19转换&窗口
本文最后更新于 2021-08-05 11:42:59
转换&窗口
转换
transform
不带状态,RDD之间没有联系
可以把Dstream的操作转换为 RDD操作
适用于 需要使用RDD的算子而Dstream中没有
类似于 forEachRDD(rdd=>{}),但是foreachRDD是行动算子(常用于把数据写出到外部系统),transform为转换算子。
def main(args: Array[String]): Unit = {
//创建StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("streamWordCount")
val sc = new StreamingContext(conf,Seconds(3))
//从数据源创建一个流
val stream = sc.socketTextStream("node1",9999)
//转换为rdd
//
val value = stream.transform(rdd => {
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
})
value.print()
//启动
sc.start()
//阻值主线程退出
sc.awaitTermination()
}updateStateBykey
带状态,实现所有周期结果累计
必须有checkpoint
def main(args: Array[String]): Unit = {
//创建StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("streamWordCount")
val sc = new StreamingContext(conf,Seconds(3))
//从数据源创建一个流
val stream = sc.socketTextStream("node1",9999)
//需要checkpoint才能带状态
sc.checkpoint("check")
//带状态updateStateByKey
//seq :本批次rdd value集合
//option:历史数据
stream.flatMap(_.split(" ")).map((_,1)).updateStateByKey((seq:Seq[Int],opt:Option[Int])=>{
Some(seq.sum+opt.getOrElse(0))
}).print
//启动
sc.start()
//阻值主线程退出
sc.awaitTermination()
}Window
reduceByKeyAndWindow
Spark Streaming 也提供了窗口计算, 允许执行转换操作作用在一个窗口内的数据.
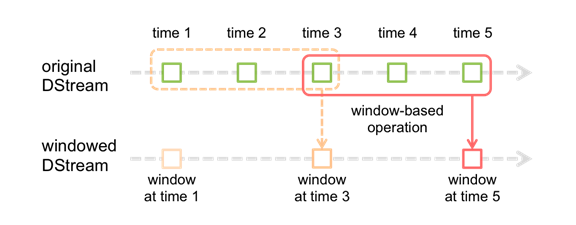
窗口在 DStream 上每滑动一次, 落在窗口内的那些 RDD会结合在一起, 然后在上面操作产生新的 RDD, 组成了 window DStream.
窗口时间和步长必须是一个批次的整数倍
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration
): DStream[(K, V)]
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration
): DStream[(K, V)]
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int
): DStream[(K, V)]
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner
): DStream[(K, V)]def main(args: Array[String]): Unit = {
//创建StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("streamWordCount")
val sc = new StreamingContext(conf,Seconds(3))
//从数据源创建一个流
val stream = sc.socketTextStream("node1",9999)
val value = stream.flatMap(_.split(" ")).map((_, 1)).reduceByKeyAndWindow(_ + _, Seconds(12),Seconds(6))
value.print()
//启动
sc.start()
//阻值主线程退出
sc.awaitTermination()
}优化计算 reduceByKeyAndWindow
减少窗口滑动过程中的重复计算,上一个窗口和新的窗口会有重叠部分, 重叠部分的值可以不用重复计算了. 第一个参数就是新的值, 第二个参数是旧的值. newWindow = oldWindow+(newIn-oldOut)
要有checkPoint
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration = self.slideDuration,
numPartitions: Int = ssc.sc.defaultParallelism,
filterFunc: ((K, V)) => Boolean = null
): DStream[(K, V)]
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner,
filterFunc: ((K, V)) => Boolean
): DStream[(K, V)]val value = stream
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKeyAndWindow(_ + _, _-_,Seconds(12),Seconds(6))
.printwindow
基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream
def window(windowDuration: Duration, slideDuration: Duration): DStream[T]countByWindow
返回一个滑动窗口计数流中的元素的个数。
def countByWindow(
windowDuration: Duration,
slideDuration: Duration): DStream[Long]countByValueAndWindow
对(K,V)对的DStream调用,返回(K,Long)对的新DStream,其中每个key的的对象的v是其在滑动窗口中频率
def countByValueAndWindow(
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int = ssc.sc.defaultParallelism)
(implicit ord: Ordering[T] = null)
: DStream[(T, Long)]19转换&窗口
https://jiajun.xyz/2021/07/24/bigdata/10spark/19转换&窗口/