09TableAPI
TableAPI
计划器
old planner
// Stream
EnvironmentSettings envSettings = EnvironmentSettings
.newInstance()
.useOldPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(executionEnvironment,envSettings);
//batch
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tableEnvironment = BatchTableEnvironment.create(executionEnvironment);
blink planner
//Stream
EnvironmentSettings envSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(executionEnvironment, envSettings);
//batch
EnvironmentSettings envSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(envSettings);
如果’/lib’目录中只有一种计划器的JAR包,则可以使用useAnyPlanner方法创建EnvironmentSettings
查询和输出表
Table api
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// scan registered Orders table
Table orders = tableEnv.from("Orders");
// compute revenue for all customers from France
Table revenue = orders
.filter($("cCountry").isEqual("FRANCE"))
.groupBy($("cID"), $("cName"))
.select($("cID"), $("cName"), $("revenue").sum().as("revSum"));
// emit or convert Table
// execute querySql
Flink SQL 是基于实现了SQL标准的 Apache Calcite 的。SQL 查询由常规字符串指定。
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// compute revenue for all customers from France
Table revenue = tableEnv.sqlQuery(
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
// emit or convert Table
// execute query
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register "Orders" table
// register "RevenueFrance" output table
// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.executeSql(
"INSERT INTO RevenueFrance " +
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);混用 Table API 和 SQL
Table API 和 SQL 查询的混用非常简单因为它们都返回 Table 对象:
- 可以在 SQL 查询返回的
Table对象上定义 Table API 查询。 - 在
TableEnvironment中注册的结果表可以在 SQL 查询的FROM子句中引用,通过这种方法就可以在 Table API 查询的结果上定义 SQL 查询。
输出表
Table 通过写入 TableSink 输出。TableSink 是一个通用接口,用于支持多种文件格式(如 CSV、Apache Parquet、Apache Avro)、存储系统(如 JDBC、Apache HBase、Apache Cassandra、Elasticsearch)或消息队列系统(如 Apache Kafka、RabbitMQ)。
批处理 Table 只能写入 BatchTableSink,而流处理 Table 需要指定写入 AppendStreamTableSink,RetractStreamTableSink 或者 UpsertStreamTableSink。
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create an output Table
final Schema schema = Schema.newBuilder()
.column("a", DataTypes.INT())
.column("b", DataTypes.STRING())
.column("c", DataTypes.BIGINT())
.build();
tableEnv.createTemporaryTable("CsvSinkTable", TableDescriptor.forConnector("filesystem")
.schema(schema)
.option("path", "/path/to/file")
.format(FormatDescriptor.forFormat("csv")
.option("field-delimiter", "|")
.build())
.build());
// compute a result Table using Table API operators and/or SQL queries
Table result = ...;
// Prepare the insert into pipeline
TablePipeline pipeline = result.insertInto("CsvSinkTable");
// Print explain details
pipeline.printExplain();
// emit the result Table to the registered TableSink
pipeline.execute();动态表
动态表 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个 连续查询 。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。

在流上定义表
为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。
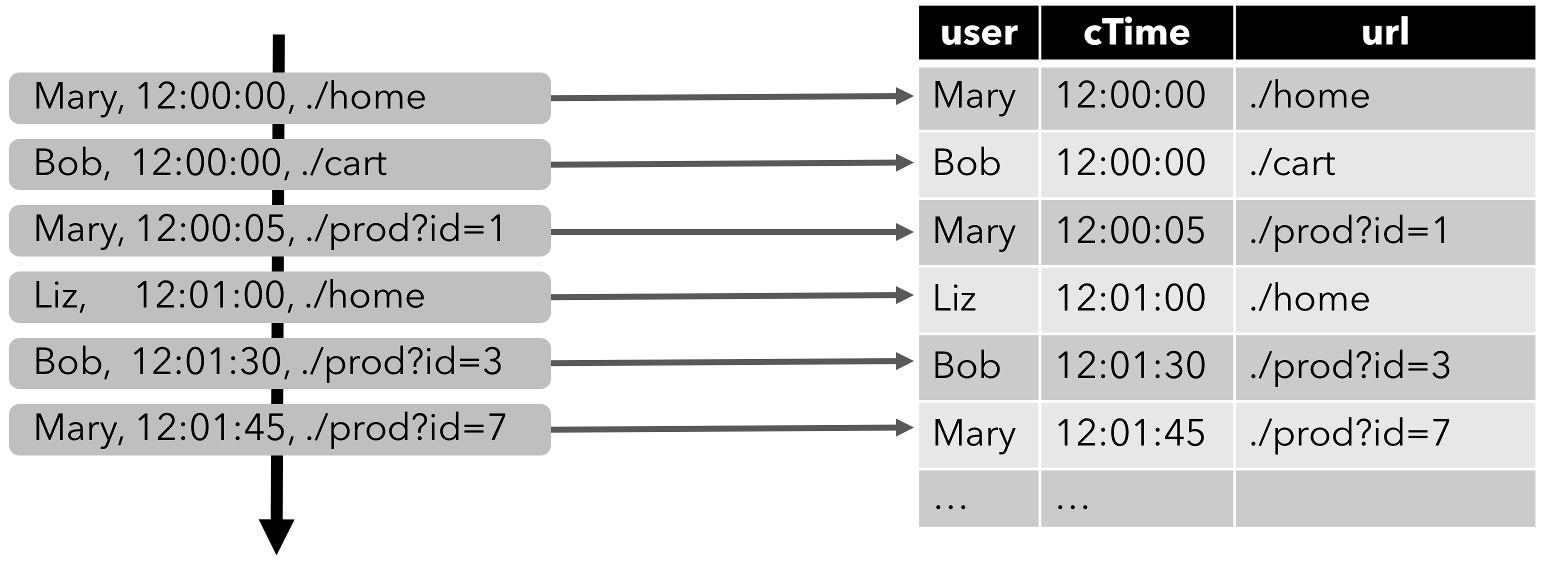
连续查询
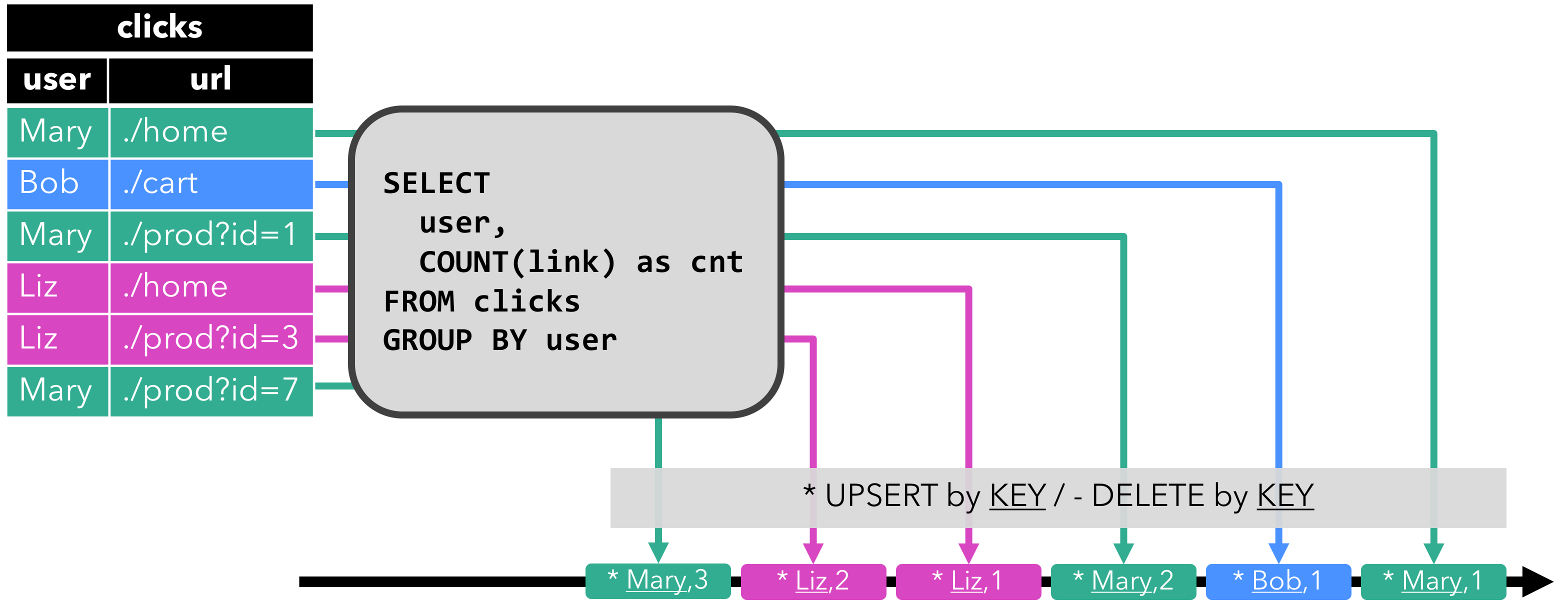
第一个查询是一个简单的 GROUP-BY COUNT 聚合查询。它基于 user 字段对 clicks 表进行分组,并统计访问的 URL 的数量。下面的图显示了当 clicks 表被附加的行更新时,查询是如何被评估的。
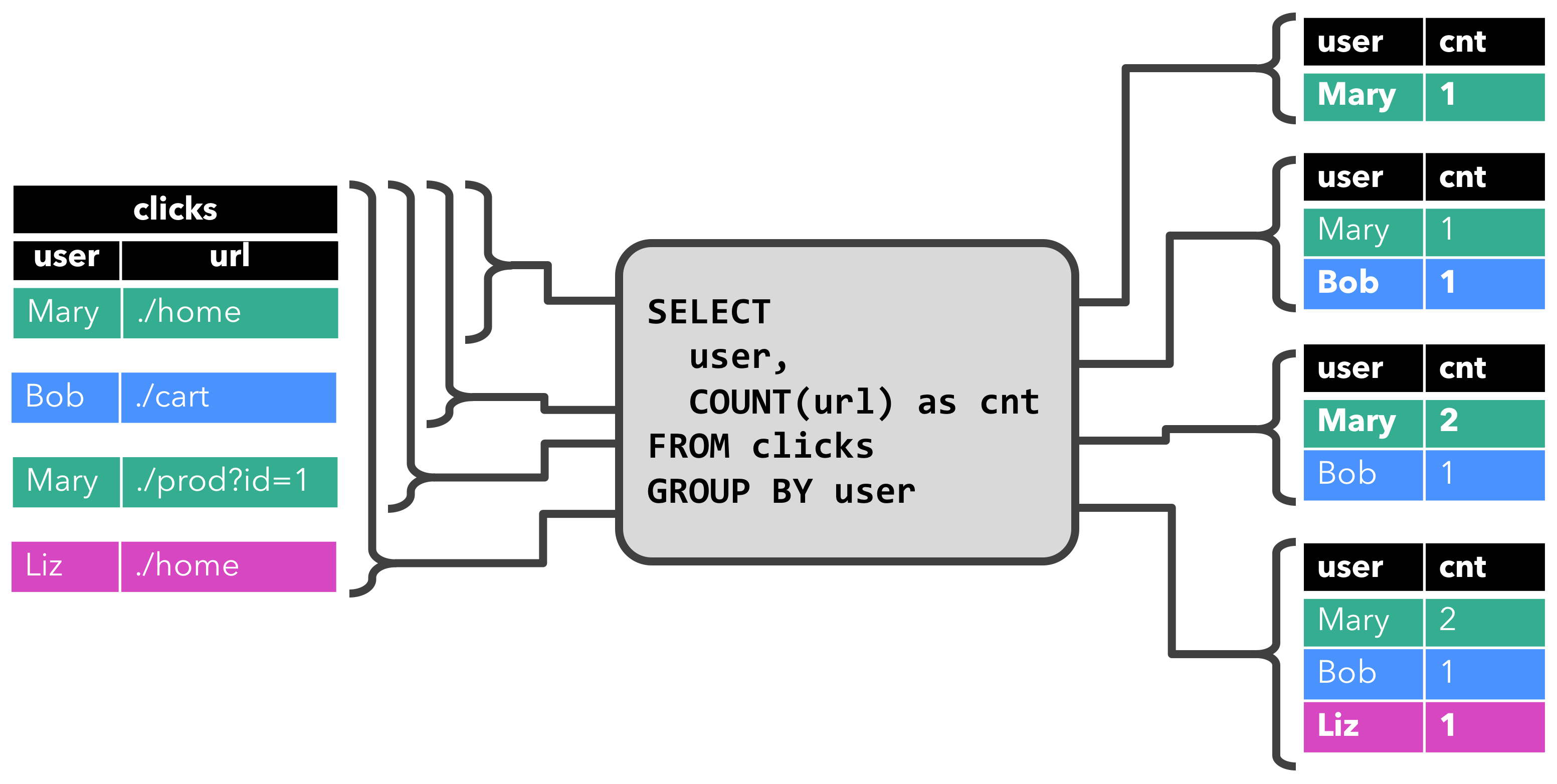
当查询开始,clicks 表(左侧)是空的。当第一行数据被插入到 clicks 表时,查询开始计算结果表。第一行数据 [Mary,./home] 插入后,结果表(右侧,上部)由一行 [Mary, 1] 组成。当第二行 [Bob, ./cart] 插入到 clicks 表时,查询会更新结果表并插入了一行新数据 [Bob, 1]。第三行 [Mary, ./prod?id=1] 将产生已计算的结果行的更新,[Mary, 1] 更新成 [Mary, 2]。最后,当第四行数据加入 clicks 表时,查询将第三行 [Liz, 1] 插入到结果表中。
第二条查询与第一条类似,但是除了用户属性之外,还将 clicks 分组至每小时滚动窗口中,然后计算 url 数量(基于时间的计算,例如基于特定时间属性的窗口,后面会讨论)。同样,该图显示了不同时间点的输入和输出,以可视化动态表的变化特性。
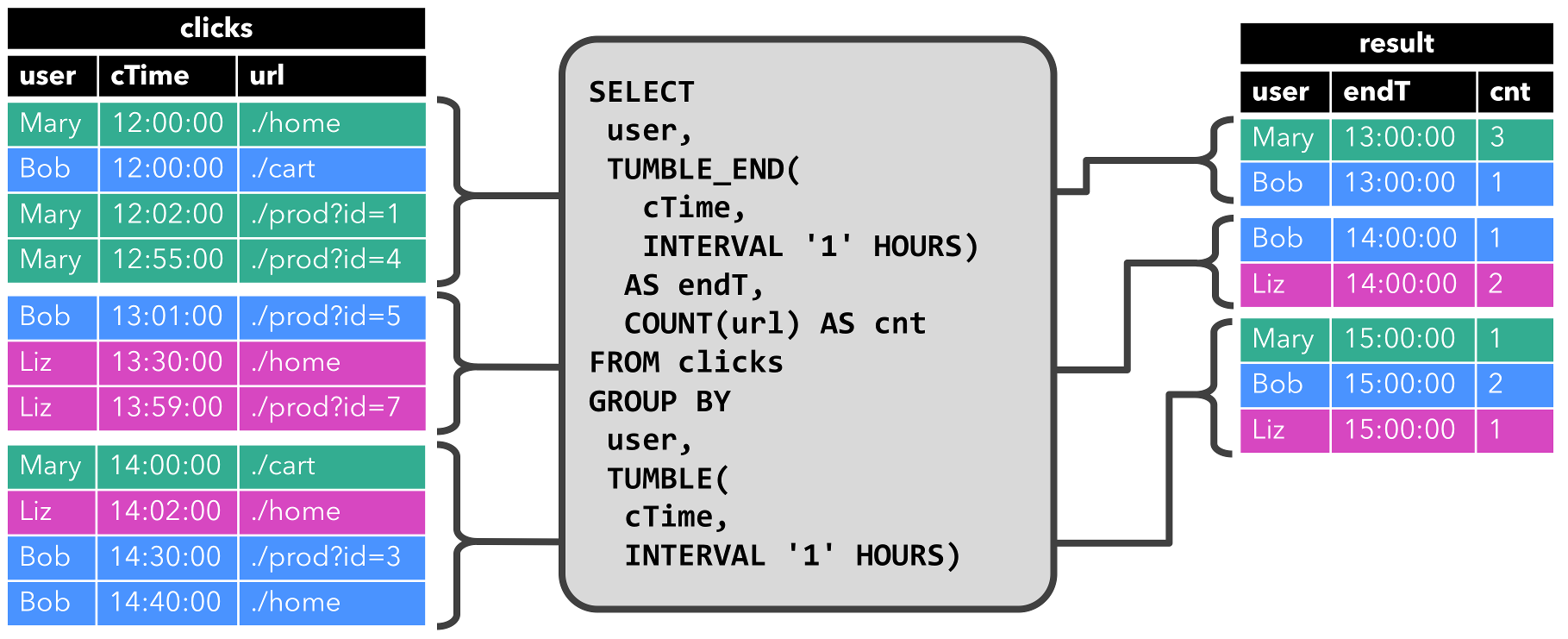
与前面一样,左边显示了输入表 clicks。查询每小时持续计算结果并更新结果表。clicks表包含四行带有时间戳(cTime)的数据,时间戳在 12:00:00 和 12:59:59 之间。查询从这个输入计算出两个结果行(每个 user 一个),并将它们附加到结果表中。对于 13:00:00 和 13:59:59 之间的下一个窗口,clicks 表包含三行,这将导致另外两行被追加到结果表。随着时间的推移,更多的行被添加到 click 中,结果表将被更新。
查询限制
许多(但不是全部)语义上有效的查询可以作为流上的连续查询进行评估。有些查询代价太高而无法计算,这可能是由于它们需要维护的状态大小,也可能是由于计算更新代价太高。
- 状态大小: 连续查询在无界流上计算,通常应该运行数周或数月。因此,连续查询处理的数据总量可能非常大。必须更新先前输出的结果的查询需要维护所有输出的行,以便能够更新它们。例如,第一个查询示例需要存储每个用户的 URL 计数,以便能够增加该计数并在输入表接收新行时发送新结果。如果只跟踪注册用户,则要维护的计数数量可能不会太高。但是,如果未注册的用户分配了一个惟一的用户名,那么要维护的计数数量将随着时间增长,并可能最终导致查询失败。
SELECT user, COUNT(url)
FROM clicks
GROUP BY user;- 计算更新: 有些查询需要重新计算和更新大量已输出的结果行,即使只添加或更新一条输入记录。显然,这样的查询不适合作为连续查询执行。下面的查询就是一个例子,它根据最后一次单击的时间为每个用户计算一个
RANK。一旦click表接收到一个新行,用户的lastAction就会更新,并必须计算一个新的排名。然而,由于两行不能具有相同的排名,所以所有较低排名的行也需要更新。
SELECT user, RANK() OVER (ORDER BY lastAction)
FROM (
SELECT user, MAX(cTime) AS lastAction FROM clicks GROUP BY user
);表到流的转换
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
- Append-only 流: 仅通过
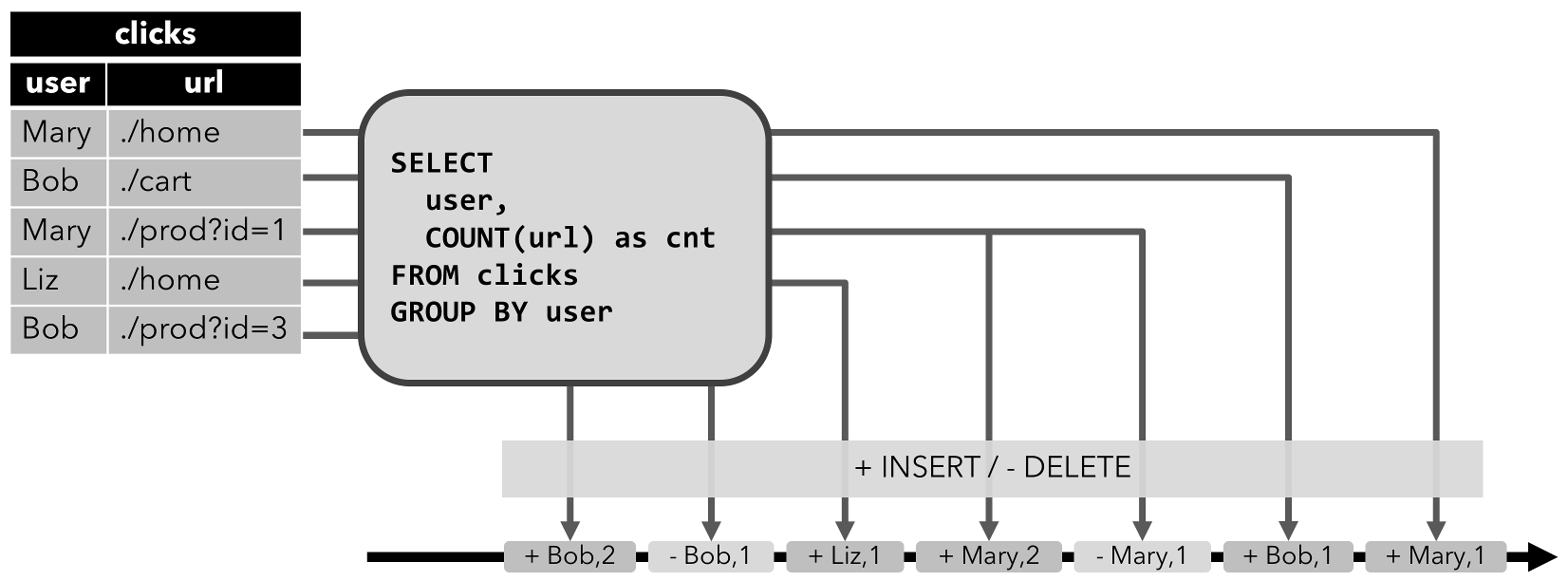
INSERT操作修改的动态表可以通过输出插入的行转换为流。 - Retract 流: retract 流包含两种类型的 message: add messages 和 retract messages 。通过将
INSERT操作编码为 add message、将DELETE操作编码为 retract message、将UPDATE操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,将动态表转换为 retract 流。下图显示了将动态表转换为 retract 流的过程。
- Upsert 流: upsert 流包含两种类型的 message: upsert messages 和delete messages。转换为 upsert 流的动态表需要(可能是组合的)唯一键。通过将
INSERT和UPDATE操作编码为 upsert message,将DELETE操作编码为 delete message ,将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。与 retract 流的主要区别在于UPDATE操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。
在将动态表转换为 DataStream 时,只支持 append 流和 retract 流。
时间属性
每种类型的表都可以有时间属性,可以在用CREATE TABLE DDL创建表的时候指定、也可以在 DataStream 中指定、也可以在定义 TableSource 时指定。一旦时间属性定义好,它就可以像普通列一样使用,也可以在时间相关的操作中使用。
只要时间属性没有被修改,而是简单地从一个表传递到另一个表,它就仍然是一个有效的时间属性。时间属性可以像普通的时间戳的列一样被使用和计算。一旦时间属性被用在了计算中,它就会被物化,进而变成一个普通的时间戳。普通的时间戳是无法跟 Flink 的时间以及watermark等一起使用的,所以普通的时间戳就无法用在时间相关的操作中。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); // default
// 或者:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime); //摄入时间
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); //时间时间处理时间
DDL中定义
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time AS PROCTIME() -- 声明一个额外的列作为处理时间属性
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);DataStream->Table中定义
处理时间属性可以在 schema 定义的时候用 .proctime 后缀来定义。时间属性一定不能定义在一个已有字段上,所以它只能定义在 schema 定义的最后。
DataStream<Tuple2<String, String>> stream = ...;
// 声明一个额外的字段作为时间属性字段
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").proctime());
WindowedTable windowedTable = table.window(
Tumble.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));TableSource中定义
// 定义一个由处理时间属性的 table source
public class UserActionSource implements StreamTableSource<Row>, DefinedProctimeAttribute {
@Override
public TypeInformation<Row> getReturnType() {
String[] names = new String[] {"user_name" , "data"};
TypeInformation[] types = new TypeInformation[] {Types.STRING(), Types.STRING()};
return Types.ROW(names, types);
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment execEnv) {
// create stream
DataStream<Row> stream = ...;
return stream;
}
@Override
public String getProctimeAttribute() {
// 这个名字的列会被追加到最后,作为第三列
return "user_action_time";
}
}
// register table source
tEnv.registerTableSource("user_actions", new UserActionSource());
WindowedTable windowedTable = tEnv
.from("user_actions")
.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));事件时间
DDL中定义
WATERMARK 语句在一个已有字段上定义一个 watermark 生成表达式,同时标记这个已有字段为时间属性字段。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time TIMESTAMP(3),
-- 声明 user_action_time 是事件时间属性,并且用 延迟 5 秒的策略来生成 watermark
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);源数据中的时间戳数据表示为一个纪元 (epoch) 时间,通常是一个 long 值,例如 1618989564564,建议将事件时间属性定义在 TIMESTAMP_LTZ 列上:
CREATE TABLE user_actions (
user_name STRING,
data STRING,
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
-- declare time_ltz as event time attribute and use 5 seconds delayed watermark strategy
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(time_ltz, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(time_ltz, INTERVAL '10' MINUTE);DataStream->Table
时间戳和 watermark在这之前一定是在 DataStream 上已经定义好了。
在从 DataStream 转换到 Table 时,由于 DataStream 没有时区概念,因此 Flink 总是将 rowtime 属性解析成 TIMESTAMP WITHOUT TIME ZONE 类型,并且将所有事件时间的值都视为 UTC 时区的值。
// Option 1:
// 基于 stream 中的事件产生时间戳和 watermark
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").rowtime());
// Option 2:
// 从第一个字段获取事件时间,并且产生 watermark
DataStream<Tuple3<Long, String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 第一个字段已经用作事件时间抽取了,不用再用一个新字段来表示事件时间了
Table table = tEnv.fromDataStream(stream, $("user_action_time").rowtime(), $("user_name"), $("data"));
// Usage:
WindowedTable windowedTable = table.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));TableSource中定义
// 定义一个有事件时间属性的 table source
public class UserActionSource implements StreamTableSource<Row>, DefinedRowtimeAttributes {
@Override
public TypeInformation<Row> getReturnType() {
String[] names = new String[] {"user_name", "data", "user_action_time"};
TypeInformation[] types =
new TypeInformation[] {Types.STRING(), Types.STRING(), Types.LONG()};
return Types.ROW(names, types);
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment execEnv) {
// 构造 DataStream
// ...
// 基于 "user_action_time" 定义 watermark
DataStream<Row> stream = inputStream.assignTimestampsAndWatermarks(...);
return stream;
}
@Override
public List<RowtimeAttributeDescriptor> getRowtimeAttributeDescriptors() {
// 标记 "user_action_time" 字段是事件时间字段
// 给 "user_action_time" 构造一个时间属性描述符
RowtimeAttributeDescriptor rowtimeAttrDescr = new RowtimeAttributeDescriptor(
"user_action_time",
new ExistingField("user_action_time"),
new AscendingTimestamps());
List<RowtimeAttributeDescriptor> listRowtimeAttrDescr = Collections.singletonList(rowtimeAttrDescr);
return listRowtimeAttrDescr;
}
}
// register the table source
tEnv.registerTableSource("user_actions", new UserActionSource());
WindowedTable windowedTable = tEnv
.from("user_actions")
.window(Tumble.over(lit(10).minutes()).on($("user_action_time")).as("userActionWindow"));时态表(Temporal Tables)
时态表(Temporal Table)是一张随时间变化的表 – 在 Flink 中称为动态表,时态表中的每条记录都关联了一个或多个时间段,所有的 Flink 表都是时态的(动态的)。
时态表包含表的一个或多个有版本的表快照,时态表可以是一张跟踪所有变更记录的表(例如数据库表的 changelog,包含多个表快照),也可以是物化所有变更之后的表(例如数据库表,只有最新表快照)。
版本: 时态表可以划分成一系列带版本的表快照集合,表快照中的版本代表了快照中所有记录的有效区间,有效区间的开始时间和结束时间可以通过用户指定,根据时态表是否可以追踪自身的历史版本与否,时态表可以分为 版本表 和 普通表。
版本表: 如果时态表中的记录可以追踪和并访问它的历史版本,这种表我们称之为版本表,来自数据库的 changelog 可以定义成版本表。
普通表: 如果时态表中的记录仅仅可以追踪并和它的最新版本,这种表我们称之为普通表,来自数据库 或 HBase 的表可以定义成普通表。
版本表声明
-- 定义一张版本表
CREATE TABLE product_changelog (
product_id STRING,
product_name STRING,
product_price DECIMAL(10, 4),
update_time TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL,
PRIMARY KEY(product_id) NOT ENFORCED, -- (1) 定义主键约束
WATERMARK FOR update_time AS update_time -- (2) 通过 watermark 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'products',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'value.format' = 'debezium-json'
);(1) 为表 product_changelog 定义了主键,
(2) 把 update_time 定义为表 product_changelog 的事件时间,因此 product_changelog 是一张版本表。
注意: METADATA FROM 'value.source.timestamp' VIRTUAL 语法的意思是从每条 changelog 中抽取 changelog 对应的数据库表中操作的执行时间,强烈推荐使用数据库表中操作的 执行时间作为事件时间 ,否则通过时间抽取的版本可能和数据库中的版本不匹配。
视图声明
CREATE VIEW versioned_rates AS
SELECT currency, rate, currency_time -- (1) `currency_time` 保留了事件时间
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY currency -- (2) `currency` 是去重 query 的 unique key,可以作为主键
ORDER BY currency_time DESC) AS rowNum
FROM RatesHistory )
WHERE rowNum = 1;声明普通表
-- 用 DDL 定义一张 HBase 表,然后我们可以在 SQL 中将其当作一张时态表使用
-- 'currency' 列是 HBase 表中的 rowKey
CREATE TABLE LatestRates (
currency STRING,
fam1 ROW<rate DOUBLE>
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'rates',
'zookeeper.quorum' = 'localhost:2181'
);当前支持作为时态表的普通表必须实现接口 LookupableTableSource。接口 LookupableTableSource 的实例只能作为时态表用于基于处理时间的时态 Join 。
通过 LookupableTableSource 定义的表意味着该表具备了在运行时通过一个或多个 key 去查询外部存储系统的能力,当前支持在 基于处理时间的时态表 join 中使用的表包括 JDBC, HBase和 Hive。
Catalog
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
类型
GenericInMemoryCatalog
GenericInMemoryCatalog 是基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。
JdbcCatalog
JdbcCatalog 使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。Postgres Catalog 和 MySQL Catalog 是目前 JDBC Catalog 仅有的两种实现。
HiveCatalog
HiveCatalog 有两个用途:作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口。
临时表与永久表
- Table既可以是临时表(temporaay table),或者叫虚拟叫(view);也可以是永久表(Permanent table)
- 视图可以从已经存在的Table中创建
- 临时表与单个Flink会话的生命周期相关,仅在创建的会话中存在
- 永久表需要Catalog以维护表的元数据,一旦永久表倍创建,它将对任何连接到catalog的flink会话可见,直到被明确删除
- 可以创建于永久表相同标识的临时表,临时表可以覆盖永久表
创建 Flink 表并将其注册到 Catalog
TableEnvironment tableEnv = ...;
// Create a HiveCatalog
Catalog catalog = new HiveCatalog("myhive", null, "<path_of_hive_conf>");
// Register the catalog
tableEnv.registerCatalog("myhive", catalog);
// Create a catalog database
tableEnv.executeSql("CREATE DATABASE mydb WITH (...)");
// Create a catalog table
tableEnv.executeSql("CREATE TABLE mytable (name STRING, age INT) WITH (...)");
tableEnv.listTables(); // should return the tables in current catalog and database.import org.apache.flink.table.api.*;
import org.apache.flink.table.catalog.*;
import org.apache.flink.table.catalog.hive.HiveCatalog;
TableEnvironment tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode());
// Create a HiveCatalog
Catalog catalog = new HiveCatalog("myhive", null, "<path_of_hive_conf>");
// Register the catalog
tableEnv.registerCatalog("myhive", catalog);
// Create a catalog database
catalog.createDatabase("mydb", new CatalogDatabaseImpl(...));
// Create a catalog table
final Schema schema = Schema.newBuilder()
.column("name", DataTypes.STRING())
.column("age", DataTypes.INT())
.build();
tableEnv.createTable("myhive.mydb.mytable", TableDescriptor.forConnector("kafka")
.schema(schema)
// …
.build());
List<String> tables = catalog.listTables("mydb"); // tables should contain "mytable"Catalog API
数据库操作
// create database
catalog.createDatabase("mydb", new CatalogDatabaseImpl(...), false);
// drop database
catalog.dropDatabase("mydb", false);
// alter database
catalog.alterDatabase("mydb", new CatalogDatabaseImpl(...), false);
// get database
catalog.getDatabase("mydb");
// check if a database exist
catalog.databaseExists("mydb");
// list databases in a catalog
catalog.listDatabases("mycatalog");表操作
// create table
catalog.createTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);
// drop table
catalog.dropTable(new ObjectPath("mydb", "mytable"), false);
// alter table
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);
// rename table
catalog.renameTable(new ObjectPath("mydb", "mytable"), "my_new_table");
// get table
catalog.getTable("mytable");
// check if a table exist or not
catalog.tableExists("mytable");
// list tables in a database
catalog.listTables("mydb");视图操作
// create view
catalog.createTable(new ObjectPath("mydb", "myview"), new CatalogViewImpl(...), false);
// drop view
catalog.dropTable(new ObjectPath("mydb", "myview"), false);
// alter view
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogViewImpl(...), false);
// rename view
catalog.renameTable(new ObjectPath("mydb", "myview"), "my_new_view", false);
// get view
catalog.getTable("myview");
// check if a view exist or not
catalog.tableExists("mytable");
// list views in a database
catalog.listViews("mydb");分区
// create view
catalog.createPartition(
new ObjectPath("mydb", "mytable"),
new CatalogPartitionSpec(...),
new CatalogPartitionImpl(...),
false);
// drop partition
catalog.dropPartition(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...), false);
// alter partition
catalog.alterPartition(
new ObjectPath("mydb", "mytable"),
new CatalogPartitionSpec(...),
new CatalogPartitionImpl(...),
false);
// get partition
catalog.getPartition(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));
// check if a partition exist or not
catalog.partitionExists(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));
// list partitions of a table
catalog.listPartitions(new ObjectPath("mydb", "mytable"));
// list partitions of a table under a give partition spec
catalog.listPartitions(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));
// list partitions of a table by expression filter
catalog.listPartitions(new ObjectPath("mydb", "mytable"), Arrays.asList(epr1, ...));函数操作
// create function
catalog.createFunction(new ObjectPath("mydb", "myfunc"), new CatalogFunctionImpl(...), false);
// drop function
catalog.dropFunction(new ObjectPath("mydb", "myfunc"), false);
// alter function
catalog.alterFunction(new ObjectPath("mydb", "myfunc"), new CatalogFunctionImpl(...), false);
// get function
catalog.getFunction("myfunc");
// check if a function exist or not
catalog.functionExists("myfunc");
// list functions in a database
catalog.listFunctions("mydb");Table API 和 SQL Client 操作 Catalog
注册catalog
tableEnv.registerCatalog(new CustomCatalog("myCatalog"));修改当前catalog和数据库
tableEnv.useCatalog("myCatalog");
tableEnv.useDatabase("myDb");
tableEnv.from("not_the_current_catalog.not_the_current_db.my_table");列出catalog
tableEnv.listCatalogs();列出数据库
tableEnv.listDatabases();列出表
tableEnv.listTables();Table API
from
Table orders = tableEnv.from("Orders");fromValues
//这个方法会根据输入的表达式自动获取类型。如果在某一个特定位置的类型不一致,该方法会尝试寻找一个所有类型的公共超类型。如果公共超类型不存在,则会抛出异常。
Table table = tEnv.fromValues(
row(1, "ABC"),
row(2L, "ABCDE")
);Table table = tEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.DECIMAL(10, 2)),
DataTypes.FIELD("name", DataTypes.STRING())
),
row(1, "ABC"),
row(2L, "ABCDE")
);select
Table orders = tableEnv.from("Orders");
Table result = orders.select($("a"), $("c").as("d"));
Table result = orders.select($("*"));as
Table orders = tableEnv.from("Orders");
Table result = orders.as("x, y, z, t");where
Table orders = tableEnv.from("Orders");
Table result = orders.where($("b").isEqual("red"));
Table orders = tableEnv.from("Orders");
Table result = orders.filter($("b").isEqual("red"));………