10RDD持久化
本文最后更新于 2021-08-05 11:42:59
RDD持久化
每碰到一个 Action 就会产生一个 job, 每个 job 开始计算的时候总是从这个 job 最开始的 RDD 开始计算.
object CacheDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array("ab", "bc"))
val rdd2 = rdd1.flatMap(x => {
println("flatMap...")
x.split("")
})
val rdd3: RDD[(String, Int)] = rdd2.map(x => {
(x, 1)
})
rdd3.collect.foreach(println)
println("-----------")
rdd3.collect.foreach(println)
}
}
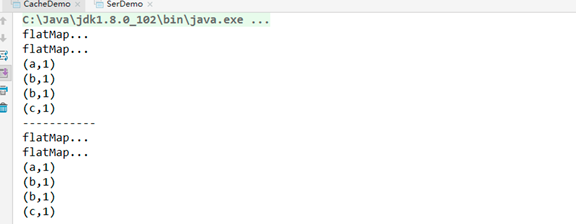
每调用一次 collect, 都会创建一个新的 job, 每个 job 总是从它血缘的起始开始计算. 所以, 会发现中间的这些计算过程都会重复的执行.
原因是因为 rdd记录了整个计算过程. 如果计算的过程中出现哪个分区的数据损坏或丢失, 则可以从头开始计算来达到容错的目的.
可以使用方法persist()或者cache()来持久化一个 RDD. 在第一个 action 会计算这个 RDD, 然后把结果的存储到他的节点的内存中. Spark 的 Cache 也是容错: 如果 RDD 的任何一个分区的数据丢失了, Spark 会自动的重新计算.
RDD 的各个 Partition 是相对独立的, 因此只需要计算丢失的部分即可, 并不需要重算全部 Partition
另外, 允许我们对持久化的 RDD 使用不同的存储级别.
可以给persist()来传递存储级别. cache()方法是使用默认存储级别(StorageLevel.MEMORY_ONLY)的简写方法.

即使我们不手动设置持久化, Spark 也会自动的对一些 shuffle 操作的中间数据做持久化操作(比如: reduceByKey). 这样做的目的是为了当一个节点 shuffle 失败了避免重新计算整个输入
缓存计划要在action操作前
CheckPoint
Spark 中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过 Lineage 做容错的辅助
Lineage 过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的 RDD 开始重做 Lineage,就会减少开销。
当前 RDD 设置检查点。该函数将会创建一个二进制的文件,并存储到 checkpoint 目录中,该目录是用 SparkContext.setCheckpointDir()设置的。在 checkpoint 的过程中,该RDD 的所有依赖于父 RDD中 的信息将全部被移除。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发, 在触发的时候需要对这个 RDD 重新计算.
持久化和checkpoint的区别
持久化只是将数据保存在 BlockManager 中,而 RDD 的 Lineage 是不变的。但是checkpoint 执行完后,RDD 已经没有之前所谓的依赖 RDD 了,而只有一个强行为其设置的checkpointRDD,RDD 的 Lineage 改变了。
持久化的数据丢失可能性更大,磁盘、内存都可能会存在数据丢失的情况。但是 checkpoint 的数据通常是存储在如 HDFS 等容错、高可用的文件系统,数据丢失可能性较小。
注意: 默认情况下,如果某个 RDD 没有持久化,但是设置了checkpoint,会存在问题. 本来这个 job 都执行结束了,但是由于中间 RDD 没有持久化,checkpoint job 想要将 RDD 的数据写入外部文件系统的话,需要启动一个新的job全部重新计算一次,再将计算出来的 RDD 数据 checkpoint到外部文件系统。 所以,建议对 checkpoint()的 RDD 使用持久化, 这样 RDD 只需要计算一次就可以了.
val conf = new SparkConf().setAppName("CacheDemo").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setCheckpointDir("./")
val rdd1 = sc.parallelize(Array("ab", "bc"))
val rdd2 = rdd1.flatMap(x => {
println("flatMap...")
x.split("")
})
val rdd3 = rdd2.map(x => {
println("map...")
(x, 1)
})
rdd3.checkpoint()
rdd3.cache()
rdd3.collect.foreach(println)
println("-----------")
rdd3.collect.foreach(println)
/**
flatMap...
map...
flatMap...
map...
map...
map...
(a,1)
(b,1)
(b,1)
(c,1)
-----------
(a,1)
(b,1)
(b,1)
(c,1)
**/