03Kylin构建原理
本文最后更新于 2021-08-05 11:42:59
Kylin构建原理
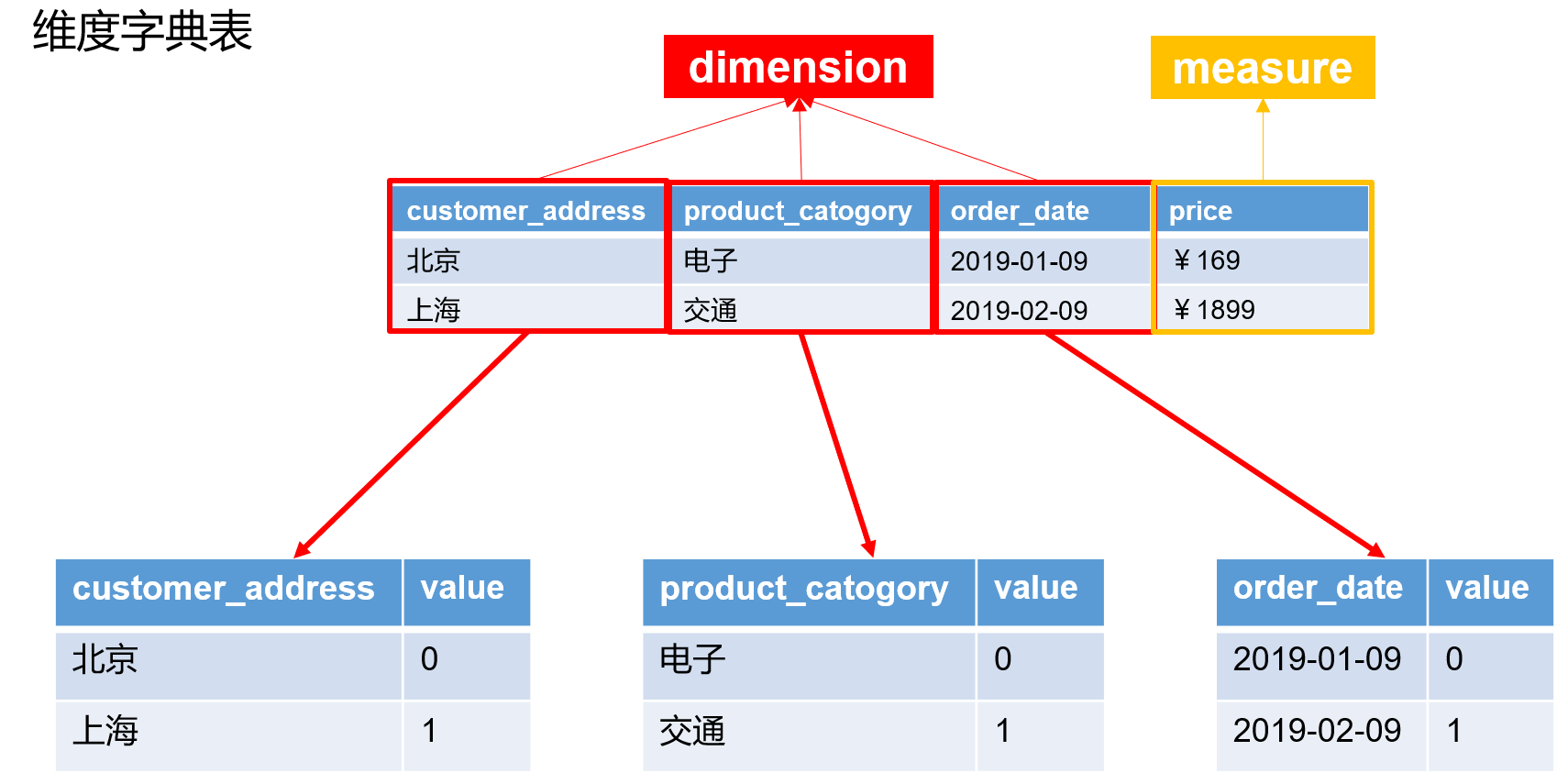
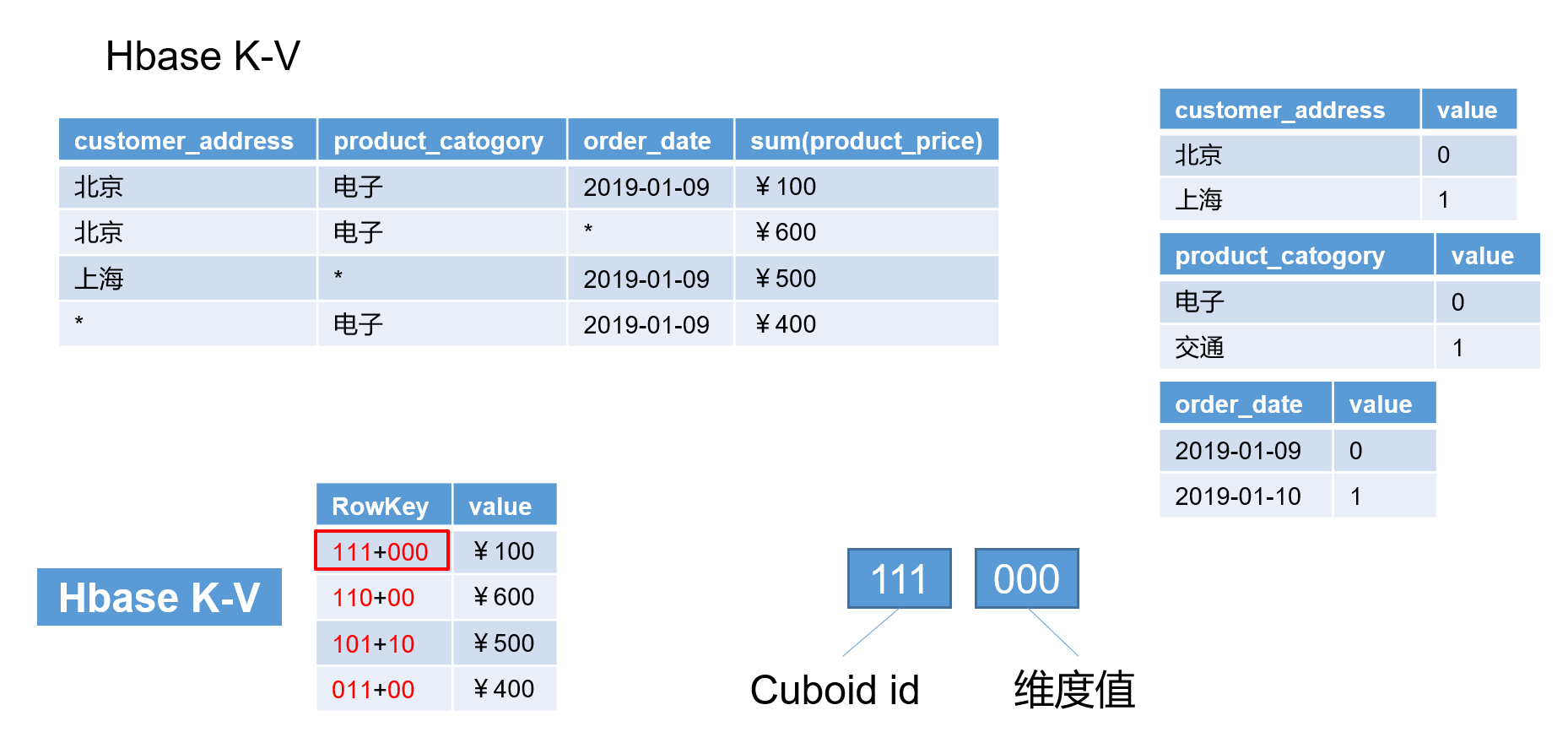
Cube储存原理
Cube构建算法
逐层构建算法(layer)
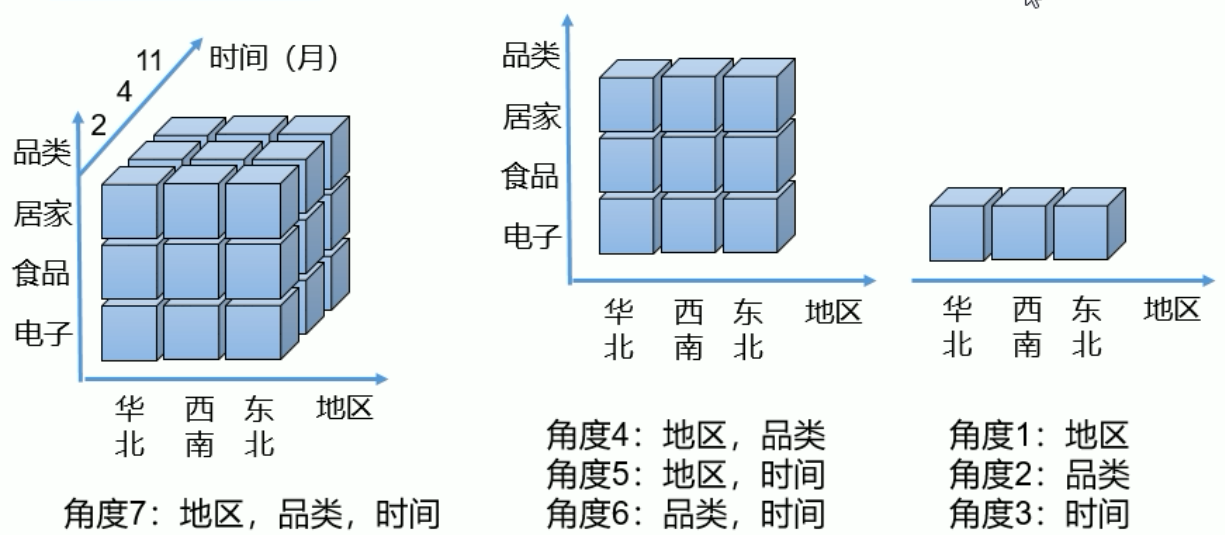
在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
此算法充分利用了MapReduce的优点,处理了中间复杂的排序和shuffle工作,故而算法代码清晰简单,易于维护;
当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候
快速构建算法
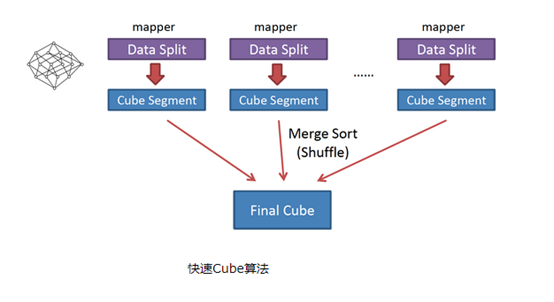
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,该算法的主要思想是,每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(包含所有Cuboid)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。
03Kylin构建原理
https://jiajun.xyz/2020/11/16/bigdata/09Kylin/03Kylin构建原理/