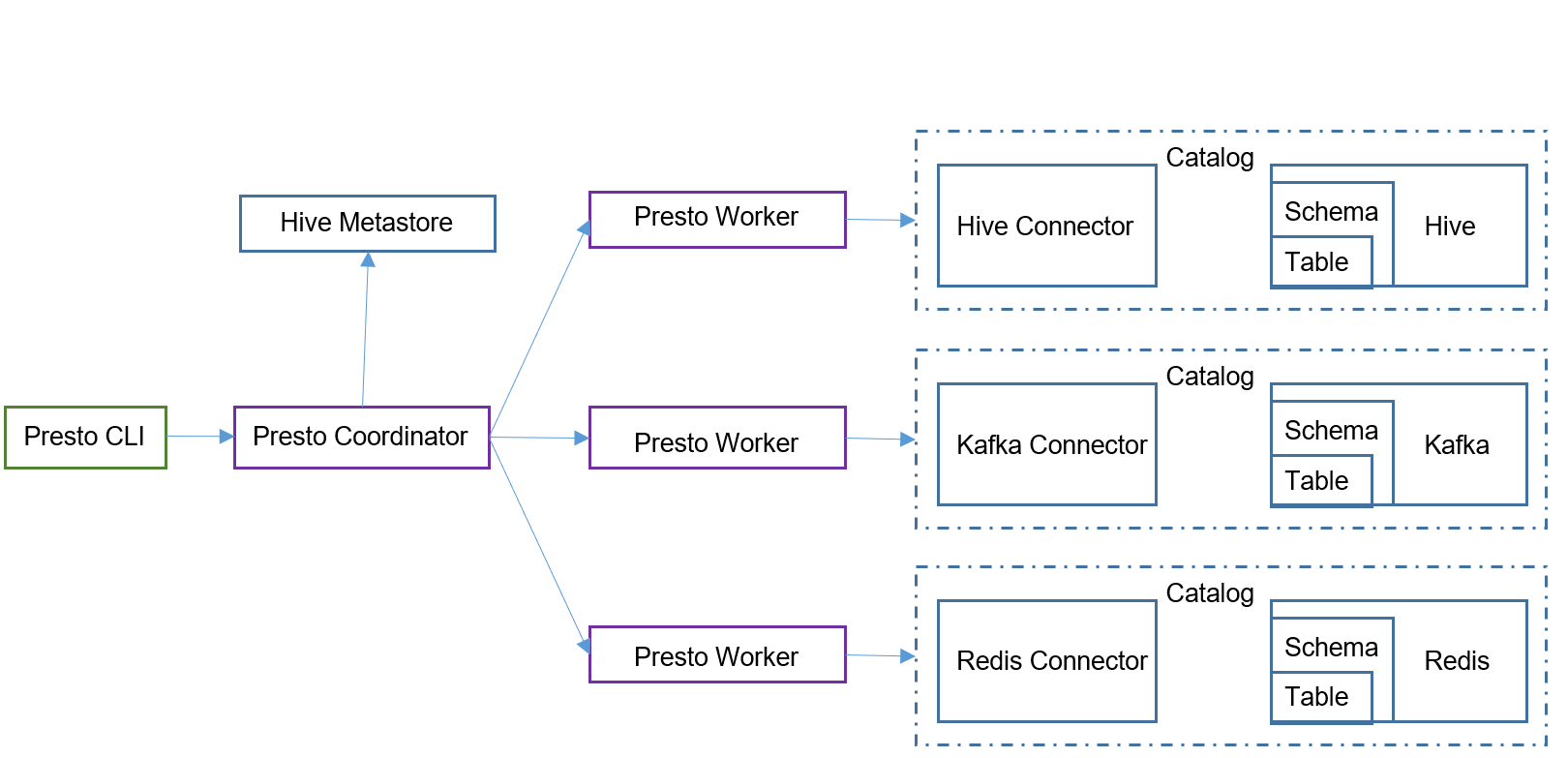
Catalog:就是数据源。Hive是数据源,Mysql也是数据源,Hive 和Mysql都是数据源类型,可以连接多个Hive和多个Mysql,每个连接都有一个名字。一个Catalog可以包含多个Schema,可以通过show catalogs 命令看到Presto连接的所有数据源
Schema:相当于一个数据库实例,一个Schema包含多张数据表。show schemas from catalog_name’可列出catalog_name下的所有schema
Table:数据表,与一般意义上的数据库表相同。show tables from ‘catalog_name.schema_name’可查看’catalog_name.schema_name’下的所有表
Presto与Hive
Hive是一个基于HDFS(分布式文件系统)的一个数据库,具有存储和分析计算能力, 支持大数据量的存储和查询。Hive 作为数据源,结合Presto分布式查询引擎,这样大数据量的查询计算速度就会快很多。
presto是常驻任务,接受请求立即执行,全内存并行计算;hive需要用yarn做资源调度,接受查询需要先申请资源,启动进程,并且中间结果会经过磁盘,所以Presto比hive快