15SparkSql数据源
本文最后更新于 2021-08-05 11:42:59
SparkSql数据源
读
通用方法
format默认parquet
spark.read.format("json").load("examples/src/main/resources/people.json")专用读法
spark.read.json("examples/src/main/resources/people.json")直接在文件上执行sql
spark.sql("select * from json.`examples/src/main/resources/people.json`")从jdbc读
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop201:3306/rdd")
.option("user", "root")
.option("password", "aaa")
.option("dbtable", "user")
.load()
jdbcDF.show
////////////////////////
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "aaa")
val df: DataFrame = spark.read.jdbc("jdbc:mysql://hadoop201:3306/rdd", "user", props)
写
通用写法
df.write.format("json").save("./writeDemo1")
df.write.mode(SaveMode.ErrorIfExists).format("json").save("./writeDemo1")专用写法
df.write.mode(SaveMode.ErrorIfExists).json("./writeDemo1")
df.write.saveAsTable("tableName") //保存到hive表中,表可以不存在写到jdbc
val ds: Dataset[User1] = rdd.toDS
ds.write
.format("jdbc")
.option("url", "jdbc:mysql://hadoop201:3306/rdd")
.option("user", "root")
.option("password", "aaa")
.option("dbtable", "user")
.mode(SaveMode.Append)
.save()
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "aaa")
ds.write.mode(SaveMode.Append).jdbc("jdbc:mysql://hadoop201:3306/rdd", "user", props)
SaveMode
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | “error”(default) | 如果文件已经存在则抛出异常 |
| SaveMode.Append | “append” | 如果文件已经存在则追加 |
| SaveMode.Overwrite | “overwrite” | 如果文件已经存在则覆盖 |
| SaveMode.Ignore | “ignore” | 如果文件已经存在则忽略 |
Hive读写
两个概念
Hive on Spark:hive默认在mr上跑,可改成在spark内存上跑(hive on mr,hive on tez)
Spark on hive:不管如何运行spark sql,默认读取的hive数据库,其实spark不是直接读取hive数据库,而是读取hive元数据和hdfs,那就是要配置hive的metastore。
Spark on hive 3中方式
内嵌模式
hive服务和metastore服务运行在同一个进程中,derby服务也运行在该进程中。
本地模式
hive服务和metastore服务运行在同一个进程中,mysql是单独的进程,可以在同一台机器上,也可以在远程机器上。
该模式只需将hive-site.xml中的ConnectionURL指向mysql,并配置好驱动名、数据库连接账号(hive中的拷贝过来)
需要将 MySQL 的驱动 jar 包拷贝到$HIVE_HOME/lib目录下, 并启动 MySQL 服务
远程模式
hive服务和metastore在不同的进程内,可能是不同的机器。该模式需要将hive.metastore.local设置为false(在hive2.3中该配置被移除,只指定uris即可),并将hive.metastore.uris设置为metastore服务器URI,如有多个metastore服务器,URI之间用逗号分隔。metastore服务器URI的格式为thrift://hostport
远程模式与本地模式的区分,就是hive服务和metastore服务是否在同一进程,即使在同一台机器也可配置远程模式。
Metastore启动命令
hive –service metastore -p
可以用命令ps -ef|grep metastore查看进程是否启动
如果不加端口默认启动:hive –service metastore,则默认监听9083
hiveServer2+beeline
sbin/start-thriftserver.sh \
--master yarn \
--hiveconf hive.server2.thrift.bind.host=hadoop201 \
-–hiveconf hive.server2.thrift.port=10000 \启动beeline客户端
bin/beeline
!connect jdbc:hive2://hadoop201:10000idea中读写hive
- sparkSession.enableHiveSupport
- 添加hive依赖
- hive-site.xml
写入数据
- 方案一:指定warehouse,不然默认本地
- 方案二:使用df.write.saveAsTable(“TableName”)
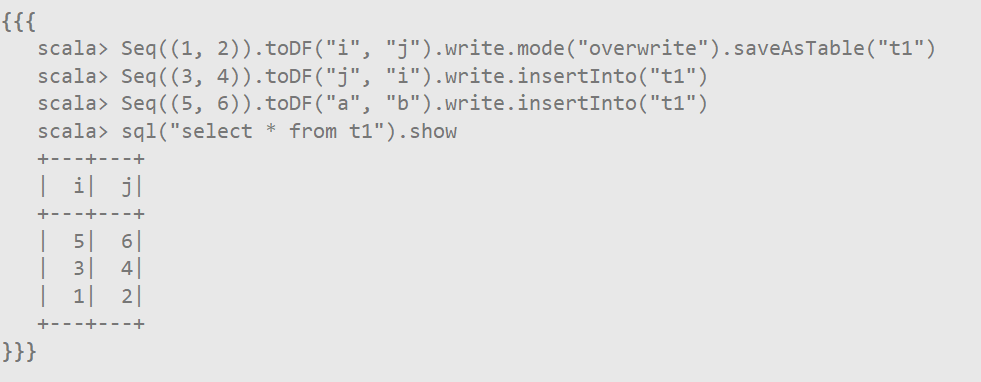
- 方案三:使用df.write.insertInto(“TableName”)
saveAsTable按照列名保存,insertInto按照位置保存