02粘包半包
粘包半包
粘包
- 现象
- 发送 abc def,接收 abcdef
- 原因
- 应用层
- 接收方 ByteBuf 设置太大(Netty 默认 1024)
- 传输层-网络层
- 滑动窗口:假设发送方 256 bytes 表示一个完整报文,但由于接收方处理不及时且窗口大小足够大(大于256 bytes),这 256 bytes 字节就会缓冲在接收方的滑动窗口中,当滑动窗口中缓冲了多个报文就会粘包
- Nagle 算法:会造成粘包
- 应用层
半包
- 现象
- 发送 abcdef,接收 abc def
- 原因
- 应用层
- 接收方 ByteBuf 小于实际发送数据量
- 传输层-网络层
- 滑动窗口:假设接收方的窗口只剩了 128 bytes,发送方的报文大小是 256 bytes,这时接收方窗口中无法容纳发送方的全部报文,发送方只能先发送前 128 bytes,等待 ack 后才能发送剩余部分,这就造成了半包
- 数据链路层
- MSS 限制:当发送的数据超过 MSS 限制后,会将数据切分发送,就会造成半包
- 应用层
Nagle算法与MSS
Nagle算法于1984年定义为福特航空和通信公司IP/TCP拥塞控制方法,这是福特经营的最早的专用TCP/IP网络减少拥塞控制,从那以后这一方法得到了广泛应用。Nagle的文档里定义了处理他所谓的小包问题的方法,这种问题指的是应用程序一次产生一字节数据,这样会导致网络由于太多的包而过载(一个常见的情况是发送端的”糊涂窗口综合症(Silly Window Syndrome)“)。从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的首部数据。这种情况转变成了4000%的消耗
TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
if there is new data to send #有数据要发送
# 发送窗口缓冲区和队列数据 >=mss,队列数据(available data)为原有的队列数据加上新到来的数据
# 也就是说缓冲区数据超过mss大小,nagle算法尽可能发送足够大的数据包
if the window size >= MSS and available data is >= MSS
send complete MSS segment now # 立即发送
else
if there is unconfirmed data still in the pipe # 前一次发送的包没有收到ack
# 将该包数据放入队列中,直到收到一个ack再发送缓冲区数据
enqueue data in the buffer until an acknowledge is received
else
send data immediately # 立即发送
end if
end if
end ifNagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停-等协议,只不过它是基于包停-等的,而不是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低。
TCP_NODELAY 选项
默认情况下,发送数据采用Nagle 算法。这样虽然提高了网络吞吐量,但是实时性却降低了,在一些交互性很强的应用程序来说是不允许的,使用TCP_NODELAY选项可以禁止Nagle 算法。
此时,应用程序向内核递交的每个数据包都会立即发送出去。需要注意的是,虽然禁止了Nagle 算法,但网络的传输仍然受到TCP确认延迟机制的影响。
TCP_CORK 选项
所谓的CORK就是塞子的意思,形象地理解就是用CORK将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核会尽力把小数据包拼接成一个大的数据包(一个MTU)再发送出去,当然若一定时间后(一般为200ms,该值尚待确认),内核仍然没有组合成一个MTU时也必须发送现有的数据(不可能让数据一直等待吧)。
然而,TCP_CORK的实现可能并不像你想象的那么完美,CORK并不会将连接完全塞住。内核其实并不知道应用层到底什么时候会发送第二批数据用于和第一批数据拼接以达到MTU的大小,因此内核会给出一个时间限制,在该时间内没有拼接成一个大包(努力接近MTU)的话,内核就会无条件发送。也就是说若应用层程序发送小包数据的间隔不够短时,TCP_CORK就没有一点作用,反而失去了数据的实时性(每个小包数据都会延时一定时间再发送)。
Nagle算法与CORK算法区别
Nagle算法和CORK算法非常类似,但是它们的着眼点不一样,Nagle算法主要避免网络因为太多的小包(协议头的比例非常之大)而拥塞,而CORK算法则是为了提高网络的利用率,使得总体上协议头占用的比例尽可能的小。如此看来这二者在避免发送小包上是一致的,在用户控制的层面上,Nagle算法完全不受用户socket的控制,你只能简单的设置TCP_NODELAY而禁用它,CORK算法同样也是通过设置或者清除TCP_CORK使能或者禁用之,然而Nagle算法关心的是网络拥塞问题,只要所有的ACK回来则发包,而CORK算法却可以关心内容,在前后数据包发送间隔很短的前提下(很重要,否则内核会帮你将分散的包发出),即使你是分散发送多个小数据包,你也可以通过使能CORK算法将这些内容拼接在一个包内,如果此时用Nagle算法的话,则可能做不到这一点。
Netty解码器
定长解码器
客户端于服务器约定一个最大长度,保证客户端每次发送的数据长度都不会大于该长度。若发送数据长度不足则需要补齐至该长度
服务器接收数据时,将接收到的数据按照约定的最大长度进行拆分,即使发送过程中产生了粘包,也可以通过定长解码器将数据正确地进行拆分。服务端需要用到FixedLengthFrameDecoder对数据进行定长解码
ch.pipeline().addLast(new FixedLengthFrameDecoder(16));行解码器
行解码器的是通过分隔符对数据进行拆分来解决粘包半包问题的
可以通过LineBasedFrameDecoder(int maxLength)来拆分以换行符(\n)为分隔符的数据,也可以通过DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf... delimiters)来指定通过什么分隔符来拆分数据(可以传入多个分隔符)
两种解码器都需要传入数据的最大长度,若超出最大长度,会抛出TooLongFrameException异常
长度解码器
在传送数据时可以在数据中添加一个用于表示有用数据长度的字段,在解码时读取出这个用于表明长度的字段,同时读取其他相关参数,即可知道最终需要的数据是什么样子的
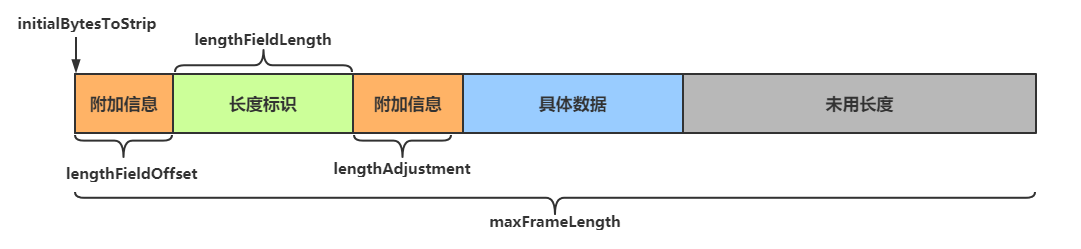
LengthFieldBasedFrameDecoder解码器可以提供更为丰富的拆分方法,其构造方法有五个参数
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip)public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder {
/** 排序枚举 */
private final ByteOrder byteOrder;
/** 数据包最大长度 */
private final int maxFrameLength;
/** 长度域偏移的字节数 */
private final int lengthFieldOffset;
/** 长度域占用的字节数 */
private final int lengthFieldLength;
/** lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength
* 在构造方法中有这个算式
* */
private final int lengthFieldEndOffset;
/** 修正长度域的值 */
private final int lengthAdjustment;
/** 砍掉数据包开头后指定字节数 */
private final int initialBytesToStrip;
/** 数据包长度大于maxFrameLength时是否抛出异常 */
private final boolean failFast;
/** 是否正处于丢弃模式 */
private boolean discardingTooLongFrame;
/** 丢弃的长度 */
private long tooLongFrameLength;
/** 剩余要丢弃的字节 */
private long bytesToDiscard;
...(非属性代码略)
lengthFieldLength
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 0 (= do not strip header)
解码前 (14 bytes) 解码后 (14 bytes)
|2 bytes | 12 bytes | |2 bytes | 12 bytes |
+--------+----------------+ +--------+----------------+
| length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+- lengthFieldLength=2表示长度域的值占2字节,然后解码器获取到前两字节的数据为12,这个12就是初始长度域的值。
- 然后解码器就在再往后读取12个字节,跟前2字节一起组成一个数据包(解码前后无变化)。
initialBytesToStrip
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 2 (= the length of the Length field)
解码前 (14 bytes) 解码后 (12 bytes)
|2 bytes | 12 bytes | | 12 bytes |
+--------+----------------+ +----------------+
| Length | Actual Content |----->| Actual Content |
| 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
+--------+----------------+ +----------------+- lengthFieldLength=2表示长度域的值占2字节,然后解码器获取到前2字节的数据为12,这个12就是初始长度域的值。
- 之后,initialBytesToStrip=2告诉解码器:开头的前2个字节不需要读的。于是,编码器就把readerIndex移动到第2个字节处,也就是把原本读到的HDR1域,和长度域丢掉。
- 终于,编码器可以开始读数据了,从开头的第2字节处往后读了12个字节,即由”HELLO, WORLD”组成的数据包。
lengthAdjustment
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = -2 (= the length of the Length field)
initialBytesToStrip = 0 (= do not strip header)
解码前 (14 bytes) 解码后 (14 bytes)
|2 bytes | 12 bytes | |2 bytes | 12 bytes |
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+- lengthFieldLength=2表示长度域的值占2字节,然后解码器获取到前2字节的数据为14,这个14就是初始长度域的值。
- 如果按照上面的逻辑,那解码器就要往后读取14字节的数据了,可是后面只有12字节啊,这时候lengthAdjustment就派上用场了。
- 要读取的真实字节数=初始长度域值(14)+ lengthAdjustment(-2),然后解码器发现initialBytesToStrip=0,表示不需要丢弃字节,就会往后读”要读取的真实字节数”个字节并和前面读取到的2字节组成数据包。
- 参数意义:当长度域的值表示其它意义时,可以用lengthAdjustment来修正要读取的字节数。
lengthFieldOffset
lengthFieldOffset = 2
lengthFieldLength = 3
lengthAdjustment = 0
initialBytesToStrip = 0 (= do not strip header)
解码前 (17 bytes) 解码后 (17 bytes)
| 2 bytes | 3 bytes | 12 bytes | | 2 bytes | 3 bytes | 12 bytes |
+----------+----------+----------------+ +----------+----------+----------------+
| Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
| 0xC AFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+- 这次又有点不一样了,因为lengthFieldOffset=2,这个参数告诉解码器,长度域的值不是从开头的字节读起了,而是开头字节的后2位开始读起,因为开头的2位是别的数据域,不属于长度域。
- 好了,现在解码器就从第3字节开始往后读3字节,成功拿到了长度域的初始值,也就是12。
- 最后,发现lengthAdjustment、initialBytesToStrip都=0,则不需要额外操作,往后读12字节再加上前面读到的5字节组成数据包。
仍然是lengthAdjustment,但这次和之前的有点不一样了
lengthFieldOffset = 0
lengthFieldLength = 3
lengthAdjustment = 2 (= the length of Header 1)
initialBytesToStrip = 0
解码前 (17 bytes) 解码后 (17 bytes)
| 3 bytes | 2 bytes | 12 bytes | | 3 bytes | 2 bytes | 12 bytes |
+----------+----------+----------------+ +----------+----------+----------------+
| Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
| 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+- lengthFieldLength=3表示长度域的值占3字节,然后解码器获取到前3字节的数据为12,这个12就是初始长度域的值。
- 但此时解码器发现lengthAdjustment=2,即lengthFieldLength需要修正成14(=12+2),不然只往后读12字节取不到完整的数据了。
- 最后,发现lengthAdjustment、initialBytesToStrip都=0,则不需要额外操作,往后读14字节再加上前面读到的3字节组成数据包。
下面是两个综合案例,可能会再次刷新你在上文”认为这样就是对的”想法,这一点儿也不奇怪:
lengthFieldOffset = 1 (= the length of HDR1)
lengthFieldLength = 2
lengthAdjustment = 1 (= the length of HDR2)
initialBytesToStrip = 3 (= the length of HDR1 + LEN)
解码前 (16 bytes) 解码后 (13 bytes)
|1 bytes|2 bytes |1 bytes| 12 bytes | |1 bytes| 12 bytes |
+-------+--------+-------+----------------+ +-------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000 C| 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+-------+--------+-------+----------------+ +-------+----------------+- lengthFieldOffset=1而!=0,这个参数告诉解码器,长度域的值不是从开头的字节读起了,而是开头字节的后1位开始读起,因为开头的1位是别的数据域,不属于长度域。
- 好了,现在解码器就从第2字节开始往后读2字节,成功拿到了长度域的初始值,也就是12。
- 此时解码器还发现lengthAdjustment=1,即lengthFieldLength需要修正成13(=12+1),不然只往后读12字节取不到完整的数据了。
- 之后,initialBytesToStrip=3告诉解码器:开头的前3个字节不需要读的。于是,编码器就把readerIndex移动到第3个字节处,也就是把原本读到的HDR1域,和长度域丢掉。
- 终于,编码器可以开始读数据了,从开头的第3字节处往后读了13个字节,即由HDR2域和”HELLO, WORLD”组成的数据包。
lengthFieldOffset = 1
lengthFieldLength = 2
lengthAdjustment = -3 (= the length of HDR1 + LEN, negative)
initialBytesToStrip = 3
解码前 (16 bytes) 解码后 (13 bytes)
|1 bytes|2 bytes |1 bytes| 12 bytes | |1 bytes| 12 bytes |
+-------+--------+-------+----------------+ +-------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xC A | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+-------+--------+-------+----------------+ +-------+----------------+
- lengthFieldOffset=1而!=0,这个参数告诉解码器,长度域的值不是从开头的字节读起了,而是开头字节的后1位开始读起,因为开头的1位是别的数据域,不属于长度域。
- 好了,现在解码器就从第2字节开始往后读2字节,成功拿到了长度域的初始值,也就是16。
- 此时解码器还发现lengthAdjustment=-3,即lengthFieldLength需要修正成13(=16-3),因为后面之后13字节的数据可读了。
- 之后,initialBytesToStrip=3告诉解码器:开头的前3个字节不需要读的。于是,编码器就把readerIndex移动到第3个字节处,也就是把原本读到的HDR1域,和长度域丢掉。
- 终于,编码器可以开始读数据了,从开头的第3字节处往后读了13个字节,即由HDR2域和”HELLO, WORLD”组成的数据包。