07状态
状态
键控状态
仅在键控流上才能访问键控状态,并且仅限于与当前事件的键关联的值
状态类型:
ValueState<T>: 保存一个可以更新和检索的值(每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过update(T)进行更新,通过T value()进行检索。ListState<T>: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过add(T)或者addAll(List<T>)进行添加元素,通过Iterable<T> get()获得整个列表。还可以通过update(List<T>)覆盖当前的列表。ReducingState<T>: 保存一个单值,表示添加到状态的所有值的聚合。接口与ListState类似,但使用add(T)增加元素,会使用提供的ReduceFunction进行聚合。AggregatingState<IN, OUT>: 保留一个单值,表示添加到状态的所有值的聚合。和ReducingState相反的是, 聚合类型可能与 添加到状态的元素的类型不同。 接口与ListState类似,但使用add(IN)添加的元素会用指定的AggregateFunction进行聚合。MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用put(UK,UV)或者putAll(Map<UK,UV>)添加映射。 使用get(UK)检索特定 key。 使用entries(),keys()和values()分别检索映射、键和值的可迭代视图。你还可以通过isEmpty()来判断是否包含任何键值对。
所有类型的状态还有一个clear() 方法,清除当前 key 下的状态数据,也就是当前输入元素的 key。
这些状态对象仅用于与状态交互。状态本身不一定存储在内存中,还可能在磁盘或其他位置。 另外需要牢记的是从状态中获取的值取决于输入元素所代表的 key。 因此,在不同 key 上调用同一个接口,可能得到不同的值。
必须创建一个 StateDescriptor,才能得到对应的状态句柄。 这保存了状态名称(正如我们稍后将看到的,你可以创建多个状态,并且它们必须具有唯一的名称以便可以引用它们), 状态所持有值的类型,并且可能包含用户指定的函数,例如ReduceFunction。 根据不同的状态类型,可以创建ValueStateDescriptor,ListStateDescriptor, AggregatingStateDescriptor, ReducingStateDescriptor 或 MapStateDescriptor。
状态通过 RuntimeContext 进行访问,因此只能在 rich functions 中使用。RichFunction 中 RuntimeContext 提供如下方法:
ValueState<T> getState(ValueStateDescriptor<T>)ReducingState<T> getReducingState(ReducingStateDescriptor<T>)ListState<T> getListState(ListStateDescriptor<T>)AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT>)MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)这个例子实现了一个简单的计数窗口。 我们把元组的第一个元素当作 key(在示例中都 key 都是 “1”)。 该函数将出现的次数以及总和存储在 “ValueState” 中。 一旦出现次数达到 2,则将平均值发送到下游,并清除状态重新开始。 请注意,我们会为每个不同的 key(元组中第一个元素)保存一个单独的值。
设置有效期
任何类型的 keyed state 都可以有 有效期 (TTL)。如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值,这会在后面详述。
所有状态类型都支持单元素的 TTL。 这意味着列表元素和映射元素将独立到期。
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);TTL 配置有以下几个选项: newBuilder 的第一个参数表示数据的有效期,是必选项。
TTL 的更新策略(默认是 OnCreateAndWrite):
StateTtlConfig.UpdateType.OnCreateAndWrite- 仅在创建和写入时更新StateTtlConfig.UpdateType.OnReadAndWrite- 读取时也更新
数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired):
StateTtlConfig.StateVisibility.NeverReturnExpired- 不返回过期数据StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp- 会返回过期但未清理的数据
NeverReturnExpired 情况下,过期数据就像不存在一样,不管是否被物理删除。这对于不能访问过期数据的场景下非常有用,比如敏感数据。 ReturnExpiredIfNotCleanedUp 在数据被物理删除前都会返回。
注意:
- 状态上次的修改时间会和数据一起保存在 state backend 中,因此开启该特性会增加状态数据的存储。 Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节。
- 暂时只支持基于 processing time (处理时间)的 TTL。
- 尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到 “StateMigrationException”。
- TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效。
- 当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。如果用户值序列化器不支持 null, 可以用
NullableSerializer包装一层。 - 启用 TTL 配置后,
StateDescriptor中的defaultValue(已被标记deprecated)将会失效。这个设计的目的是为了确保语义更加清晰,在此基础上,用户需要手动管理那些实际值为 null 或已过期的状态默认值。
过期数据清理
默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,同时会有后台线程定期清理(如果 StateBackend 支持的话)。可以通过 StateTtlConfig 配置关闭后台清理:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground()
.build();可以配置更细粒度的后台清理策略。当前的实现中 HeapStateBackend 依赖增量数据清理,RocksDBStateBackend 利用压缩过滤器进行后台清理。
全量快照时进行清理
可以启用全量快照时进行清理的策略,这可以减少整个快照的大小。当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据。 该策略可以通过 StateTtlConfig 配置进行配置:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();这种策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效。
注意:
- 这种清理方式可以在任何时候通过
StateTtlConfig启用或者关闭,比如在从 savepoint 恢复时。
增量清理
存储后端保留一个所有状态的惰性全局迭代器。 每次触发增量清理时,从迭代器中选择已经过期的数进行清理。
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build();第一个是每次清理时检查状态的条目数,在每个状态访问时触发。第二个参数表示是否在处理每条记录时触发清理。 Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理。
注意:
- 如果没有 state 访问,也没有处理数据,则不会清理过期数据。
- 增量清理会增加数据处理的耗时。
- 现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
- 如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用。但异步快照则没有这个问题。
- 对已有的作业,这个清理方式可以在任何时候通过
StateTtlConfig启用或禁用该特性,比如从 savepoint 重启后。
RocksDB 压缩时清理
启用 Flink 为 RocksDB 定制的压缩过滤器。RocksDB 会周期性的对数据进行合并压缩从而减少存储空间。 Flink 提供的 RocksDB 压缩过滤器会在压缩时过滤掉已经过期的状态数
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();Flink 处理一定条数的状态数据后,会使用当前时间戳来检测 RocksDB 中的状态是否已经过期, 可以指定处理状态的条数。 时间戳更新的越频繁,状态的清理越及时,但由于压缩会有调用 JNI 的开销,因此会影响整体的压缩性能。 RocksDB backend 的默认后台清理策略会每处理 1000 条数据进行一次。
注意:
- 压缩时调用 TTL 过滤器会降低速度。TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
- 对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置。
- 对已有的作业,这个清理方式可以在任何时候通过
StateTtlConfig启用或禁用该特性,比如从 savepoint 重启后。
算子状态
算子状态(或者非 keyed 状态)是绑定到一个并行算子实例的状态。Kafka Connector是 Flink 中使用算子状态一个很具有启发性的例子。Kafka consumer 每个并行实例维护了 topic partitions 和偏移量的 map 作为它的算子状态。
当并行度改变的时候,算子状态支持将状态重新分发给各并行算子实例。处理重分发过程有多种不同的方案。
CheckpointedFunction 接口提供了访问 non-keyed state 的方法,需要实现如下两个方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;进行 checkpoint 时会调用 snapshotState()。 用户自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复。 因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑。
当前 operator state 以 list 的形式存在。这些状态是一个 可序列化 对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派。 换句话说,这些对象是重新分配 non-keyed state 的最细粒度。根据状态的不同访问方式,有如下几种重新分配的模式:
- Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。 比如说,算子 A 的并发读为 1,包含两个元素
element1和element2,当并发读增加为 2 时,element1会被分到并发 0 上,element2则会被分到并发 1 上。 - Union redistribution: 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。当作业恢复或重新分配时,每个算子都将获得所有的状态数据。 Do not use this feature if your list may have high cardinality. Checkpoint metadata will store an offset to each list entry, which could lead to RPC framesize or out-of-memory errors.
getUnionListState(descriptor)会使用 union redistribution 算法, 而getListState(descriptor)则简单的使用 even-split redistribution 算法。
public class BufferingSink
implements SinkFunction<Tuple2<String, Integer>>,
CheckpointedFunction {
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void invoke(Tuple2<String, Integer> value, Context contex) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() >= threshold) {
for (Tuple2<String, Integer> element: bufferedElements) {
// send it to the sink
}
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}public static class CounterSource
extends RichParallelSourceFunction<Long>
implements CheckpointedFunction {
/** current offset for exactly once semantics */
private Long offset = 0L;
/** flag for job cancellation */
private volatile boolean isRunning = true;
/** 存储 state 的变量. */
private ListState<Long> state;
@Override
public void run(SourceContext<Long> ctx) {
final Object lock = ctx.getCheckpointLock();
while (isRunning) {
// output and state update are atomic
synchronized (lock) {
ctx.collect(offset);
offset += 1;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
state = context.getOperatorStateStore().getListState(new ListStateDescriptor<>(
"state",
LongSerializer.INSTANCE));
// 从我们已保存的状态中恢复 offset 到内存中,在进行任务恢复的时候也会调用此初始化状态的方法
for (Long l : state.get()) {
offset = l;
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
state.clear();
state.add(offset);
}
}广播状态
广播状态是一种特殊的算子状态。引入它的目的在于支持一个流中的元素需要广播到所有下游任务的使用情形。在这些任务中广播状态用于保持所有子任务状态相同。 该状态接下来可在第二个处理记录的数据流中访问。可以设想包含了一系列用于处理其他流中元素规则的低吞吐量数据流,这个例子自然而然地运用了广播状态。 考虑到上述这类使用情形,广播状态和其他算子状态的不同之处在于:
- 它具有 map 格式,
- 它仅在一些特殊的算子中可用。这些算子的输入为一个广播数据流和非广播数据流,
- 这类算子可以拥有不同命名的多个广播状态 。
在这里我们使用一个例子来展现 broadcast state 提供的接口。假设存在一个序列,序列中的元素是具有不同颜色与形状的图形,我们希望在序列里相同颜色的图形中寻找满足一定顺序模式的图形对(比如在红色的图形里,有一个长方形跟着一个三角形)。 同时,我们希望寻找的模式也会随着时间而改变。
在这个例子中,我们定义两个流,一个流包含图形(Item),具有颜色和形状两个属性。另一个流包含特定的规则(Rule),代表希望寻找的模式。
// 将图形使用颜色进行划分
KeyedStream<Item, Color> colorPartitionedStream = itemStream
.keyBy(new KeySelector<Item, Color>(){...});
// 一个 map descriptor,它描述了用于存储规则名称与规则本身的 map 存储结构
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(
"RulesBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint<Rule>() {}));
// 广播流,广播规则并且创建 broadcast state
BroadcastStream<Rule> ruleBroadcastStream = ruleStream
.broadcast(ruleStateDescriptor);
DataStream<String> output = colorPartitionedStream
.connect(ruleBroadcastStream)
.process(
// KeyedBroadcastProcessFunction 中的类型参数表示:
// 1. key stream 中的 key 类型
// 2. 非广播流中的元素类型
// 3. 广播流中的元素类型
// 4. 结果的类型,在这里是 string
new KeyedBroadcastProcessFunction<Color, Item, Rule, String>() {
// 模式匹配逻辑
}
);
new KeyedBroadcastProcessFunction<Color, Item, Rule, String>() {
// 存储部分匹配的结果,即匹配了一个元素,正在等待第二个元素
// 我们用一个数组来存储,因为同时可能有很多第一个元素正在等待
private final MapStateDescriptor<String, List<Item>> mapStateDesc =
new MapStateDescriptor<>(
"items",
BasicTypeInfo.STRING_TYPE_INFO,
new ListTypeInfo<>(Item.class));
// 与之前的 ruleStateDescriptor 相同
private final MapStateDescriptor<String, Rule> ruleStateDescriptor =
new MapStateDescriptor<>(
"RulesBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint<Rule>() {}));
@Override
public void processBroadcastElement(Rule value,
Context ctx,
Collector<String> out) throws Exception {
ctx.getBroadcastState(ruleStateDescriptor).put(value.name, value);
}
@Override
public void processElement(Item value,
ReadOnlyContext ctx,
Collector<String> out) throws Exception {
final MapState<String, List<Item>> state = getRuntimeContext().getMapState(mapStateDesc);
final Shape shape = value.getShape();
for (Map.Entry<String, Rule> entry :
ctx.getBroadcastState(ruleStateDescriptor).immutableEntries()) {
final String ruleName = entry.getKey();
final Rule rule = entry.getValue();
List<Item> stored = state.get(ruleName);
if (stored == null) {
stored = new ArrayList<>();
}
if (shape == rule.second && !stored.isEmpty()) {
for (Item i : stored) {
out.collect("MATCH: " + i + " - " + value);
}
stored.clear();
}
// 不需要额外的 else{} 段来考虑 rule.first == rule.second 的情况
if (shape.equals(rule.first)) {
stored.add(value);
}
if (stored.isEmpty()) {
state.remove(ruleName);
} else {
state.put(ruleName, stored);
}
}
}
}状态持久化
flink使用”流重放“和”检查点“实现容错,即恢复算子的状态并从检查点重放记录,可以是数据流重检查点恢复,同时保持精确一次语义
默认情况下,状态是保持在 TaskManagers 的内存中,checkpoint 保存在 JobManager 的内存中。为了合适地持久化大体量状态, Flink 支持各种各样的途径去存储 checkpoint 状态到其他的 state backends 上。通过 StreamExecutionEnvironment.setStateBackend(…) 来配置所选的 state backends。
保存点
手动触发保存点
在新的检查点后不会自动过期
检查点
flink的检查点事通过分布式快照实现的,所以快照和检查点这两个词可以互换使用。
Checkpoint 其他的属性包括:
精确一次(exactly-once)对比至少一次(at-least-once):你可以选择向
enableCheckpointing(long interval, CheckpointingMode mode)方法中传入一个模式来选择使用两种保证等级中的哪一种。 对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用的关联较大。checkpoint 超时:如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。
checkpoints 之间的最小时间:该属性定义在 checkpoint 之间需要多久的时间,以确保流应用在 checkpoint 之间有足够的进展。如果值设置为了 5000, 无论 checkpoint 持续时间与间隔是多久,在前一个 checkpoint 完成时的至少五秒后会才开始下一个 checkpoint。
往往使用“checkpoints 之间的最小时间”来配置应用会比 checkpoint 间隔容易很多,因为“checkpoints 之间的最小时间”在 checkpoint 的执行时间超过平均值时不会受到影响(例如如果目标的存储系统忽然变得很慢)。
注意这个值也意味着并发 checkpoint 的数目是一。
checkpoint 可容忍连续失败次数:该属性定义可容忍多少次连续的 checkpoint 失败。超过这个阈值之后会触发作业错误 fail over。 默认次数为“0”,这意味着不容忍 checkpoint 失败,作业将在第一次 checkpoint 失败时fail over。
并发 checkpoint 的数目: 默认情况下,在上一个 checkpoint 未完成(失败或者成功)的情况下,系统不会触发另一个 checkpoint。这确保了拓扑不会在 checkpoint 上花费太多时间,从而影响正常的处理流程。 不过允许多个 checkpoint 并行进行是可行的,对于有确定的处理延迟(例如某方法所调用比较耗时的外部服务),但是仍然想进行频繁的 checkpoint 去最小化故障后重跑的 pipelines 来说,是有意义的。
该选项不能和 “checkpoints 间的最小时间”同时使用。
externalized checkpoints: 你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上并且在 job 失败的时候不会被自动删除。 这种方式下,如果你的 job 失败,你将会有一个现有的 checkpoint 去恢复。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 开启实验性的 unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();对 operator state 的影响
在部分 Task 结束后的checkpoint中,Flink 对 UnionListState 进行了特殊的处理。 UnionListState 一般用于实现对外部系统读取位置的一个全局视图(例如,用于记录所有 Kafka 分区的读取偏移)。 如果我们在算子的某个并发调用 close() 方法后丢弃它的状态,我们就会丢失它所分配的分区的偏移量信息。 为了解决这一问题,对于使用 UnionListState 的算子我们只允许在它的并发都在运行或都已结束的时候才能进行 checkpoint 操作。
ListState 一般不会用于类似的场景,但是用户仍然需要注意在调用 close() 方法后进行的 checkpoint 会丢弃算子的状态并且 这些状态在算子重启后不可用。
精确一次(异步栅栏快照)
只有在精确一次语义下才有异步栅栏快照
同步快照有以下两种潜在的问题:
- 需要所有节点停止工作,即暂停了整个计算,这个必然影响数据处理效率和时效性.
- 需要保存所有节点/操作中的状态以及所有在传输中的数据(比如storm中的tuples),这个会消费大量的存储空间.
最原始解决异步快照问题的是Chandy lamport算法,算法总体上比较好理解,重点是通过传递marker来记录整条链路的全局状态。后续恢复的时候每个节点都可以从自己之前记录的checkpoint中恢复出来。
Flink基于Chandy lamport算法,制定了Flink自己应对流计算exactly-once语义的检查点机制Asynchronous Barrier Checkpointing
轻量级的异步栅栏快照可以用来为数据流引擎提供容错机制,同时减小的存储空间需求。因为ABS只需要保存一个无环拓扑中每个操作节点的处理状态(operator states).
异步栅栏快照的中心思想是在数据流中插入栅栏,并把event分割成不同组,通过切分源数据来划分阶段,每个集合的源数据也代表了其所需要的计算. 当上一个集合的输入数据以及输出都被完全处理,就代表上一个阶段结束了.
所以当一个阶段结束时,操作节点的状态可以代表这整个个运行历史,从而快照可以仅仅依赖于operator states.
这些阶段可以通过周期性的在源头出插入一些栅栏(barrier)来划分. 这些栅栏起到了阶段的标记作用,然后跟着数据流通过整个数据处理pipeline,知道系统的sinks.
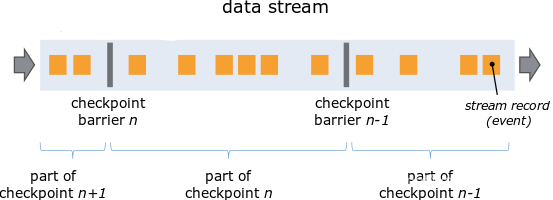
全局状态在这个过程中,被增量地构建, 即当每个处理tast接收到对应id的栅栏的时候对自己的状态进行快照,而每个节点异步的快照共同组成了一个阶段(stage)。
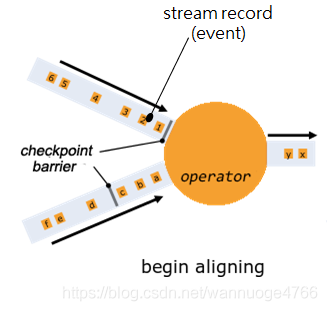
具体每个operator上,分为4个步骤:
1.对齐预备:当operator收到某个输入流中的一个barrier,就暂停运算当前输入流的数据直到这个operator收到所有来自输入流的barrier。
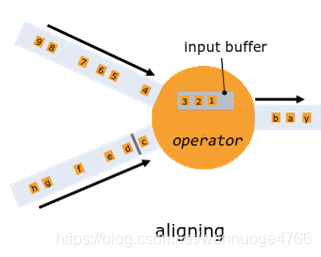
- 数据对齐:暂停运算的输入流传来的数据会被保存在operator的缓存中,等待运算。
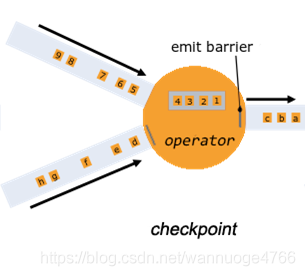
- 制作检查点:operator收到所有的barrier时,开始上传状态制作检查点。
- 继续运算:operator会先运算缓存中存储的数据,再继续运算流中的数据
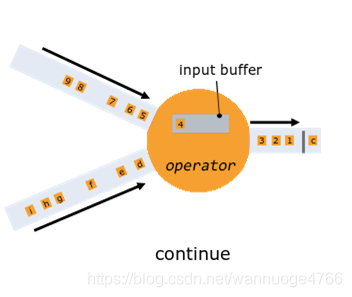
当数据sinks收到所有barriers并且进行自身状态保存之后,也进行ack的checkpointing.
分布式场景:
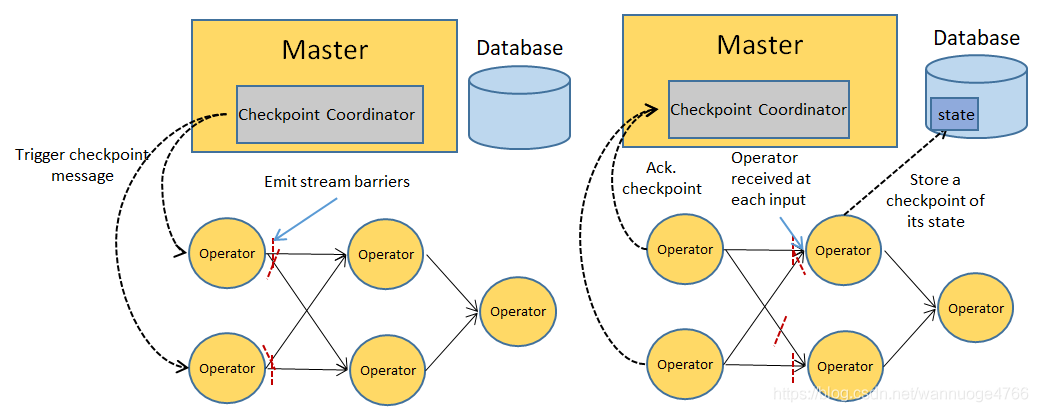
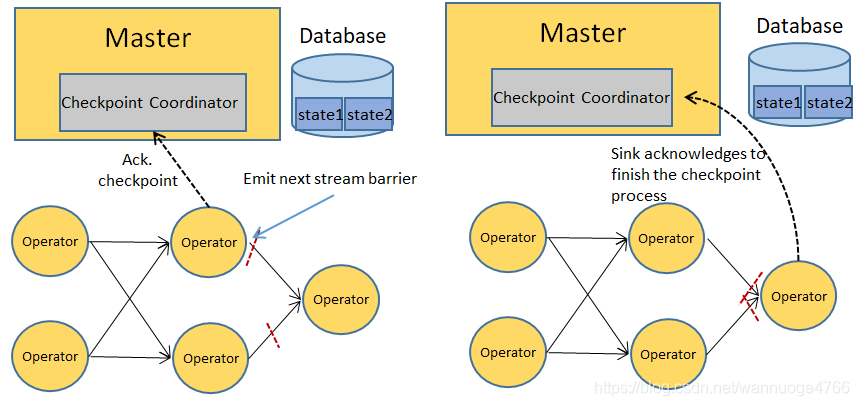
状态后端
状态可以位于 Java 的堆或堆外内存。取决于你的 state backend,Flink 也可以自己管理应用程序的状态。 为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘)。 默认情况下,所有 Flink Job 会使用配置文件 flink-conf.yaml 中指定的 state backend。
但是,配置文件中指定的默认 state backend 会被 Job 中指定的 state backend 覆盖。
类型:
- 基于堆的状态后端
- FsStateBackends
- 工作状态:Heap
- 备份:分布式文件系统
- 备注:快,但是需要大的堆内存
- MemoryStateBackends
- 工作状态:Heap
- 备份:JobManager Heap
- 对数据丢失无要求,适用于调试
- FsStateBackends
- RocksDB
- 工作状态:本地磁盘
- 备份:分布式文件系统
- 备注:速度只有基于堆的1/10,但是不依赖于堆大小