10状态编程
本文最后更新于 2022-08-28 11:30:56
状态编程
状态概念
无状态:每一个事件都是独立的,互相不影响
有状态:多个事件之间可以有联系
在function里面自己也能实现这样的状态保存,但是flink提供的能够支持故障恢复
状态分类
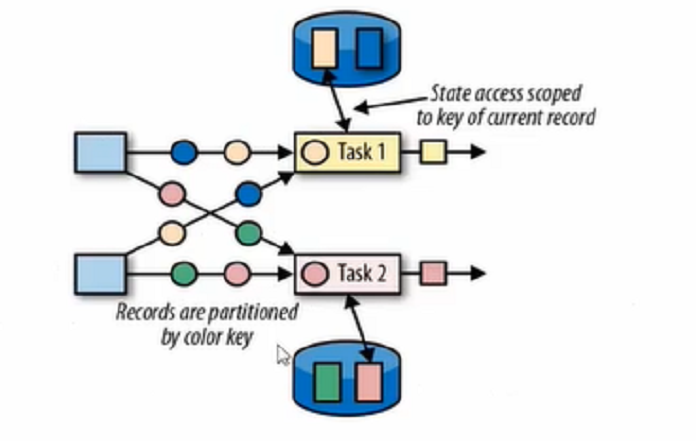
键控状态
必须要在keyBy后使用,每个key都维护一个(局部变量和counter都是一个算子(subTask)维护一个)
键控状态数据结构
- 值状态(Value state): 将状态表示为单个的值。
- 列表状态(list state): 将状态表示为一组数据的列表。
- 映射状态(Map state): 将状态表示为一组key-value对。
- 聚合状态(Reducing state & aggregating State): 将状态表示为一个用于聚合操作的列表。
横向扩展问题
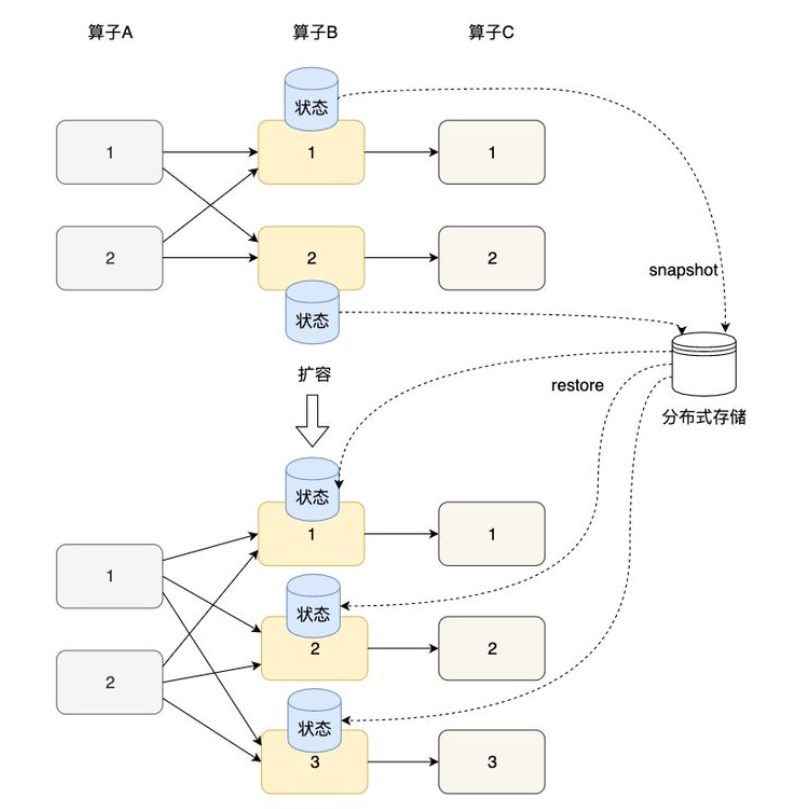
状态的横向扩展问题主要是指修改Flink应用的并行度,确切的说,每个算子的并行实例数或算子子任务数发生了变化,应用需要关停或启动一些算子子任务,某份在原来某个算子子任务上的状态数据需要平滑更新到新的算子子任务上。其实,Flink的Checkpoint就是一个非常好的在各算子间迁移状态数据的机制。算子的本地状态将数据生成快照(snapshot),保存到分布式存储(如HDFS)上。横向伸缩后,算子子任务个数变化,子任务重启,相应的状态从分布式存储上重建(restore)。
算子状态
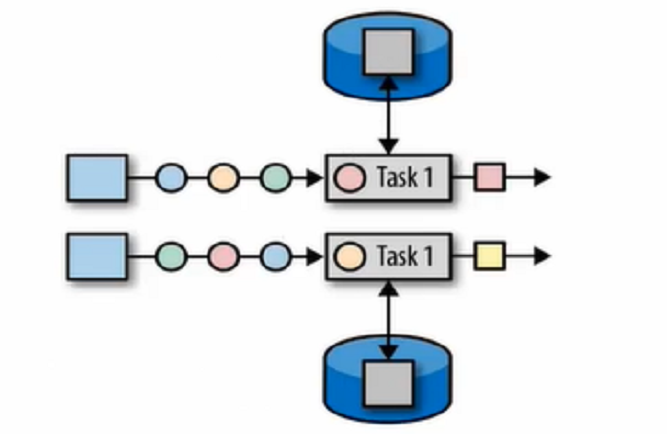
和算子绑定的,算子的状态的访问权限是此算子处理的所有数据。一个算子一个状态。并行度增加,算子就增加,状态就增加
算子状态数据结构
- 列表状态(List State): 将状态表示为一组数据的列表。
- 联合列表状态(Union list state): 也将状态表示为数据的列表,它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
- 广播状态(Broadcast state): 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
键控状态的使用
在open里面获取(因为RuntimeContext和state生命周期影响)
class MyRichMapFunction extends RichMapFunction[(String, Int), (String, Int)] {
var state: ValueState[Int] = _;
override def open(parameters: Configuration): Unit = {
state = getRuntimeContext.getState[Int](new ValueStateDescriptor("state", classOf[Int]))
//不能update这里
}
override def map(value: (String, Int)): (String, Int) = {
state.update(if (state.value() == null) 0 else state.value() + 1)
(value._1, state.value())
}
}使用scala lazy特性(因为RuntimeContext和state生命周期影响)
class MyRichMapFunction extends RichMapFunction[(String, Int), (String, Int)] {
lazy val state: ValueState[Int] = getRuntimeContext.getState[Int](new ValueStateDescriptor("state", classOf[Int]))
override def map(value: (String, Int)): (String, Int) = {
state.update(if (state.value() == null) 0 else state.value() + 1)
(value._1, state.value())
}
}使用带状态的函数
//mapWithState
def mapWithState[R: TypeInformation, S: TypeInformation](
fun: (T, Option[S]) => (R, Option[S])): DataStream[R]
//filterWithState
def filterWithState[S : TypeInformation](
fun: (T, Option[S]) => (Boolean, Option[S])): DataStream[T]
//flatMapWithState
def flatMapWithState[R: TypeInformation, S: TypeInformation](
fun: (T, Option[S]) => (TraversableOnce[R], Option[S])): DataStream[R]
stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(_._1)
.mapWithState[(String, Int, Int), Int]({
case ((key, count), state) => ((key, count, state.getOrElse(0) + 1), Some(state.getOrElse(0) + 1))
})
.print()算子状态的使用
ListState和UnionListState在数据结构上都是一种ListState
ListState以一个列表的形式序列化并存储,以适应横向扩展时状态重分布的问题。
每个算子子任务有零到多个状态S,组成一个列表ListState[S]。各个算子子任务将自己状态列表的snapshot到存储,整个状态逻辑上可以理解成是将这些列表连接到一起,组成了一个包含所有状态的大列表。当作业重启或横向扩展时,我们需要将这个包含所有状态的列表重新分布到各个算子子任务上。
ListState和UnionListState的区别在于:ListState是将整个状态列表按照round-robin的模式均匀分布到各个算子子任务上,每个算子子任务得到的是整个列表的子集;UnionListState按照广播的模式,将整个列表发送给每个算子子任务。
Operator State的实际应用场景不如Keyed State多,它经常被用在Source或Sink等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证Flink应用的Exactly-Once语义。
方式1 实现CheckpointedFunction
public interface CheckpointedFunction {
// Checkpoint时会调用这个方法,我们要实现具体的snapshot逻辑,比如将哪些本地状态持久化
//在Flink的Checkpoint机制下,当一次snapshot触发后,snapshotState会被调用,将本地状态持久化到存储空间上。
void snapshotState(FunctionSnapshotContext context) throws Exception;
// 初始化时会调用这个方法,向本地状态中填充数据
//initializeState在算子子任务初始化时被调用,初始化包括两种场景:
//一、整个Flink作业第一次执行,状态数据被初始化为一个默认值;
//二、Flink作业重启,之前的作业已经将状态输出到存储,通过这个方法将存储上的状态读出并填充到这个本地状态中。
void initializeState(FunctionInitializationContext context) throws Exception;
}// BufferingSink需要继承SinkFunction以实现其Sink功能,同时也要继承CheckpointedFunction接口类
class BufferingSink(threshold: Int = 0)
extends SinkFunction[(String, Int)]
with CheckpointedFunction {
// Operator List State句柄
@transient
private var checkpointedState: ListState[(String, Int)] = _
// 本地缓存
private val bufferedElements = ListBuffer[(String, Int)]()
// Sink的核心处理逻辑,将上游数据value输出到外部系统
override def invoke(value: (String, Int), context: Context): Unit = {
// 先将上游数据缓存到本地的缓存
bufferedElements += value
// 当本地缓存大小到达阈值时,将本地缓存输出到外部系统
if (bufferedElements.size == threshold) {
for (element <- bufferedElements) {
// send it to the sink
}
// 清空本地缓存
bufferedElements.clear()
}
}
// 重写CheckpointedFunction中的snapshotState
// 将本地缓存snapshot保存到存储上
override def snapshotState(context: FunctionSnapshotContext): Unit = {
// 将之前的Checkpoint清理
checkpointedState.clear()
// 将最新的数据写到状态中
for (element <- bufferedElements) {
checkpointedState.add(element)
}
}
// 重写CheckpointedFunction中的initializeState
// 初始化状态
override def initializeState(context: FunctionInitializationContext): Unit = {
// 注册ListStateDescriptor
val descriptor = new ListStateDescriptor[(String, Int)](
"buffered-elements",
TypeInformation.of(new TypeHint[(String, Int)]() {})
)
// 从FunctionInitializationContext中获取OperatorStateStore,进而获取ListState
checkpointedState = context.getOperatorStateStore.getListState(descriptor)
// 如果是作业重启,读取存储中的状态数据并填充到本地缓存中
if(context.isRestored) {
for(element <- checkpointedState.get()) {
bufferedElements += element
}
}
}
}输出到Sink之前,先将数据放在本地缓存中,并定期进行snapshot,这实现了批量输出的功能,批量输出能够减少网络等开销。同时,程序能够保证数据一定会输出外部系统,因为即使程序崩溃,状态中存储着还未输出的数据,下次启动后还会将这些未输出数据读取到内存,继续输出到外部系统。
注册和使用Operator State的代码和Keyed State相似,也是先注册一个StateDescriptor,并指定状态名字和数据类型,然后从FunctionInitializationContext中获取OperatorStateStore,进而获取ListState。如果是UnionListState,那么代码改为:context.getOperatorStateStore.getUnionListState。
状态的初始化逻辑中,我们用context.isRestored来判断是否为作业重启,这样可以从之前的Checkpoint中恢复并写到本地缓存中。
CheckpointedFunction接口类的initializeState方法的参数为FunctionInitializationContext,基于这个上下文参数我们不仅可以通过getOperatorStateStore获取OperatorStateStore,也可以通过getKeyedStateStore来获取KeyedStateStore,进而通过getState、getMapState等方法获取Keyed State,比如:context.getKeyedStateStore().getState(valueDescriptor)。这与在Rich函数类中使用Keyed State的方式并不矛盾。CheckpointedFunction是Flink有状态计算的最底层接口,它提供了最丰富的状态接口。
ListCheckpointed接口类是CheckpointedFunction接口类的一种简写,ListCheckpointed提供的功能有限,只支持均匀分布的ListState,不支持全量广播的UnionListState。
public interface ListCheckpointed<T extends Serializable> {
// Checkpoint时会调用这个方法,我们要实现具体的snapshot逻辑,比如将哪些本地状态持久化
//这里的snapshotState也是在做备份,但这里的参数列表更加精简,其中checkpointId是一个单调递增的数字,用来表示某次Checkpoint,timestamp是Checkpoint发生的实际时间,这个方法以列表形式返回需要写入存储的状态
List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
// 从上次Checkpoint中恢复数据到本地内存
//restoreState方法用来初始化状态,包括作业第一次启动或者作业失败重启。参数是一个列表形式的状态,是均匀分布给这个算子子任务的状态数据。
void restoreState(List<T> state) throws Exception;
}