09checkpoint
本文最后更新于 2022-08-28 11:30:56
Checkpoint
状态后端(State Backend)
用Data Stream Api 编写的程序经常是需要保存状态的,如下面情况:
- Windows中聚集的元素直到被触发计算。在触发之前,需要保存Windows中的元素的状态。
- 转换(Transformation)函数可以使用Key/Value状态接口存储状态值
- 转换(Transformation)函数可以实现Checkpointed Function接口使局部变量具有容错能
Flink提供不同的状态后端(State Backend)来区分状态的存储方式和存储位置。
状态后端种类
MemoryStateBackend
State存储在Memory(内存)中。适用于本地调试或数据量较小的场景。
MemoryStateBackend将State作为Java对象保存(在堆内存),存储着key/value状态、window运算符、触发器等的哈希表。
在Checkpoint时,State Backend将对State进行快照,并将其作为checkpoint发送到JobManager机器上,JobManager将这个State数据存储在Java堆内存。
MemoryStateBackend默认使用异步快照,来避免阻塞管道。如果需要修改,可以在MemoryStateBackend的构造函数将布尔值改为false
MemoryStateBackend的局限
- 默认情况下,每个State大小限制不超过5MB,可以在
MemoryStateBackend构造函数增加值 - 无论最大的State大小如何配置,但都不能超过Akka的传输最大消息大小(10MB)
- State状态存储在
JobManager的内存当中
FsStateBackend
使用可靠地文件存储系统State,如HDFS。适用于具有大状态、长窗口大键值的高可用作业。
FsStateBackend将正在运行的数据保存在TaskManager的内存中。在checkpoint时,它将State的快照写入文件系统对应的目录下的文件中。最小元数据存储在JobManager的内存中(如果是高可用模式下,元数据存储在checkpoint中),另外FsStateBackend通过配置一个fileStateThreshold阈值,小于该值时state存储到metadata中而非文件中。
FsStateBackend默认使用异步快照,来避免阻塞处理的管道。如果需要禁用,在FsStateBackend构造方法中将布尔值设为false
RocksDBStateBackend
使用RocksDB存储State.适用于具有大状态、长窗口大键值的高可用作业,可以保持非常大的状态,可以实现的最大吞吐量将降低
RocksDBStateBackend将工作状态保存在RocksDB数据库(RocksDB 是一个基于 LSM [ Log Structured Merge Trees ] 实现的 KV 数据库),但是,每个状态访问和更新都需要(反)序列化,并且可能需要从磁盘读取数据,这导致平均性能比内存状态后端慢一个数量级。
由于RocksDBStateBackend将工作状态存储在taskManger的本地文件系统(RocksDB数据库),状态数量仅仅受限于本地磁盘容量限制,对比于FsStateBackend保存工作状态在内存中,RocksDBStateBackend能避免flink任务持续运行可能导致的状态数量暴增而内存不足的情况,因此适合在生产环境使用。
通过checkpoint, 整个RocksDB数据库被复制到配置的文件系统中。最小元数据保存jobManager的内存中(如果是高可用模式下,元数据存储在checkpoint中)。RocksDBStateBackend可以通过enableIncrementalCheckpointing参数配置是否进行增量Checkpoint(而MemoryStateBackend 和 FsStateBackend不能)。
如果使用RocksDB作为状态后端,flink的定时器可以配置储存存储在数据库中。但是如果定时器比较少时,基于堆内存的定时器会获得更好的性能。
RocksDBStateBackend仅支持异步快照(asynchronous snapshots)
需要加入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.12.0</version>
<scope>provided</scope>
</dependency>Flink1.13改动
Flink新版本移除状态后端异步选项,让状态后端只能异步快照,并且统一了savepoint的二进制格式。这样做简化了状态后端,因为MemoryStateBackend和FsStateBackend的状态都存储在内存,而RocksDBStateBackend存储在数据库。FsStateBackend和RocksDBStateBackend都要配置存储路径,可以统一设置路径。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());
//等价于MemoryStateBackend
env.getCheckpointConfig().setCheckpointStorage(new JobManagerStateBackend());
//等价于FsStateBackend
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoints"));
//等价于RocksDBStateBackend,默认全量检查点
env.setStateBackend(new EmbeddedRocksDBStateBackend());
//开启增量检查点
env.setStateBackend(new EmbeddedRocksDBStateBackend(true));
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoints"));
Checkpoint
Flink Checkpoint 是一种容错恢复机制。这种机制保证了实时程序运行时,即使突然遇到异常也能够进行自我恢复。Checkpoint 对于用户层面,是透明的,用户会感觉程序一直在运行。Flink Checkpoint 是 Flink 自身的系统行为,用户无法对其进行交互,用户可以在程序启动之前,设置好实时程序 Checkpoint 相关参数,当程序启动之后,剩下的就全交给 Flink 自行管理。
Checkpoint由JM的Checkpoint Coordinator发起
第一步,Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint;
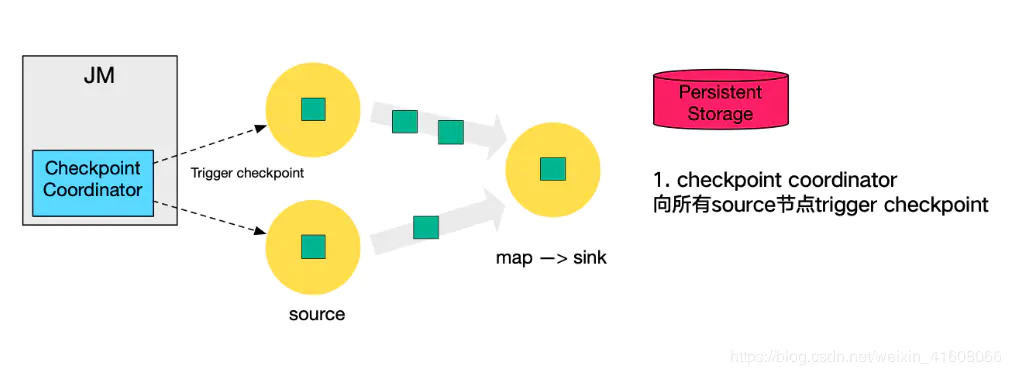
第二步,source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有 input 的 barrier 才会执行相应的 Checkpoint。
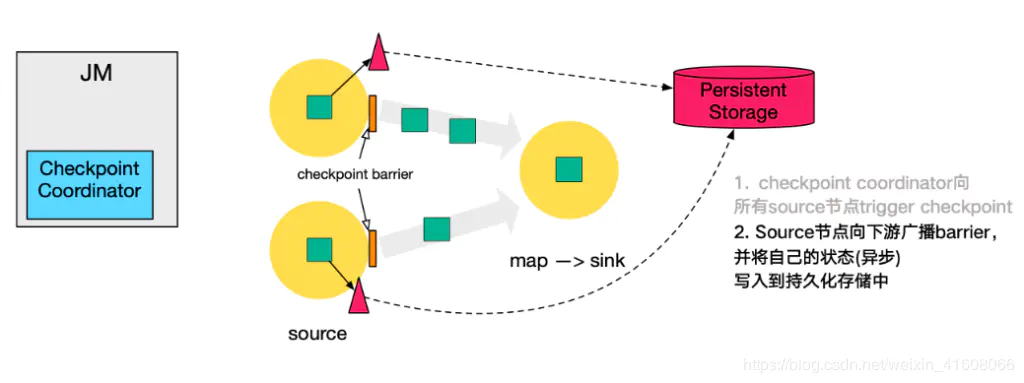
第三步,当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator。
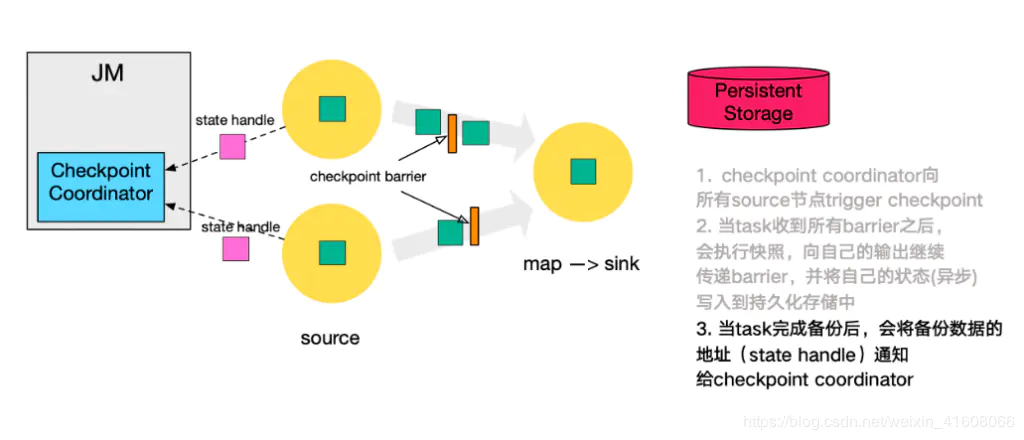
这里分为同步和异步(如果开启的话)两个阶段:
1.同步阶段:task执行状态快照,并写入外部存储系统(根据状态后端的选择不同有所区别)
执行快照的过程:
a.对state做深拷贝。
b.将写操作封装在异步的FutureTask中
FutureTask的作用包括:1)打开输入流2)写入状态的元数据信息3)写入状态4)关闭输入流
2.异步阶段:
1)执行同步阶段创建的FutureTask
2)向Checkpoint Coordinator发送ACK响应
第四步,下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。
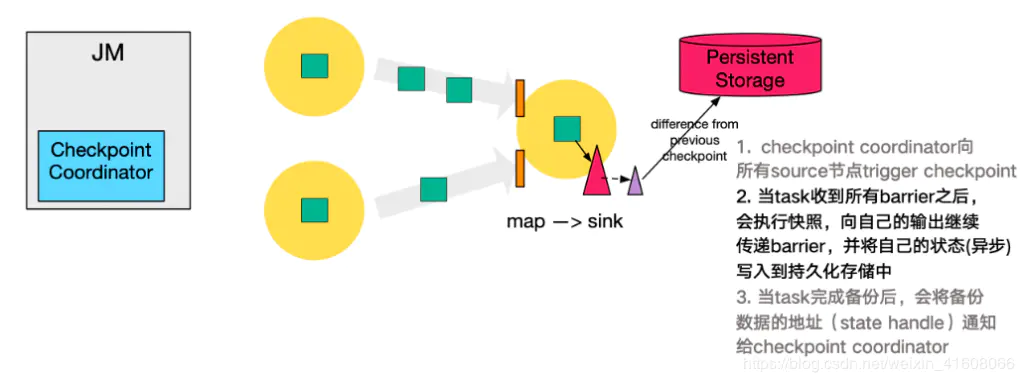
同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator。
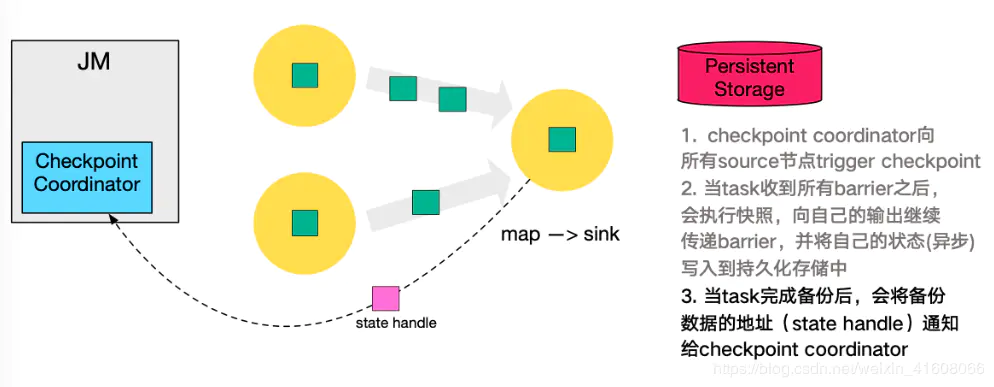
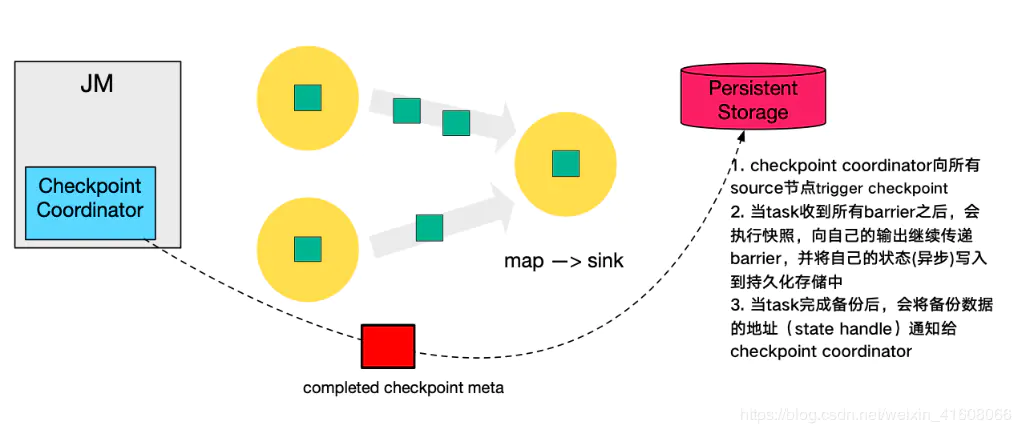
最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
配置
使用StreamExecutionEnvironment.enableCheckpointing方法来设置开启checkpoint;具体可以使用enableCheckpointing(long interval),或者enableCheckpointing(long interval, CheckpointingMode mode);interval用于指定checkpoint的触发间隔(单位milliseconds),而CheckpointingMode默认是CheckpointingMode.EXACTLY_ONCE,也可以指定为CheckpointingMode.AT_LEAST_ONCE ,没有at_most_once
也可以通过StreamExecutionEnvironment.getCheckpointConfig().setCheckpointingMode来设置CheckpointingMode
minPauseBetweenCheckpoints用于指定checkpoint coordinator上一个checkpoint完成之后最小等多久可以出发另一个checkpoint,当指定这个参数时,maxConcurrentCheckpoints的值为1
checkpointTimeout用于指定checkpoint执行的超时时间(单位milliseconds),超时没完成就会被abort掉
maxConcurrentCheckpoints用于指定运行中的checkpoint最多可以有多少个;如果有设置了minPauseBetweenCheckpoints,则maxConcurrentCheckpoints这个参数就不起作用了(大于1的值不起作用)
enableExternalizedCheckpoints用于开启checkpoints的外部持久化,但是在job失败的时候不会自动清理,需要自己手工清理state;ExternalizedCheckpointCleanup用于指定当job canceled的时候externalized checkpoint该如何清理,DELETE_ON_CANCELLATION的话,在job canceled的时候会自动删除externalized state,但是如果是FAILED的状态则会保留;RETAIN_ON_CANCELLATION则在job canceled的时候会保留externalized checkpoint state
failOnCheckpointingErrors用于指定在checkpoint发生异常的时候,是否应该fail该task,默认为true,如果设置为false,则task会拒绝checkpoint然后继续运行
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000);
// advanced options:
// set mode to exactly-once (this is the default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// checkpoints have to complete within one minute, or are discarded
env.getCheckpointConfig().setCheckpointTimeout(60000);
// make sure 500 ms of progress happen between checkpoints
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// enable externalized checkpoints which are retained after job cancellation
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// This determines if a task will be failed if an error occurs in the execution of the task’s checkpoint procedure.
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);Savepoint
在某个时间点程序状态全局镜像,以后程序在进行升级,或者修改并发度等情况,还能从保存的状态位继续启动恢复。Flink Savepoint 一般存储在 HDFS 上面,它需要用户主动进行触发。如果是用户自定义开发的实时程序,比如使用DataStream进行开发,建议为每个算子定义一个 uid,这样我们在修改作业时,即使导致程序拓扑图改变,由于相关算子 uid 没有变,那么这些算子还能够继续使用之前的状态,如果用户没有定义 uid , Flink 会为每个算子自动生成 uid,如果用户修改了程序,可能导致之前的状态程序不能再进行复用。
Savepoint文件会一直保存,除非用户删除
Flink Savepoint 作为实时任务的全局镜像,其在底层使用的代码和Checkpoint的代码是一样的,因为Savepoint可以看做 Checkpoint在特定时期的一个状态快照。
Flink Savepoint 触发方式:
- 使用
flink savepoint命令触发 Savepoint,其是在程序运行期间触发 savepoint, - 使用
flink cancel -s命令,取消作业时,并触发 Savepoint. - 使用 Rest API 触发 Savepoint,格式为:
**/jobs/:jobid /savepoints**