01简介
本文最后更新于 2021-08-05 11:42:59
Kylin简介
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
架构
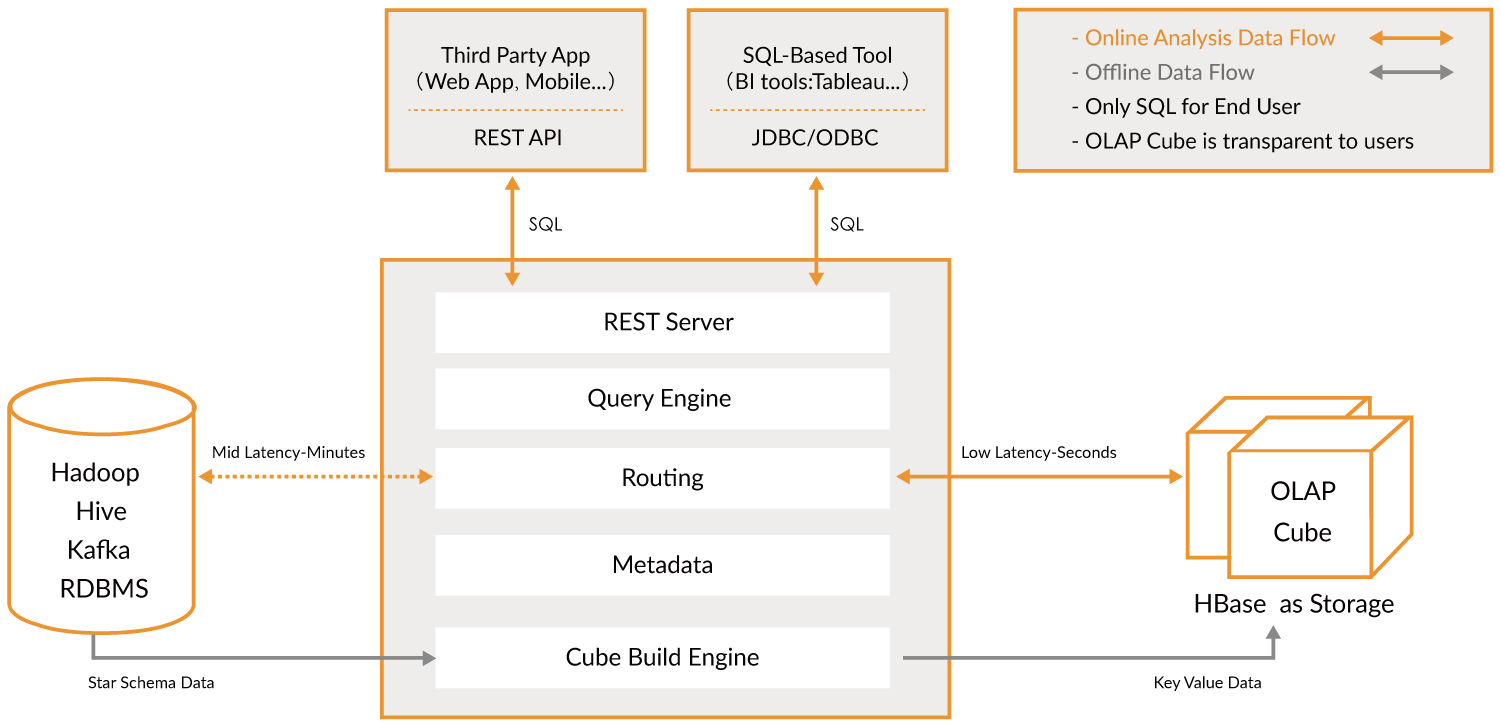
- REST Server
- REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
- Query Engine、
- 当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
- Routing
- 在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
- Metadata
- Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
- Cube Build Engine
- 这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
特点

标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
亚秒级响应:Kylin拥有优异的查询响应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
BI工具集成
安装
- 下载Kylin安装包
- 解压
- 配置HADOOP_HOME,HIVE_HOME,HBASE_HOME
- 启动Hadoop(hdfs,yarn,jobhistoryserver)、Zookeeper、Hbase
- 启动Kylin
kylin.sh start - http://node1:7070/kylin查看Web页面
- 用户名为:ADMIN,密码为:KYLIN
01简介
https://jiajun.xyz/2020/11/16/bigdata/09Kylin/01简介/