01spark概述
本文最后更新于 2021-08-05 11:42:59
Spark概述
什么是spark
spark是一个快速(基于内存),通用,可扩展的集群计算引擎
spark特点
快速
与 Hadoop 的 MapReduce 相比, Spark 基于内存的运算是 MapReduce 的 100 倍.基于硬盘的运算也要快 10 倍以上.
Spark 实现了高效的 DAG 执行引擎, 可以通过基于内存来高效处理数据流
易用
Spark 支持 Scala, Java, Python, R 和 SQL 脚本, 并提供了超过 80 种高性能的算法, 非常容易创建并行 App
而且 Spark 支持交互式的 Python 和 Scala 的 shell, 这意味着可以非常方便地在这些 shell 中使用 Spark 集群来验证解决问题的方法, 而不是像以前一样 需要打包, 上传集群, 验证等. 这对于原型开发非常重要.
通用
Spark 结合了SQL, Streaming和复杂分析.
Spark 提供了大量的类库, 包括 SQL 和 DataFrames, 机器学习(MLlib), 图计算(GraphicX), 实时流处理(Spark Streaming) .
可以把这些类库无缝的柔和在一个 App 中.
减少了开发和维护的人力成本以及部署平台的物力成本
可融合性
Spark 可以非常方便的与其他开源产品进行融合.
比如, Spark 可以使用 Hadoop 的 YARN 和 Appache Mesos 作为它的资源管理和调度器, 并且可以处理所有 Hadoop 支持的数据, 包括 HDFS, HBase等
Spark 内置模块介绍
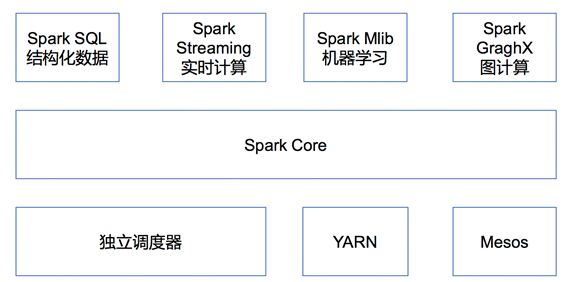
集群管理器(Cluster Manager)
Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(Cluster Manager)上运行,目前 Spark 支持 4种集群管理器:
Hadoop YARN(在国内使用最广泛)
Apache Mesos(国内使用较少, 国外使用较多)
Standalone(Spark 自带的资源调度器, 需要在集群中的每台节点上配置 Spark)
spark2.3后支持 k8s
SparkCore
实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。SparkCore 中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义
Spark SQL
是 Spark 用来操作结构化数据的程序包。通过SparkSql,我们可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等
Spark Streaming
是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib
提供常见的机器学习 (ML) 功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
概念
Master
Spark 特有资源调度系统的 Leader。掌管着整个集群的资源信息,类似于 Yarn 框架中的 ResourceManager
- 监听 Worker,看 Worker 是否正常工作;
- Master 对 Worker、Application 等的管理(接收 Worker 的注册并管理所有的Worker,接收 Client 提交的 Application,调度等待的 Application 并向Worker 提交)。
Worker
Spark 特有资源调度系统的 Slave,有多个。每个 Slave 掌管着所在节点的资源信息,类似于 Yarn 框架中的 NodeManager
- 通过 RegisterWorker 注册到 Master;
- 定时发送心跳给 Master;
- 根据 Master 发送的 Application 配置进程环境,并启动 ExecutorBackend(执行 Task 所需的临时进程)
driver program(驱动程序)
每个 Spark 应用程序都包含一个驱动程序, 驱动程序负责把并行操作发布到集群上.
驱动程序包含 Spark 应用程序中的主函数, 定义了分布式数据集以应用在集群中
executor(执行器)
SparkContext对象一旦成功连接到集群管理器, 就可以获取到集群中每个节点上的执行器(executor).
执行器是一个进程(进程名: ExecutorBackend, 运行在 Worker 节点上), 用来执行计算和为应用程序存储数据.
然后, Spark 会发送应用程序代码(比如:jar包)到每个执行器. 最后, SparkContext对象发送任务到执行器开始执行程序.
RDDs(Resilient Distributed Dataset) 弹性分布式数据集
一旦拥有了SparkContext对象, 就可以使用它来创建 RDD 了. 在前面的例子中, 我们调用sc.textFile(…)来创建了一个 RDD, 表示文件中的每一行文本. 我们可以对这些文本行运行各种各样的操作.
cluster managers(集群管理器)
为了在一个 Spark 集群上运行计算, SparkContext对象可以连接到几种集群管理器(Spark’s own standalone cluster manager, Mesos or YARN).
集群管理器负责跨应用程序分配资源.