16SparkStreaming
本文最后更新于 2021-08-05 11:42:59
SparkStreaming
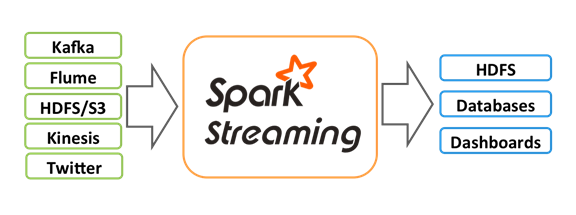
Spark Streaming 是 Spark 核心 API 的扩展, 用于构建弹性, 高吞吐量, 容错的在线数据流的流式处理程序. 总之一句话: Spark Streaming 用于流式数据的处理
数据可以来源于多种数据源: Kafka, Flume, Kinesis, 或者 TCP 套接字. 接收到的数据可以使用 Spark 的负责元语来处理, 尤其是那些高阶函数像: map, reduce, join, 和window.
最终, 被处理的数据可以发布到 FS, 数据库或者在线dashboards.
另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合.
Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
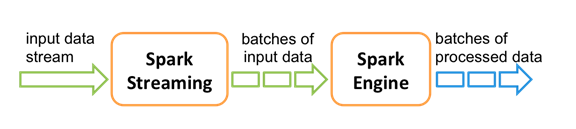
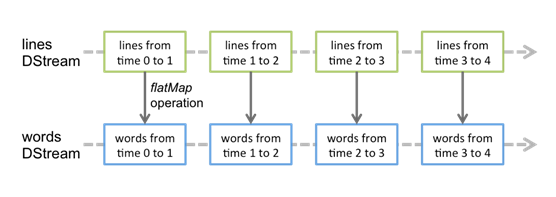
Spark Streaming 提供了一个高级抽象: discretized stream(SStream), DStream 表示一个连续的数据流.
DStream 可以由来自数据源的输入数据流来创建, 也可以通过在其他的 DStream 上应用一些高阶操作来得到.
在内部, 一个 DSteam 是由一个个 RDD 序列来表示的
Spark Streaming 是一种“微量批处理”架构, 和其他基于“一次处理一条记录”架构的系统相比, 它的延迟会相对高一些.
架构
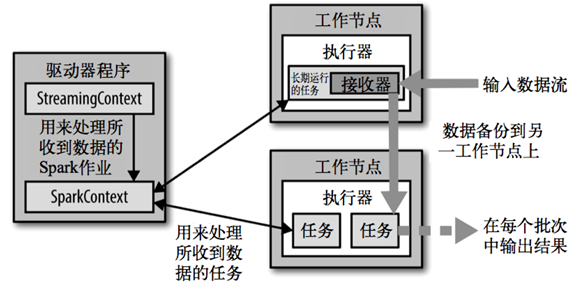
背压机制
Spark 1.5以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数spark.streaming.receiver.maxRate的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure): 根据 JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
通过属性spark.streaming.backpressure.enabled来控制是否启用backpressure机制,默认值false,即不启用。
wordCount
使用 netcat 工具向 9999 端口不断的发送数据,通过 Spark Streaming 读取端口数据并统计不同单词出现的次数
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>object StreamingWordCount {
def main(args: Array[String]): Unit = {
//创建StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("streamWordCount")
val sc = new StreamingContext(conf,Seconds(3))
//从数据源创建一个流
val stream = sc.socketTextStream("node1",9999)
//转换
val result = stream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//行动算子
result.print()
//启动
sc.start()
//阻值主线程退出
sc.awaitTermination()
}
}nc -lk 9999
- 一旦StreamingContext已经启动, 则不能再添加添加新的 streaming computations
- 一旦一个StreamingContext已经停止(StreamingContext.stop()), 他也不能再重启
- 在一个 JVM 内, 同一时间只能启动一个StreamingContext
- stop() 的方式停止StreamingContext, 也会把SparkContext停掉. 如果仅仅想停止StreamingContext, 则应该这样: stop(false)
- 一个SparkContext可以重用去创建多个StreamingContext, 前提是以前的StreamingContext已经停掉,并且SparkContext没有被停掉
- 每次处理一个RDD里面的数据,如果超时,下一个RDD的batchDuration就是(batchDuration-超时时间),平均来说还是保持在同一个batchDuration。
wordCount—->queueStream
仅作测试
object RDDQueueDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDDQueueDemo").setMaster("local[*]")
val scc = new StreamingContext(conf, Seconds(5))
val sc = scc.sparkContext
// 创建一个可变队列
val queue: mutable.Queue[RDD[Int]] = mutable.Queue[RDD[Int]]()
val rddDS: InputDStream[Int] = scc.queueStream(queue, true)
rddDS.reduce(_ + _).print
scc.start
// 循环的方式向队列中添加 RDD
for (elem <- 1 to 5) {
queue += sc.parallelize(1 to 100)
Thread.sleep(2000)
}
scc.awaitTermination()
}
}