01readme
本文最后更新于 2024-12-16 11:25:29
总结
理论:
什么是数据建模
定义数据的要求和数据分析的蓝图。用于表明数据点和结构之间的关系,说明数据在系统中的存储类型,相互之间的关系,以及数据属性等信息。数据模型往往是根据业务需求构建的,当然也要结合系统框架,调度类型等等。
数据模型
- 星型模型
- 数据呈现一个中心事实表+多个维度表 事实表包含业务度量(通常是数值型数据),维度表包含用户描述业务度量的上下文信息
- 雪花模型
- 雪花模型是星型模型的扩展,其维度表被规范化成多个表,形成类似雪花的结构,有助于减少数据冗余,但是可能会增加查询的复杂性
- 星座模型
- 星座模型是星型模型的扩展,允许多个事实表共享相同的维度,能够更好的支持业务过程或主题,同时保持维度的一致性
数仓分层
数据引入层(ODS,Operation Data Store)
数据公共层(CDM,Common Data Model)
- 维表层(DIM)
- 明细数据层(DWD,Data Warehouse Detail):以业务过程为建模驱动,基于每个具体业务过程的特点,构建细粒度的明细层事实表。
- 汇总数据层(DWS,Data Warehouse Summary):以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表
数据应用层(ADS,Application Data Service)
HIVE
hive常见参数优化
1.并行执行
set hive.exec.parallel=true,-- 可以开启并发执行。
set hive.exec.parallel.thread.number=xx; //同一个sql允许最大并行度,默认为8。划分后没有依赖的stage可以并行处理
2.map个数
set mapred.max.split.size=xxx;
set mapred.min.split.size=xxx;
set mapred.min.split.size.per.node=xxx; -- 每个节点处理的最小split
set mapred.min.split.size.per.rack=xxx; -- 每个机架处理的最小slit
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;- 一般默认的split切片小于等于blocksize(128Mb),如果是小文件的话(未进行小文件的合并)则每个小文件启动一个map函数
- 决定map个数的因素有很多,比如文件是否压缩,压缩的后的文件是否支持切分,比如文件默认的inputfort格式
- 某些压缩算法虽然不支持文件切分,但是可以进行文件合并(也是基于文件块的整个文件块合并)
- map不能直接设置个数
- splitsize 计算方法
splitsize= Math.max(minSize, Math.min(maxSize, blockSize)) - 常见存储格式:
SequenceFile: Hadoop的二进制文件格式,可压缩。支持切分(Split)
Avro: 一种数据序列化格式,支持压缩。同样支持切分。
Parquet: 列式存储格式,支持多种压缩算法(如Snappy、Gzip)。也支持切分。
ORC(Optimized Row Columnar): 列式存储格式,支持多种压缩算法。同样支持切分。
TextFile 文本文件格式,支持压缩
- 常见压缩算法:
- Gzip: Gzip 是一种通用的压缩算法,适用于文本和非文本数据。它压缩文件为一个整体,不支持切割。
- Bzip2: Bzip2 是一种高效的压缩算法,适用于文本数据。与Gzip不同,Bzip2支持分块压缩,因此支持切割。
- Snappy: Snappy 是一种快速的压缩/解压缩算法,适用于二进制数据。它不支持切割(但是作用在Sequence、Avro、parquet、orc等这些容器类的文件格式上,能够支持切分),因为它的设计目标是在快速压缩和解压缩之间找到平衡
- Deflate: Deflate 是 Gzip 和 Zip 等格式的基础压缩算法,通常用于压缩归档文件。它不支持切割
3.reduce个数
set mapred.reduce.tasks=xx; --直接指定个数
set hive.exec.reducers.bytes.per.reducer = xx;
set hive.exec.reducers.max=xx;一般根据输入文件的总大小,自动计算reduce的个数:reduce个数 = InputFileSize / bytes per reducer
4.jvm重用
set mapred.job.reuse.jvm.num.tasks=10; --10为重用个数避免小文件的场景或者task特别多的场景,JVM的启动过程会造成很大的开销
5.动态分区调整
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=100;
set hive.exec.max.dynamic.partitions=1000;6.数据倾斜
set hive.map.aggr=true ; --在map中会做部分聚集操作
set hive.groupby.skewindata = true;
set hive.auto.convert.join = true; -- 默认为false 如果是小表,自动选择Mapjoin
set hive.mapjoin.smalltable.filesize=xxx;hive.map.aggr :类似于 combiner
hive.groupby.skewindata: 数据倾斜的时候进行负载均衡,查询计划生成两个MR job,第一个job先进行key随机分配处理,随机分布到Reduce中,每个Reduce做部分聚合操作,先缩小数据量。第二个job再进行真正的group by key处理
7.小文件合并
-- 设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
--设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
-- 设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
--当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=160000008.动态分区同时打开文件句柄数过多
set hive.optimize.sort.dynamic.partition=true; -- 类似于impala /* +NOCLUSTERED */ HintsWhen enabled, dynamic partitioning column will be globally sorted.
This way we can keep only one record writer open for each partition value in the reducer thereby reducing the memory pressure on reducers.
这个参数可以使得每个reducer在每个分区只有一个writer,但会降低reduce处理并写入一个分区的速度。
hive combiner
map端先对数据做一次聚合,再发送到reducer计算最终结果,可以看做局部的Reducer
能够减少Map Task输出的数据量,中间结果非常大导致IO成为瓶颈时,数据会落盘
能够减少Reduce-Map网络传输的数据量(网络IO)
hive partitioner
Partitioner 处于 Mapper阶段,当Mapper处理好数据后,这些数据需要经过Partitioner进行分区,来选择不同的Reducer处理,从而将Mapper的输出结果均匀的分布在Reducer上面执行
Partitioner 的默认实现:hash(key) mod R,这里的R代表Reduce Task 的数目
hive优缺点
优点:
- Hive 封装了一层接口,并提供类 SQL 的查询功能,避免去写 MapReduce,减少了开发人员的学习成本
- Hive 支持用户自定义函数,可以根据自己的需求来实现自己的函数
- 可扩展性强
- 容错性强
缺点:
- Hive 不支持记录级别的删改操作
- Hive 延迟较高,不适用于实时分析
- Hive 不支持事务
hive内外部表区别
- 未被external修饰的是内部表(managed table),被external修饰的为外部表(external table)
- 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除
- 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定
Hive的用户自定义函数实现步骤与流程
第一步:继承UDF或者UDAF或者UDTF,实现特定的方法;
第二步:将写好的类打包为jar,如hivefirst.jar;
第三步:进入到Hive外壳环境中,利用add jar /home/hadoop/hivefirst.jar注册该jar文件;
第四步:为该类起一个别名,create temporary function mylength as ‘com.whut.StringLength’,这里注意UDF只是为这个Hive会话临时定义的;
Hive的cluster by、sort by、distribute by、orderby区别
order by : 全局排序 。对于 MR 任务来说,如果使用了 Order By 排序,意味着MR 任务只会有一个 Reducer 参与排序
sort by :执行一个局部排序过程。这可以保证每个reduce的输出数据都是有序的(但并非全局有效),如果Reduce数量是1,作用与order by一样, 可以用于查询结果排序
distribute by:控制在map端如何拆分数据给reduce端的,确保具有相同键的记录会进入相同的Reducer,通常配合sort by使用。distribute by rand() 可以防止数据倾斜
cluster by:将相同hash值数据放在一起 ,可以提高查询速度。当distribute by 和 sort by 所指定的字段相同时,相当于cluster by
sort by 中的limit:可以在sort by 用limit子句减少数据量,使用limit n 后,传输到reduce端的数据记录数就减少到 n *(map个数),也就是说我们在sort by 中使用limit 限制的实际上是每个reducer 中的数量,然后再根据sort by的排序字段进行order by,最后返回n 条数据给客户端
hive的执行引擎
MR,Tez,Spark
计算模型:
- MR : 基于经典的MapReuduce模型,包括Map和Reduce阶段
- Tez: 使用有向无环图(DAG)计算模型,减少不必要的磁盘写入
- Spark: DAG ,允许数据缓存在内存里面减少磁盘写入
执行任务方式:
- MR,Tez:离线
- Spark: 离线+实时
Hive count(distinct) 和 group by 区别
都会在map阶段count,但reduce阶段,distinct只有一个, group by 可以有多个进行并行聚合,所以group by会快count(distinct) 将所有的数据都shuffle到一个reducer里面
count(distinct) 在处理大量不同值时可能会消耗大量内存
分析函数中加Order By和不加Order By的区别
使用order by后,min(salary)等同于 min(salary) over(partition by xxx order by xxx range between unbounded preceding and current row ),当然可以在order by后使用框架子句,即rows,range,默认在窗口范围中当前行到之前所有行的数据进行统计。
窗口函数的分类
- 序号函数:row_number() / rank() / dense_rank()
- 分布函数:percent_rank() / cume_dist()
- 前后函数:lag() / lead()
- 头尾函数:first_val() / last_val()
- 聚合函数+窗口函数联合:
- 求和 sum() over()
- 求最大/小 max()/min() over()
- 求平均 avg() over()
percent_rank() : 分组内当前行的RANK值-1/分组内总行数-1
cume_dist() : 小于等于当前值的行数/分组内总行数
rows between …… and ……
unbounded preceding 前面所有行
unbounded following 后面所有行
current row 当前行
n following 后面n行
n preceding 前面n行
rows表示 行,就是前n行,后n行
而range表示的是 具体的值,比这个值小n的行,比这个值大n的行
range between 4 preceding AND 7 followingHive SQL执行执行流程
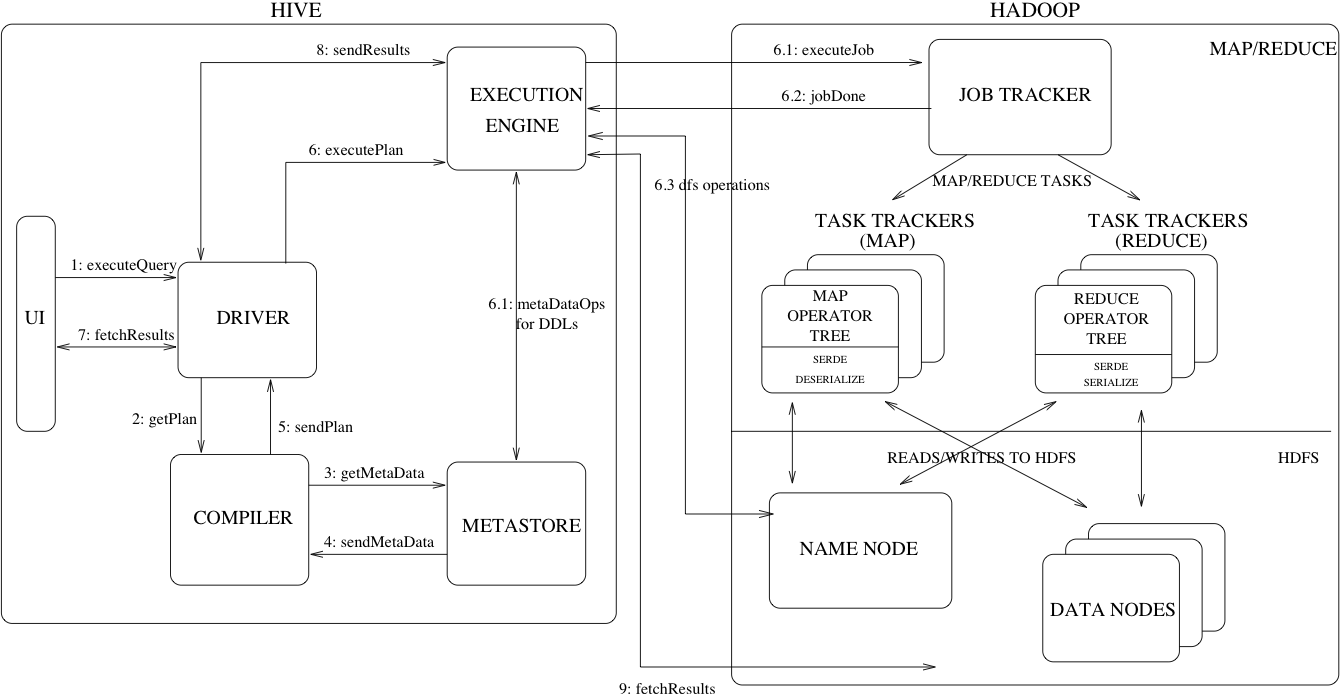
组件:
UI: 用户交互界面,用于提交SQLDRIVER: 用于接收SQL语句,是客户提交任务的第一接收者,是Hive执行的发起者,也是执行结果的反馈者,并且提供JDBC/ODBC接口为模型的执行和API的获取COMPILER: 解析CLI提交的语句,根据不同的查询做语义分析,并从metastore中获取表和元数据生成执行计划EXECUTION ENGINE: 创建执行计划的组件,基于DAG的阶段执行。执行引擎管理不同阶段的依赖关系,并在各自适应的组件上执行这些计划METASTORE: 存储表和分区的所有信息,包扩列和列类型的组件。
SQL提交到Driver端后,会做词法和语法的解析验证的同时做语义的分析(获取元数据信息),通过对元数据的解析得到逻辑计划并进行优化。解析完毕逻辑计划的同时生成物理计划(体现在执行算子上),至此任务就交给底层引擎执行了
Hive SQL编译过程
- Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
1.sql语法解析
样例SQL
FROM
(
SELECT
p.datekey datekey,
p.userid userid,
c.clienttype
FROM
detail.usersequence_client c
JOIN fact.orderpayment p ON p.orderid = c.orderid
JOIN default.user du ON du.userid = p.userid
WHERE p.datekey = 20131118
) base
INSERT OVERWRITE TABLE `test`.`customer_kpi`
SELECT
base.datekey,
base.clienttype,
count(distinct base.userid) buyer_count
GROUP BY base.datekey, base.clienttype解析后的AST Tree如下
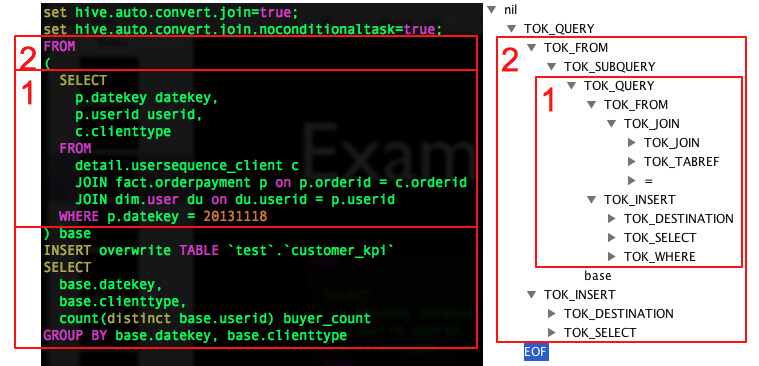
内层子查询也会生成一个TOK_DESTINATION节点,原因是Hive中所有查询的数据均会保存在HDFS临时的文件中,无论是中间的子查询还是查询最终的结果,Insert语句最终会将数据写入表所在的HDFS目录下
子查询 from展开
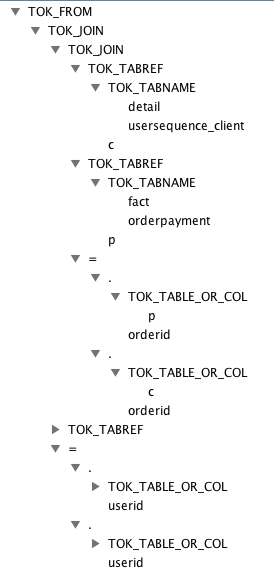
2.翻译成QueryBlock
QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。
简单来讲一个QueryBlock就是一个子查询。
主要属性:
- QB#aliasToSubq(表示QB类的aliasToSubq属性)保存子查询的QB对象,aliasToSubq key值是子查询的别名
- QB#qbp即QBParseInfo保存一个基本SQL单元中的给个操作部分的AST Tree结构,QBParseInfo#nameToDest这个HashMap保存查询单元的输出,key的形式是inclause-i(由于Hive支持Multi Insert语句,所以可能有多个输出),value是对应的ASTNode节点,即TOK_DESTINATION节点。类QBParseInfo其余HashMap属性分别保存输出和各个操作的ASTNode节点的对应关系。
- QBParseInfo#JoinExpr保存TOK_JOIN节点。QB#QBJoinTree是对Join语法树的结构化。
- QB#qbm保存每个输入表的元信息,比如表在HDFS上的路径,保存表数据的文件格式等。
- QBExpr这个对象是为了表示Union操作。
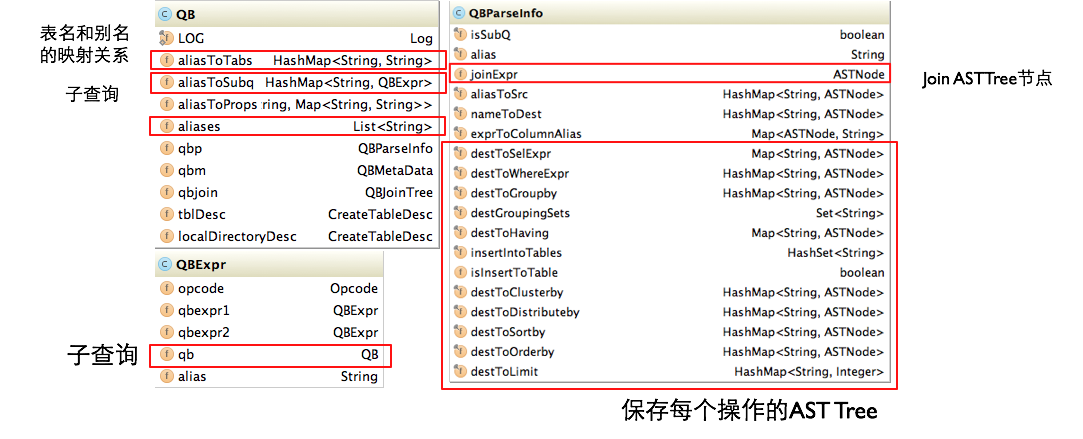
AST Tree生成QueryBlock的过程是一个递归的过程,先序遍历AST Tree,遇到不同的Token节点,保存到相应的属性中,主要包含以下几个过程
- TOK_QUERY => 创建QB对象,循环递归子节点
- TOK_FROM => 将表名语法部分保存到QB对象的
aliasToTabs等属性中 - TOK_INSERT => 循环递归子节点
- TOK_DESTINATION => 将输出目标的语法部分保存在QBParseInfo对象的nameToDest属性中
- TOK_SELECT => 分别将查询表达式的语法部分保存在
destToSelExpr、destToAggregationExprs、destToDistinctFuncExprs三个属性中 - TOK_WHERE => 将Where部分的语法保存在QBParseInfo对象的destToWhereExpr属性中
3.Operator
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
Operator将所有运行时需要的参数保存在OperatorDesc中,OperatorDesc在提交任务前序列化到HDFS上,在MapReduce任务执行前从HDFS读取并反序列化。
转换步骤:
- QB#aliasToSubq => 有子查询,递归调用
- QB#aliasToTabs => TableScanOperator
- QBParseInfo#joinExpr => QBJoinTree => ReduceSinkOperator + JoinOperator
- QBParseInfo#destToWhereExpr => FilterOperator
- QBParseInfo#destToGroupby => ReduceSinkOperator + GroupByOperator
- QBParseInfo#destToOrderby => ReduceSinkOperator + ExtractOperator
Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator
4.逻辑层优化器
| 名称 | 作用 | 思想 |
|---|---|---|
| SimpleFetchOptimizer | 优化没有GroupBy表达式的聚合查询 | 减少shuffle数据量 |
| MapJoinProcessor | MapJoin,需要SQL中提供hint,0.11版本已不用 | 减少shuffle数据量 |
| BucketMapJoinOptimizer | BucketMapJoin | 减少shuffle数据量 |
| GroupByOptimizer | Map端聚合 | 减少shuffle数据量 |
| ReduceSinkDeDuplication | 合并线性的OperatorTree中partition/sort key相同的reduce | Job干尽可能多的事情/合并 |
| PredicatePushDown | 谓词下推 | Job干尽可能多的事情/合并 |
| CorrelationOptimizer | 利用查询中的相关性,合并有相关性的Job,HIVE-2206 | Job干尽可能多的事情/合并 |
| NonBlockingOpDeDupProc | 合并SEL-SEL 或者 FIL-FIL 为一个Operator | Job干尽可能多的事情/合并 |
| ColumnPruner | 字段剪枝 |
5.生成Job
- 对输出表生成MoveTask
- 从OperatorTree的其中一个根节点向下深度优先遍历
- ReduceSinkOperator标示Map/Reduce的界限,多个Job间的界限
- 遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask
- 生成StatTask更新元数据
- 剪断Map与Reduce间的Operator的关系
6.物理层优化器
| 名称 | 作用 |
|---|---|
| SkewJoinResolver | 数据倾斜 |
| SortMergeJoinResolver | 与bucket配合,类似于归并排序 |
| CommonJoinResolver+MapJoinResolver | MapJoin优化器 |
| SamplingOptimizer | 并行order by 优化 |
Mapjoin:
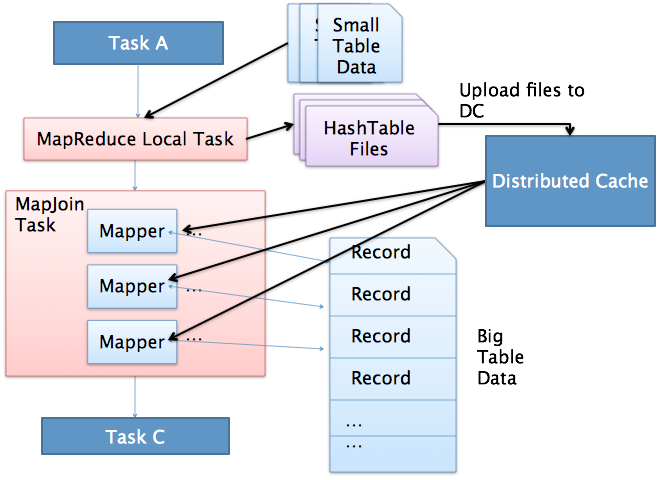
MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。
- 通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会对HashTableFiles进行压缩。
- MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务
- 如果Join的两张表一张表是临时表,就会生成一个ConditionalTask,在运行期间判断是否使用MapJoin
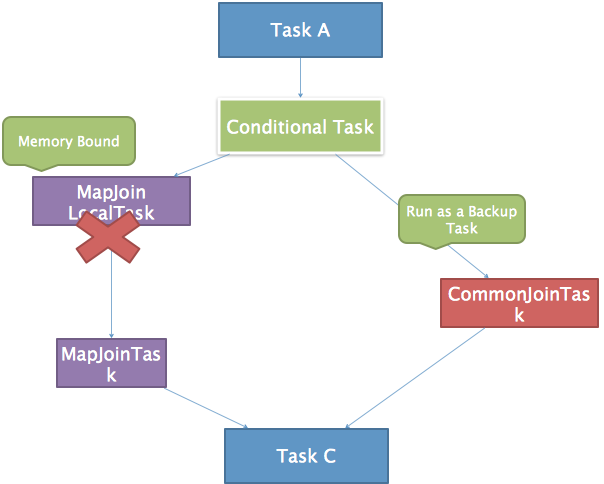
CommonJoinResolver: 对与小表 + 大表 => MapJoinTask,对于小/大表 + 中间表 => ConditionalTask

MapJoinResolver: 将所有有local work的MapReduceTask拆成两个Task
MapReduce
什么是MapRed
MapReduce是一种可用于数据处理的编程框架。MapReduce采用”分而治之“的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
MapRed优缺点
优点:
- 可伸缩性:通过添加更多的计算节点来实现横向扩展,提高系统的处理能力
- 容错性:通过重新执行失败的任务,MapReduce确保了整个计算过程的鲁棒性
- 通用性:可以根据具体的业务需求实现自定义的Map和Reduce函数
- 易编程:编写MapReduce程序相对简单,用户只需实现Map和Reduce两个函数,并且无需关心底层的并行和分布式细节
缺点:
延迟高
不适合迭代算法
不适合实时计算
不适合流式计算
MapRed架构
hadoop 1.x
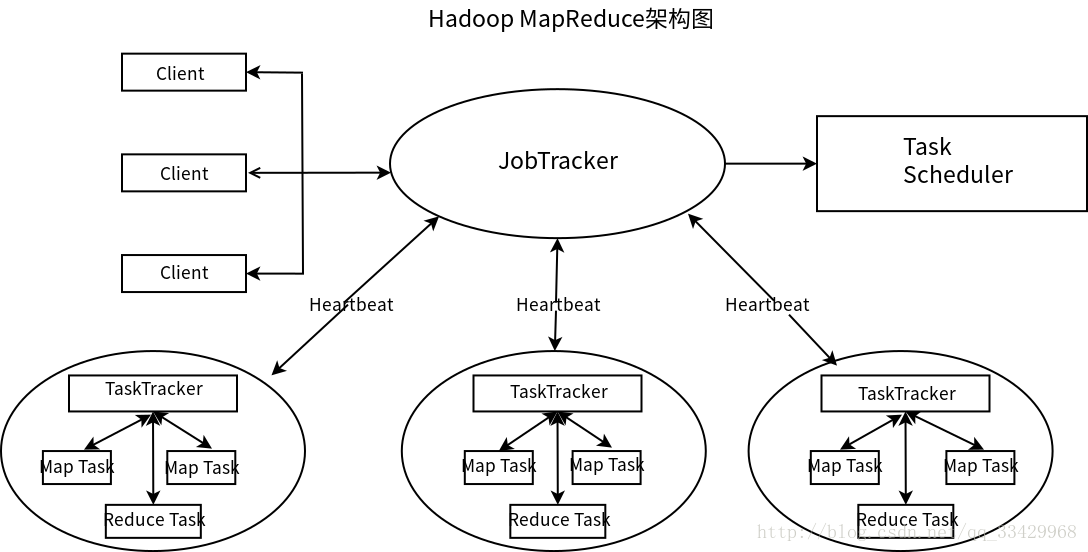
- Client: 用户编写的Map Reduce程序通过Client提交到Job Tracker端;同时 ,用户可以通过Client提供的一些接口查看作业运行状态
- JobTracker: JobTracker主要负责资源监控和作业调度。Job Tracker监控所有的TaskTracker与作业的健康状况,一旦发现失败情况后,会将相应的任务转移到其它节点, 同时Job Tracker会跟踪任务的执行进度、资源使用量等信息
- TaskSheduler:根据jobTracker提供的资源使用信息,判断在资源出现空闲时,选择合适的任务使用这些资源
- TaskTracker: 周期性的通过HeartBeat将资源使用情况和任务执行情况汇报给Job Tracker,同时接受Job Tracker发送过来的命令并执行相应的操作
hadoop 2.x
将任务提交到yarn
主要思想是将资源管理和任务调度/监控独立
MapRed中的Combine是干嘛的?有什么好处
Combine是一种优化技术,用于在Map阶段的本地数据合并,Combine的目的是减少Map阶段输出到Shuffle阶段的数据量,从而减轻网络传输的压力,提高整体性能。
MapRed执行过程
- Input Split:
- 输入数据首先被划分为若干个小的输入分片(Input Split)。
- 输入分片是逻辑上的划分,每个输入分片包含一部分数据。
- Map阶段:
- 每个输入分片都被送到集群中的Map任务。
- Map任务对输入数据进行处理,产生一系列的键值对(Key-Value pairs)。
- 用户编写的Map函数对输入数据进行映射操作,将每个输入记录转换为多个中间键值对。
- Shuffle and Sort阶段:
- Map任务的输出被分区(Partitioned),相同键的数据被分到同一个分区。
- 各个Map任务的输出被传输到集群中的Reduce任务,这个过程称为Shuffle。
- 中间数据进行本地排序,以确保相同键的数据相邻。这个排序是为了方便Reduce任务的处理。
- Combine(可选):
- 在Shuffle阶段之后,可以选择使用Combine操作,对相同键的数据进行本地合并。这是一个优化步骤,旨在减少Shuffle阶段传输到Reduce任务的数据量。
- Reduce阶段:
- 中间数据按照键被传送到相应的Reduce任务。
- Reduce任务对接收到的数据进行归并(Merge)和排序。
- 用户编写的Reduce函数对数据执行归约(Reduce)操作,产生最终的输出结果。
- Output:
- Reduce任务的输出被写入到分布式文件系统(如HDFS)中,作为最终的结果。
- 用户可以从分布式文件系统中检索和使用MapReduce作业的输出。
map端shuffle过程
1.partition
在将map()函数处理后得到的(key,value)对写入到缓冲区之前,需要先进行分区操作,这样就能把map任务处理的结果发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜,默认HashPartitioner
2.写入环形内存缓冲区
- 频繁的磁盘I/O操作会严重的降低效率
- 做一些预排序以提高效率
“中间结果”不会立马写入磁盘,而是优先存储到map节点的”环形内存缓冲区”
当写入的数据量达到预先设置的阙值后便会执行一次I/O操作将数据写入到磁盘
每个map任务都会分配一个环形内存缓冲区,用于存储map任务输出的键值对(默认大小100MB,mapreduce.task.io.sort.mb调整)
3.执行溢写出spill
- 一旦缓冲区内容达到阈值(
mapreduce.map.io.sort.spill.percent,默认0.80,或者80%),就会会锁定这80%的内存 - 每个分区中对其中的键值对按键进行sort排序,具体是将数据按照partition和key两个关键字进行排序,排序结果为缓冲区内的数据按照partition为单位聚集在一起,同一个partition内的数据按照key有序
- 排序完成后会创建一个溢出写文件(临时文件),然后开启一个后台线程把这部分数据以一个临时文件的方式溢出写(spill)到本地磁盘中
- 如果客户端自定义了Combiner(相当于map阶段的reduce),则会在分区排序后到溢写出前自动调用combiner,将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量。这个过程叫“合并”
- 剩余的20%的内存在此期间可以继续写入map输出的键值对
4.merge
- 当一个map task处理的数据很大,以至于超过缓冲区内存时,就会生成多个spill文件。此时就需要对同一个map任务产生的多个spill文件进行归并生成最终的一个已分区且已排序的大文件。配置属性
mapreduce.task.io.sort.factor控制着一次最多能合并多少流,默认值是10。 - 这个过程包括排序和合并(可选),归并得到的文件内键值对有可能拥有相同的key,这个过程如果client设置过Combiner,也会合并相同的key值的键值对.
- 溢出写文件归并完毕后,Map将删除所有的临时溢出写文件,并告知NodeManager任务已完成,只要其中一个MapTask完成,ReduceTask就开始复制它的输出(Copy阶段分区输出文件通过http的方式提供给reducer)。
reduce端shuffle过程
1.复制copy 拉取数据
Reduce进程启动一些数据copy线程,通过HTTP方式(低延迟,小规模数据传输)请求MapTask所在的NodeManager以获取输出文件。 NodeManager需要为分区文件运行reduce任务。并且reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。而每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。
reduce任务有少量复制线程,因此能够并行取得map输出。默认线程数为5,但这个默认值可以通过mapreduce.reduce.shuffle.parallelcopies属性进行设置
2.merge阶段
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。
Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。
与map端的溢写类似,在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。
Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程,采取的排序方法跟map阶段不同,因为每个map端传过来的数据是排好序的,因此众多排好序的map输出文件在reduce端进行合并时采用的是归并排序,针对键进行归并排序。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
3.reduce
当一个reduce任务完成全部的复制和排序后,就会针对已根据键排好序的Key构造对应的Value迭代器。这时就要用到分组,默认的根据键分组,自定义的可是使用 job.setGroupingComparatorClass()方法设置分组函数类。对于默认分组来说,只要这个比较器比较的两个Key相同,它们就属于同一组,它们的 Value就会放在一个Value迭代器,而这个迭代器的Key使用属于同一个组的所有Key的第一个Key。
在reduce阶段,reduce()方法的输入是所有的Key和它的Value迭代器。
4.output
Reduce阶段的输出直接写到输出文件系统,一般为HDFS。如果采用HDFS,由于NodeManager也运行数据节点,所以第一个块副本将被写到本地磁盘
MapRed实现如何实现join
1.mapjoin
distributeCache
2.reducejoin
MapRed运行过程中会容易发生OOM的地方
1.Map阶段OOM
概率相对较低,除非逻辑复杂或代码问题
2.Reduce阶段OOM
- 数据倾斜
- value对象过大
3.MRAppMaster OOM
产生的job过多
reduce任务什么时候开始
默认当map完成5%时启动reduce任务,mapred.reduce.slowstart.completed.maps 参数可以控制
shuffle排序算法
spill阶段:整体是一个快排,当长度小于13 时使用选择排序 或者 深度大于(32 - Integer.numberOfLeadingZeros(length - 1)) << 2时使用堆排序
merge阶段:归并排序
shuffle为什么要排序
- reduce 需要对数据进行分组,将相同key放在一起规约,相比于hashMap 排序在数据量上的限制,且不用标记哪些key处理了哪些没有
- map端排序 可以减轻reduce的排序压力
- 便于combiner操作
shuffle 为什么使用环形缓冲区
- 数据结构相对简单
- 判断缓冲区占用情况容易
- 存取数据效率高
shuffle详解
元数据内容(4个int字节 16byte)
- value offset
- Key offset
- parition
- Value length
图解shuffle url
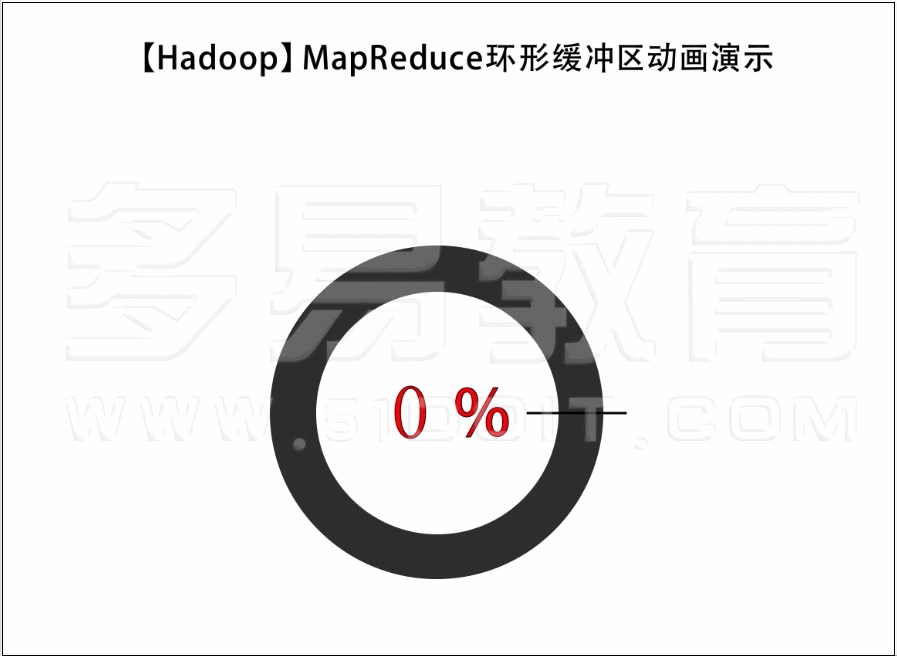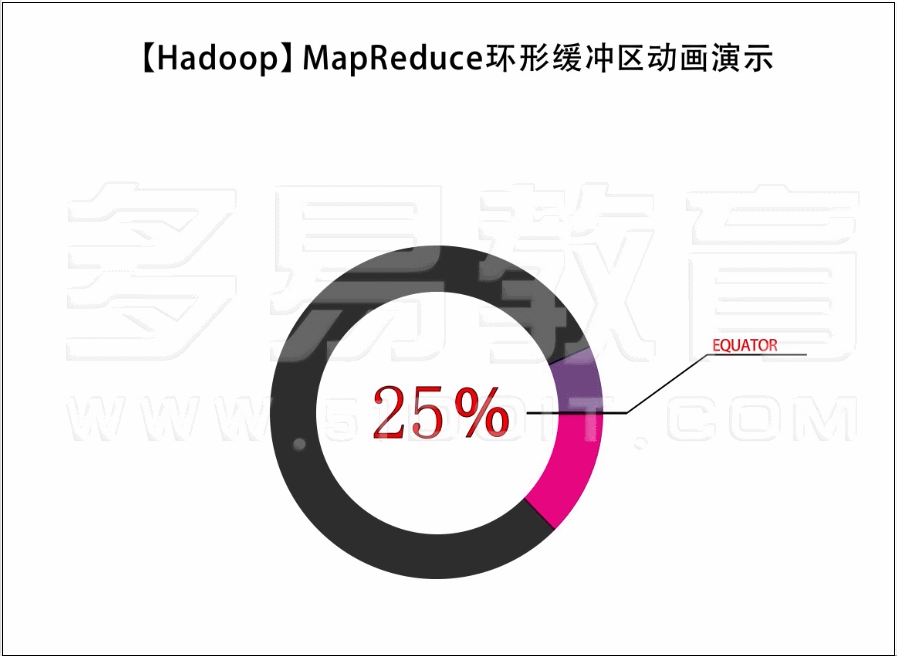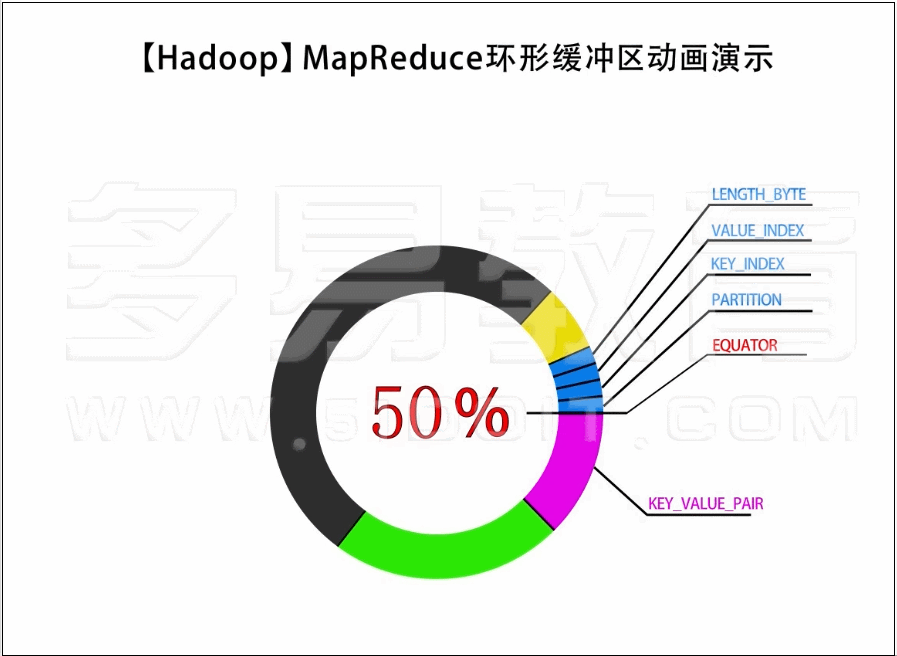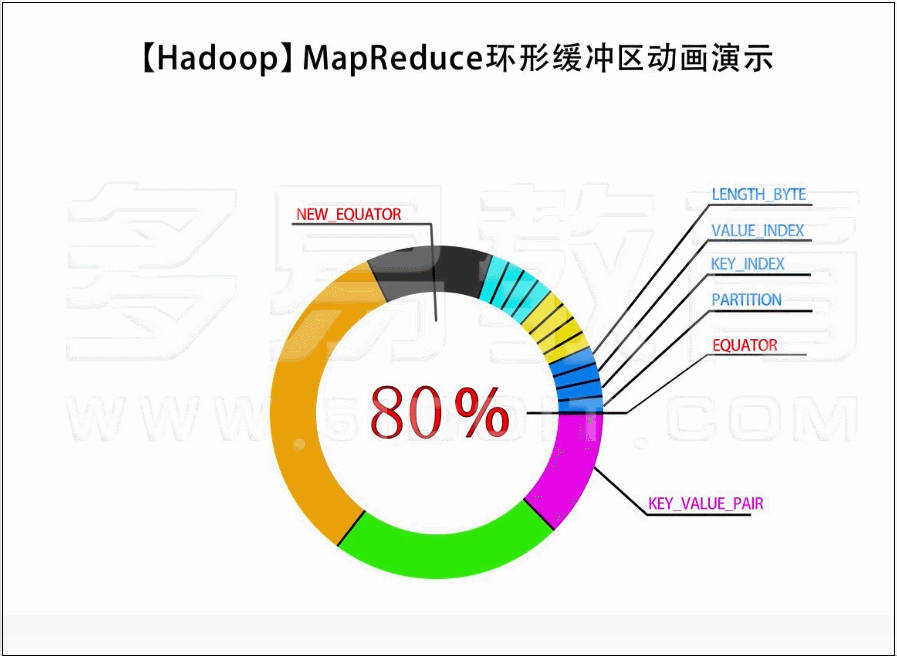
Map shuffle端
- 数据经过partition到 collect
- 判断是否需要溢写或者溢写完成需要恢复指针位置
- 如果需要溢写并且没有正在溢写就异步启动溢写
- 溢写过程 1️⃣对kv元数据进行排序
- 溢写过程2️⃣执行conbiner如果需要
- 溢写过程3️⃣按照reducer个数每个reducer一个文件将文件落盘 (即使没有数据也会创建文件)
- 溢写过程4️⃣索引数据缓存在内存中或落盘
- 如果需要溢写并且没有正在溢写就异步启动溢写
- 开始序列化k,v,以及元数据
- 序列化k完成就判断kv元数据是否绕环(物理结构是byte数组,数据结构是环状,可能会出现元数据处于数组收尾连接处),如果过绕环需要避免,会影响元数据排序
- 序列化k或者v前都需要再次检查是否需要溢写,这里会出现的情况是
- 1️⃣已经开始异步溢写了但是主线程又把剩下20%都写完了
- 2️⃣没有发生溢写但是当前这条数据比较大需要触发溢写
- 3️⃣尝试溢写后这条数据都写不下
- 针对1️⃣ 2️⃣情况就阻塞方式溢写,针对3️⃣就抛异常然后外部捕获将这条数据单独溢写
- 如果以上情况都不满足说明缓存空间充足,直接写到缓存里面
- 没有数据了开始flush
- 将内存中的数据最后一次溢写出去
- 归并排序,合并溢写出的文件
- 再次执行combiner,如果需要
- 生成结果文件,并删除之前spill的临时文件
- finish
缓冲区变量定义
//写入kv元数据的buffer
//kvbuffer包装的
private IntBuffer kvmeta; // metadata overlay on backing store
// 初始化 为kvstart = kvend =kvindex
// 溢写完成后kvstart = kvend
// resetSpill kvstart = kvend=( equator - METASIZE )/16
int kvstart; // marks origin of spill metadata // meta的start
// meta的end,初始值为kvindex ,在没有溢写的情况下 kvbend + METASIZE = equator
// 在溢写开始的时候kvend= (kvindex + NMETA)
int kvend; // marks end of spill metadata
// 初始化时是 ( equator - METASIZE )/16 ,每写一条数据往前偏移4
int kvindex; // marks end of fully serialized records
// 元数据和kv数据的分割线
int equator; // marks origin of meta/serialization
//初始化 bufstart =equator
// 溢写完成后 bufstart = bufend
//resetSpill bufstart = bufend= equator
int bufstart; // marks beginning of spill
//开始溢写时 bufend = bufmark
int bufend; // marks beginning of collectable
// 每写完一条kv数据后标记 bufmark = bufindex
int bufmark; // marks end of record
//写入多少kv数据加多少
int bufindex; // marks end of collected
//kvbuffer.length
//当写入kv元数据绕环的时候 bufvoid可能会减小
int bufvoid; // marks the point where we should stop
// reading at the end of the buffer
//环形缓冲区 就是一个byte数组
byte[] kvbuffer; // main output buffer
private final byte[] b0 = new byte[0];
//kv元数据 第一个 value offset
private static final int VALSTART = 0; // val offset in acct
//kv元数据 第二个 key offset
private static final int KEYSTART = 1; // key offset in acct
//kv元数据 第三个 partition
private static final int PARTITION = 2; // partition offset in acct
//kv元数据 第四个 value 长度
private static final int VALLEN = 3; // length of value
private static final int NMETA = 4; // num meta ints
private static final int METASIZE = NMETA * 4; // size in bytes
// spill accounting
private int maxRec; // 缓存区所有数据存meta数据,最多能存多少个,用来取余用的(环形)
private int softLimit; // 缓存数据量限制 默认为实际byte大小80% 超过阈值开始溢写
boolean spillInProgress; // 标识是否在溢写
int bufferRemaining; // 初始化的值为softLimit ,每写一条meta 或者kv数据都会 减去对应的长度, 在溢写时就是剩下的长度部分参数初始化
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8); // 溢写阈值参数
final int sortmb = job.getInt(MRJobConfig.IO_SORT_MB,
MRJobConfig.DEFAULT_IO_SORT_MB); // 缓冲区大小 默认100MB 最大不超过2047
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT); //索引限制 默认1024*1024
spillFilesCountLimit = job.getInt(JobContext.SPILL_FILES_COUNT_LIMIT,
SPILL_FILES_COUNT_LIMIT_DEFAULT); //溢写文件数限制,默认没有限制
...
int maxMemUsage = sortmb << 20; // 将MB换算成byte
maxMemUsage -= maxMemUsage % METASIZE; // ?? 与16的倍数对齐 但是 <<20 已经对齐了
kvbuffer = new byte[maxMemUsage]; // 初始化缓冲区
bufvoid = kvbuffer.length; // 设置bufvoid 为缓冲区长度
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer(); // 包装kvmeta
setEquator(0); //设置equator和kvindex
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA;
softLimit = (int)(kvbuffer.length * spillper);
bufferRemaining = softLimit;
private void setEquator(int pos) {
// 设置分界线为0
equator = pos;
// 对齐操作
final int aligned = pos - (pos % METASIZE);
// 设置kvindex 为缓冲区长度-metasize 也就是 分界线反向第一个
kvindex = (int)(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
}collect 写数据部分代码
public synchronized void collect(K key, V value, final int partition) throws IOException {
.....
// bufferRemaining 剩余容量减去一条元数据容量
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
spillLock.lock();
try {
do { // do{ .. }while(false) 只循环一次 但中间使用break 或continue 可以提前跳出循环
if (!spillInProgress) { //判断是否正在spill
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// 占用的数据是 kvindex --> bufindex
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// 溢写完成了 重置 kvstart = kvend=( equator - METASIZE )/16
// bufstart = bufend= equator
resetSpill();
bufferRemaining = Math.min(distanceTo(bufindex, kvbidx) - 2 * METASIZE,softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// 开始溢写 异步操作
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
//根据每条数据平均大小估算新的分界线位置,但是至少会留一半数据给存数据
final int newPos = (bufindex +Math.max(2 * METASIZE - 1, Math.min(distkvi / 2,distkvi / (METASIZE + avgRec) * METASIZE)))% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
bufferRemaining = Math.min(distanceTo(bufend, newPos), Math.min(distanceTo(newPos, serBound),softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
try {
// serialize key bytes into buffer
int keystart = bufindex;
//序列化key
keySerializer.serialize(key);
if (bufindex < keystart) {
// 绕环发生 调整元数据位置 保证kv元数据在 byte数组上连续
bb.shiftBufferedKey();
keystart = 0;
}
final int valstart = bufindex;
// 序列化value
valSerializer.serialize(value);
bb.write(b0, 0, 0);
// 标记 bufmark 值为 bufindex
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
// 写kv元数据
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
//每写一个kv元数据将kvindex往前偏移4 , 呈现的效果就是 kv元数据从分界线反向写,kv数据在从分界线正向写
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
// 如果一条数据超过缓冲区限制 就直接把这条数据溢写
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}write部分代码
//Serializer.serialize 最终会调用到这里
public void write(byte b[], int off, int len) throws IOException {
bufferRemaining -= len;
//到这里谁然还没有写meta但是bufferRemaining已经减去了meta的长度
if (bufferRemaining <= 0) {
//数据写不下了 阻塞溢写
boolean blockwrite = false;
spillLock.lock();
try {
do {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
final int distkvi = distanceTo(bufindex, kvbidx);
final int distkve = distanceTo(bufindex, kvbend);
// distkvi <= distkve 没有发生溢写 ,如果放不下当前数据和下一条数据meta就阻塞溢写 ,放不下就阻塞
// distkvi <= distkve 看剩余的空间能不能写的下当前数据和下一条数据meta,放不下就阻塞
blockwrite = distkvi <= distkve
? distkvi <= len + 2 * METASIZE
: distkve <= len || distanceTo(bufend, kvbidx) < 2 * METASIZE;
if (!spillInProgress) {
if (blockwrite) {
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
resetSpill(); // resetSpill doesn't move bufindex, kvindex
bufferRemaining = Math.min(
distkvi - 2 * METASIZE,
softLimit - distanceTo(kvbidx, bufindex)) - len;
continue;
}
if (kvindex != kvend) {
startSpill();
setEquator(bufmark);
} else {
//数据太长,报异常外面再捕获,然后单条数据溢写
final int size = distanceTo(bufstart, bufindex) + len;
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
bufvoid = kvbuffer.length;
throw new MapBufferTooSmallException(size + " bytes");
}
}
}
if (blockwrite) {
// wait for spill
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException(
"Buffer interrupted while waiting for the writer", e);
}
}
} while (blockwrite);
} finally {
spillLock.unlock();
}
}
// 缓冲区空间足够 正常写到缓冲区
if (bufindex + len > bufvoid) {
final int gaplen = bufvoid - bufindex;
System.arraycopy(b, off, kvbuffer, bufindex, gaplen);
len -= gaplen;
off += gaplen;
bufindex = 0;
}
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
}
}sortAndSpill部分代码
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
FSDataOutputStream out = null;
FSDataOutputStream partitionOut = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
//mstart mend 递增为1
final int mstart = kvend / NMETA;
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
// 对元数据排序
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
int spindex = mstart;
final IndexRecord rec = new IndexRecord();
final InMemValBytes value = new InMemValBytes();
for (int i = 0; i < partitions; ++i) {
//每个partition一个文件,这里的partitions其实是指下游reducer个数
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
partitionOut =
IntermediateEncryptedStream.wrapIfNecessary(job, out, false,
filename);
writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);
int keystart = kvmeta.get(kvoff + KEYSTART);
int valstart = kvmeta.get(kvoff + VALSTART);
key.reset(kvbuffer, keystart, valstart - keystart);
getVBytesForOffset(kvoff, value);
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// 分区没数据就不执行combiner
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
// 每次溢写都会执行combiner
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
if (partitionOut != out) {
partitionOut.close();
partitionOut = null;
}
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
// 索引信息优先缓存在内存 如果长度太大就写索引文件落盘
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
IntermediateEncryptedStream.addSpillIndexFile(indexFilename, job);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
incrementNumSpills();
} finally {
if (out != null) out.close();
if (partitionOut != null) {
partitionOut.close();
}
}
}flush部分代码
public void flush() throws IOException, ClassNotFoundException,InterruptedException {
spillLock.lock();
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
checkSpillException();
final int kvbend = 4 * kvend;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished
resetSpill();
}
if (kvindex != kvend) {
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
// 溢写线程 主要执行也是 该方法完成溢写 ,这里已经没有后续数据了,将内存中的数据spill出去
sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
spillLock.unlock();
}
.....
kvbuffer = null;
//归并排序,合并溢写出的文件
//再次执行combiner
//生成结果文件,并删除之前spill的临时文件
mergeParts();
.....
}kv元数据排序
@Override
public int compare(final int mi, final int mj) {
final int kvi = offsetFor(mi % maxRec);
final int kvj = offsetFor(mj % maxRec);
final int kvip = kvmeta.get(kvi + PARTITION);
final int kvjp = kvmeta.get(kvj + PARTITION);
//先按照分区,再按照key排序
//外层排序算法就是前面的QuickSorter,优先用快排,长度变短以后用选择排序,递归层数多了用堆排序
// sort by partition
if (kvip != kvjp) {
return kvip - kvjp;
}
// sort by key
return comparator.compare(kvbuffer,
kvmeta.get(kvi + KEYSTART),
kvmeta.get(kvi + VALSTART) - kvmeta.get(kvi + KEYSTART),
kvbuffer,
kvmeta.get(kvj + KEYSTART),
kvmeta.get(kvj + VALSTART) - kvmeta.get(kvj + KEYSTART));
}HDFS
block、packet与chunk
- block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由
dfs.blocksize参数决定 默认128mb - packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以
dfs.client-write-packet-size参数为参考值,默认64kb。 注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值; - chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
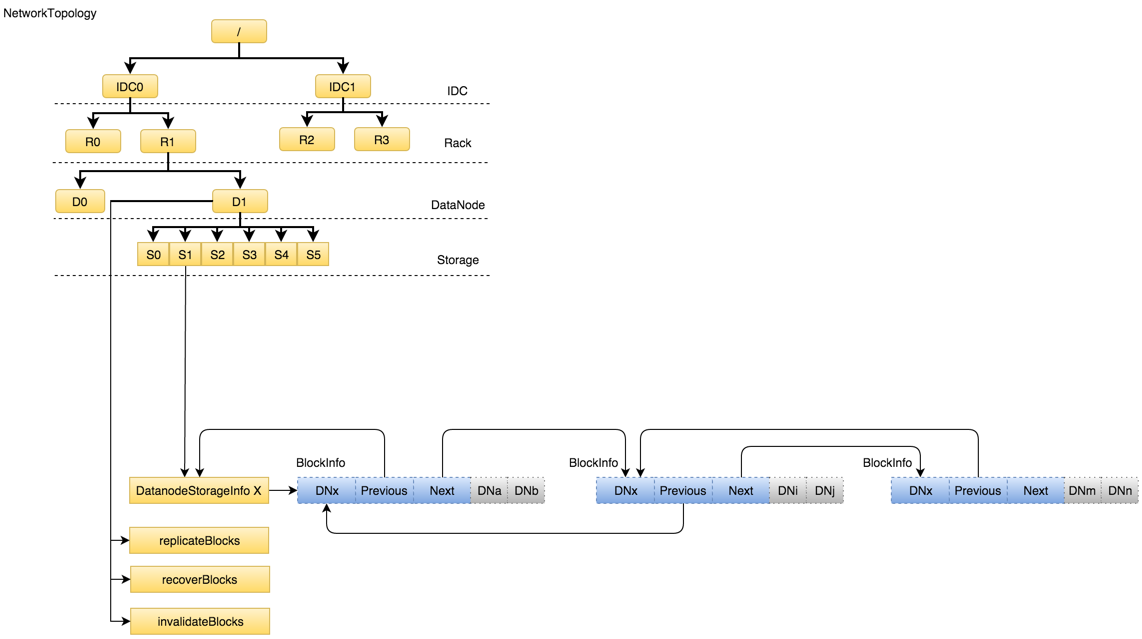
NameNode内存全景
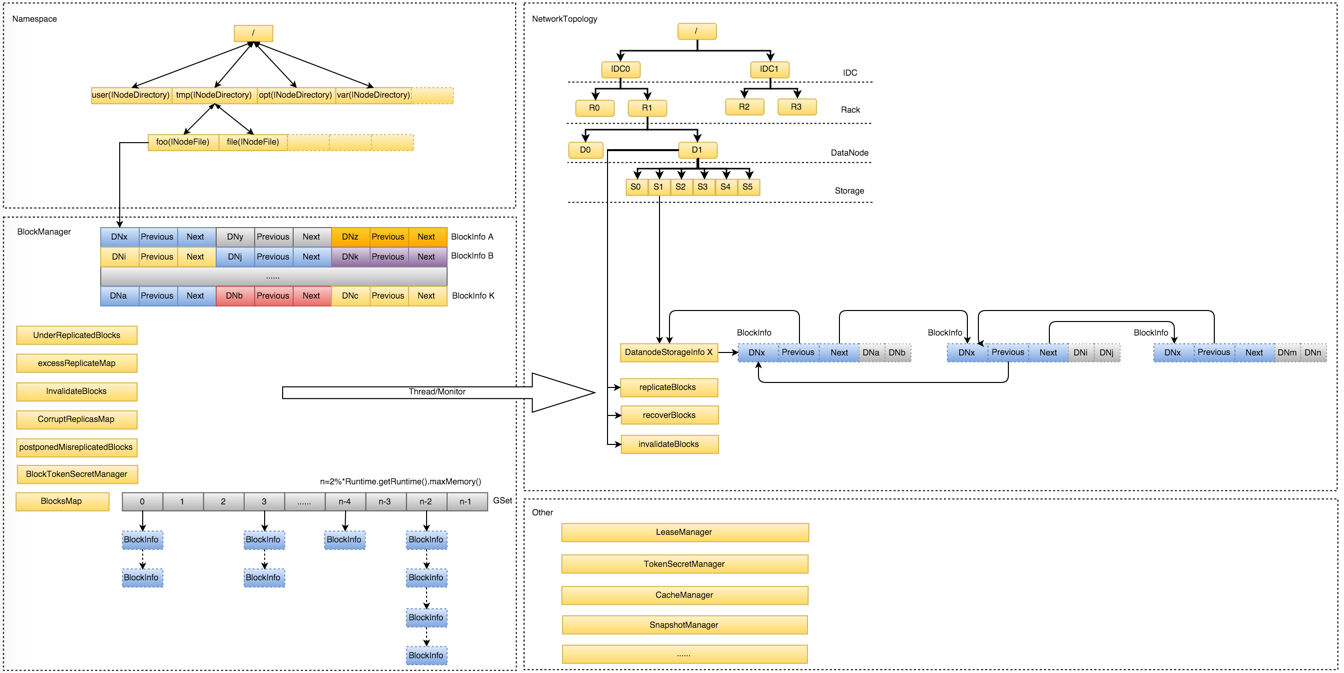
- Namespace:维护整个文件系统的目录树结构及目录树上的状态变化
- BlockManager:维护整个文件系统中与数据块相关的信息及数据块的状态变化
- NetworkTopology:维护机架拓扑及DataNode信息,机架感知的基础
- 其它:
- LeaseManager:读写的互斥同步就是靠Lease实现,支持HDFS的Write-Once-Read-Many的核心数据结构;
- CacheManager:Hadoop 2.3.0引入的集中式缓存新特性,支持集中式缓存的管理,实现memory-locality提升读性能;
- SnapshotManager:Hadoop 2.1.0引入的Snapshot新特性,用于数据备份、回滚,以防止因用户误操作导致集群出现数据问题
- DelegationTokenSecretManager:管理HDFS的安全访问; 另外还有临时数据信息、统计信息metrics等等。
Namespace和BlockManager占用内存空间较大
Namespace
namespace保存了目录树及每个目录/文件节点的属性。
除在内存常驻外,这部分数据会定期flush到持久化设备上,生成一个新的FsImage文件,方便NameNode发生重启时,从FsImage及时恢复整个Namespace
Namespace目录树中存在两种不同类型的INode数据结构:INodeDirectory和INodeFile。其中INodeDirectory标识的是目录树中的目录,INodeFile标识的是目录树中的文件。由于二者均继承自INode,所以具备大部分相同的公共信息INodeWithAdditionalFields
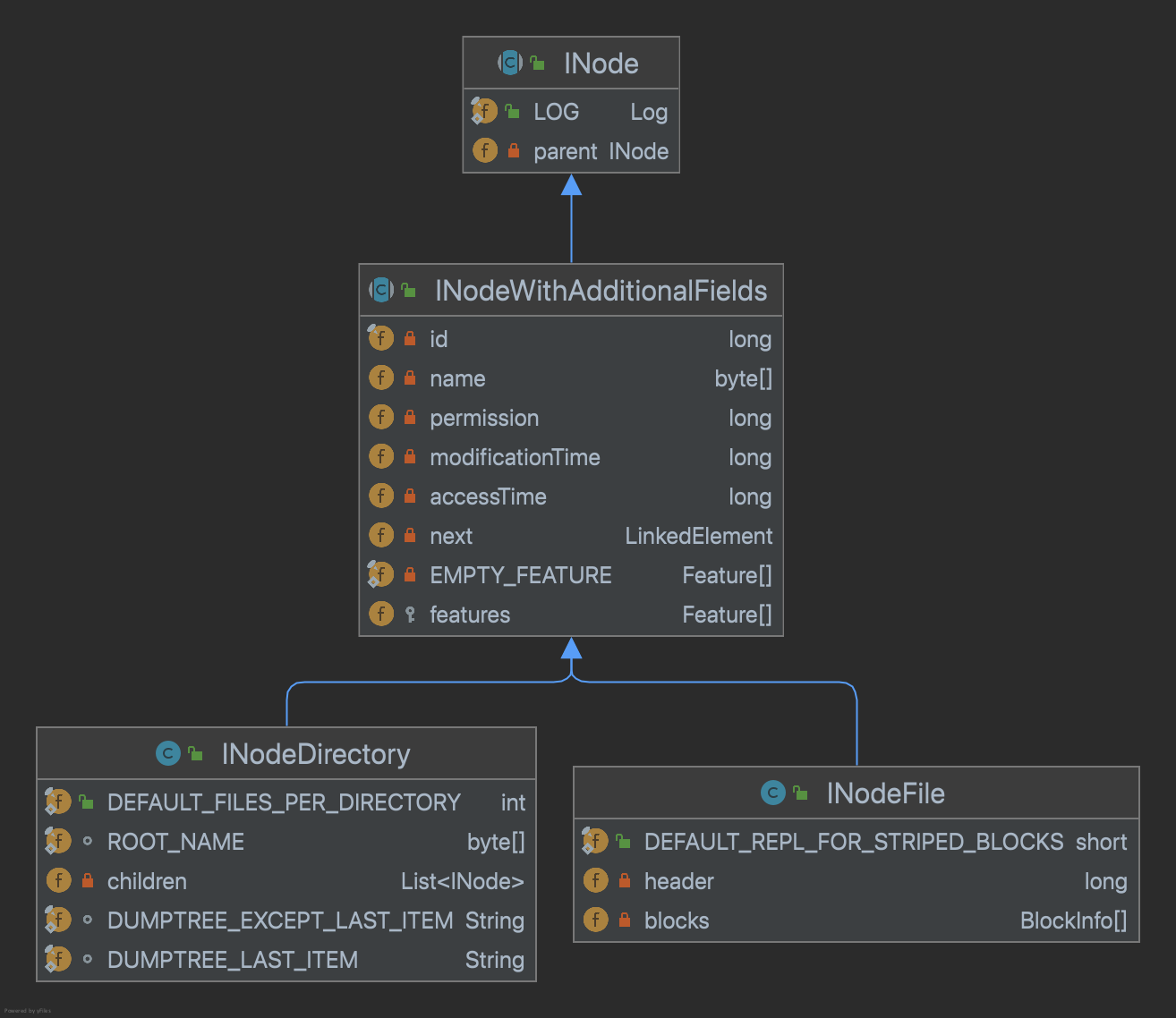
INodeFile.header:
[4 bits storagePolicyID] [12 bits BLOCK_LAYOUT_AND_REDUNDANCY] [48 bits preferredBlockSize]
storagePolicyID:存储策略
BLOCK_LAYOUT_AND_REDUNDANCY:块布局和冗余信息,如果最高位为 0,表示这是一个副本块,接下来的 11 位存储副本的数量,如果最高位为 1,表示这是一个纠删码块,接下来的 11 位存储纠删码策略的唯一标识符
preferredBlockSize:表示块的首选大小,即预期的块大小
INodeDirectory.children:是默认大小为5的ArrayList,按照子节点name有序存储,虽然在插入时会损失一部分写性能,但是可以方便后续快速二分查找提高读性能
BlockManager
Namespace与BlockManager之间通过前面提到的INodeFile有序Blocks数组关联到一起
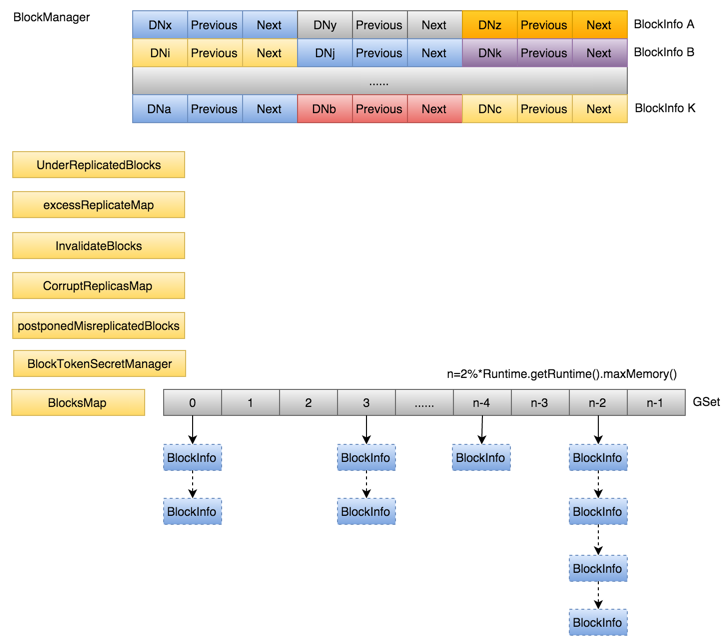
BlockInfo几块重要信息:文件包含了哪些Block,这些Block分别被实际存储在哪些DataNode上,DataNode上所有Block前后链表关系。
BlocksMap:LightWeightGSet<Block, BlockInfo>, 通过blockid(hashcode)快速定位Block,本质是一个链式解决冲突的哈希表。为了避免rehash过程带来的性能开销,初始化时,索引空间直接给到了整个JVM可用内存的2%,并且不再变化。
数据块与数据节点的对应关系并不持久化在fsimage文件中, 而是由Datanode定期块汇报到Namenode, 然后Namenode重建内存中数据块与数据节点的对应关系。
Datanode启动后, 会与Namenode握手、 注册以及向Namenode发送第一次全量块汇报, 全量块汇报中包含了Datanode上存储的所有副本信息。 之后, Datanode的BPServiceActor对象会以dfs.blockreport.intervalMsec(默认是6个小时) 间隔向Namenode发送全量块汇报, 同时会以100*heartBeatInterval(心跳间隔的100倍, 默认为300秒) 间隔向Namenode发送增量块汇报, 增量块汇报中包含了Datanode最近新添加的以及删除的副本信息
NetworkTopology
网络拓扑结构
数据量增长后的问题
启动时间变长
性能开始下降。HDFS文件系统的所有元数据相关操作基本上均在NameNode端完成,当数据规模的增加致内存占用变大后,元数据的增删改查性能会出现下降
NameNode JVM FGC(Full GC)风险较高
数据量增涨解决办法
Federation方案:通过对NameNode进行水平扩展分散单点负载的方式解决NameNode的问题
元数据管理通过主从架构的集群形式提供服务,或者借助高速存储设备,将元数据通过外存设备进行持久化存储,保持NameNode完全无状态
合并小文件,调整合适的BlockSize
Snapshot 快照
HDFS快照(Snapshots)是文件系统在某一时刻的只读副本。快照可以在文件系统的一个分支或者整个文件系统上生成。快照常用来备份数据,防止错误性的操作。
- 快照的创建是瞬时的:时间复杂度为O(1),不包括INode查找时间。
- 仅当修改快照相关的数据时才会使用额外的内存,当修改文件时会拷贝一个备份数据(占据额外空间),删除文件操作(占据额外空间)是block不会删除,仅删除元数据
- 如果一个目录的父目录或者子目录是快照目录,则不能将该目录设置为快照
- 对于一个快照目录,访问时需要添加/.snapshot后缀。例如,如果/foo是一个快照目录,/foo/bar是/foo下的文件或者目录,/foo有一个快照s0,则/foo/.snapshot/s0/bar是/foo/bar的快照副本。
INode.Future实现
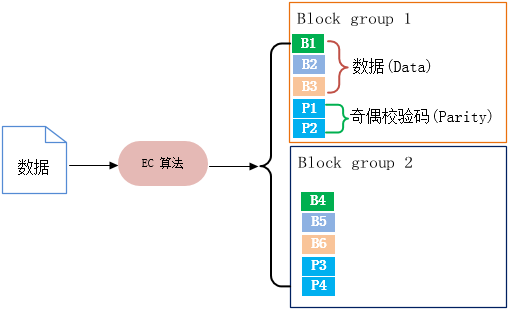
纠删码(Erasure Coding)
Hadoop 3.0 开始支持 纠删码(EC)存储
EC由数据(Data)和奇偶校验码(Parity)两部分组成,数据存储时通过EC算法生成;生成的过程称为编码(encoding),恢复丢失数据块的过程称为解码(decoding)。
EC的构成单位:块组(Block group)、块(Block)、单元(cell),每个块组存放与其它块组一样数量的数据块和奇偶校验码块;单元(cell)是EC内部最小的存储结构,多个单元组成条(Striping),存储在块(Block)里
副本和EC优点
- 副本的优点:
- 简单易实现: 副本技术是最简单的冗余技术之一,容易实现和管理。
- 读取速度快: 由于数据存储在多个副本中,读取操作可以并行进行,从而提高了读取速度。
- 故障恢复简单: 当某个副本损坏或不可用时,可以从其他副本中快速恢复数据。
- 灵活性高: 可以根据需要调整副本数量,以平衡性能和容错能力。
- 副本的缺点:
- 存储成本高: 副本技术需要存储额外的数据副本,因此存储成本较高。
- 空间利用率低: 由于数据的多个副本存储在不同的位置,导致空间利用率低下。
- 写入性能差: 写入操作需要同时复制数据到多个副本,因此写入性能相对较差。
- 不适合大规模存储: 当数据量较大时,副本技术的成本和复杂性会变得不可控制。
- 纠删码的优点:
- 存储成本低: 纠删码技术可以提供与副本相同的容错能力,但只需存储额外的冗余数据片段,因此存储成本较低。
- 空间利用率高: 纠删码技术可以根据需求配置不同的参数,以提高数据的空间利用率。
- 高容错能力: 纠删码技术可以容忍多个数据片段的损坏或丢失,从而提供更高的容错能力。
- 适合大规模存储: 纠删码技术特别适用于大规模存储系统,可以提供高效的数据保护和存储。
- 纠删码的缺点:
- 计算成本高: 纠删码技术需要进行复杂的计算,因此写入和恢复操作的计算成本相对较高。
- 读取性能较差: 由于需要计算恢复数据,读取操作的性能可能受到影响,特别是在某些故障情况下。
- 实现复杂性高: 相对于副本技术,纠删码技术的实现和管理相对复杂,需要更多的系统资源和技术支持。
LeaseManager
租约是Namenode给予租约持有者(LeaseHolder, 一般是客户端) 在规定时间内拥有文件权限(写文件) 的合同。
HDFS文件是write-once-read-many, 并且不支持客户端的并行写操作。 HDFS提供了租约(Lease) 机制保证对HDFS文件的互斥操作来实现这个功能,
在HDFS中, 客户端写文件时需要先从租约管理器(LeaseManager) 申请一个租约,成功申请租约之后客户端就成为了租约持有者, 也就拥有了对该HDFS文件的独占权限,其他客户端在该租约有效时无法打开这个HDFS文件进行操作。 Namenode的租约管理器保存了HDFS文件与租约、 租约与租约持有者的对应关系, 租约管理器还会定期检查它维护的所有租约是否过期。 租约管理器会强制收回过期的租约, 所以租约持有者需要定期更新租约(renew), 维护对该文件的独占锁定。 当客户端完成了对文件的写操作, 关闭文件时, 必须在租约管理器中释放租。
整个过程可能发生两类问题:(1)写文件过程中客户端没有及时更新Lease时间;(2)写完文件后没有成功释放Lease。两个问题分别对应为softLimit(1min)和hardLimit(1hour)。两种场景都会触发LeaseManager对Lease超时强制回收。如果客户端写文件过程中没有及时更新Lease超过softLimit时间后,另一客户端尝试对同一文件进行写操作时触发Lease软超时强制回收;如果客户端写文件完成但是没有成功释放Lease,则会由LeaseManager的后台线程LeaseManager.Monitor检查是否硬超时后统一触发超时回收。
HDFS安全模式
HDFS 文件系统的一种特殊状态,在该状态下,hdfs 文件系统只接受读数据请求,而不接受删除、修改等变更请求,当然也不能对底层的 block 进行副本复制等操作。
进入安全模式场景
- 执行命令进入:
hdfs dfsadmin -safemode enter/get/leave - 主动进入:
- 跟 namenode 保持定期心跳的 datanode 的个数没有达到指定的阈值, 阈值通过参数 dfs.namenode.safemode.min.datanodes 指定
- HDFS 底层达到了最小副本数要求的 block 的百分比没有达到指定的阈值(0.999) ,达到比例后30s退出安全模式
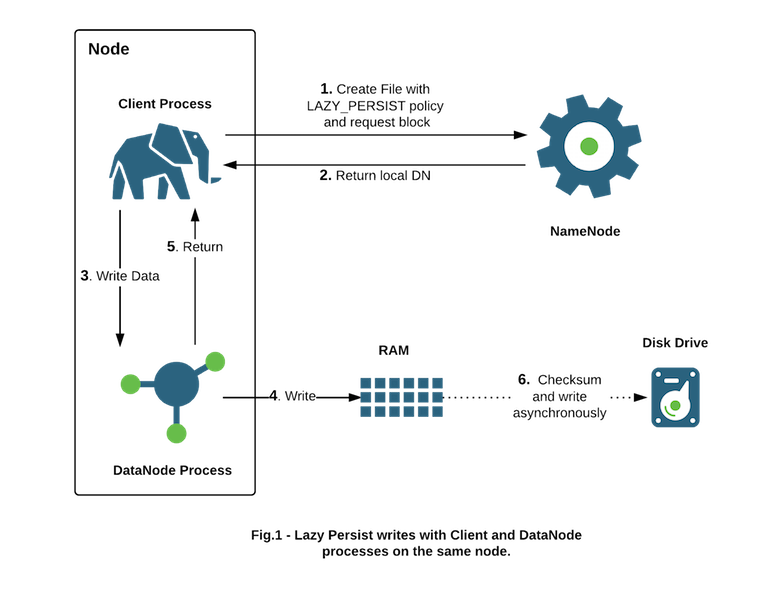
LAZY_PERSIST策略
HDFS 支持写入由数据节点管理的堆外内存。 数据节点会将内存中的数据异步刷新到磁盘,从而从性能敏感的 IO 路径中删除昂贵的磁盘 IO 和校验和计算,因此我们将此类写入称为“惰性持久写入”。 HDFS 为惰性持久写入提供尽力而为的持久性保证。 如果在将副本保存到磁盘之前重新启动节点,则可能会发生罕见的数据丢失。 应用程序可以选择使用延迟持久写入来权衡一些持久性保证,以减少延迟。
Mount the RAM Disk partition with the Unix mount command
sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/
hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>
fs.setStoragePolicy(path, "LAZY_PERSIST");NameNodeRetryCache
是Hadoop HDFS中的一个重试缓存机制,它的主要目的是为了处理客户端在进行某些操作时因为网络或其他原因失败后,可以在一定时间内进行重试而不用重新执行整个操作。
该机制的实现原理如下:
- 缓存记录: 当客户端发起某个需要重试的操作(比如创建文件)时,NameNode会为该操作生成一个唯一的事务ID,并将事务ID和相关的操作信息记录到
NameNodeRetryCache中。 - 缓存存储: 缓存的存储是在
FSDirectory中实现的。NameNode会维护一个NameNodeRetryCache的实例,用于存储和管理重试缓存。 - 重试时检查: 当客户端在一定时间内发起重试时,NameNode会检查重试请求中的事务ID是否在缓存中。如果事务ID存在,说明之前的操作已经执行过,可以直接返回之前的结果而不重新执行整个操作。
- 缓存过期: 为了避免缓存一直占用内存,
NameNodeRetryCache中的记录会有过期时间。如果在一定时间内没有被重试,缓存中的记录会被清除。
HDFS写数据流程
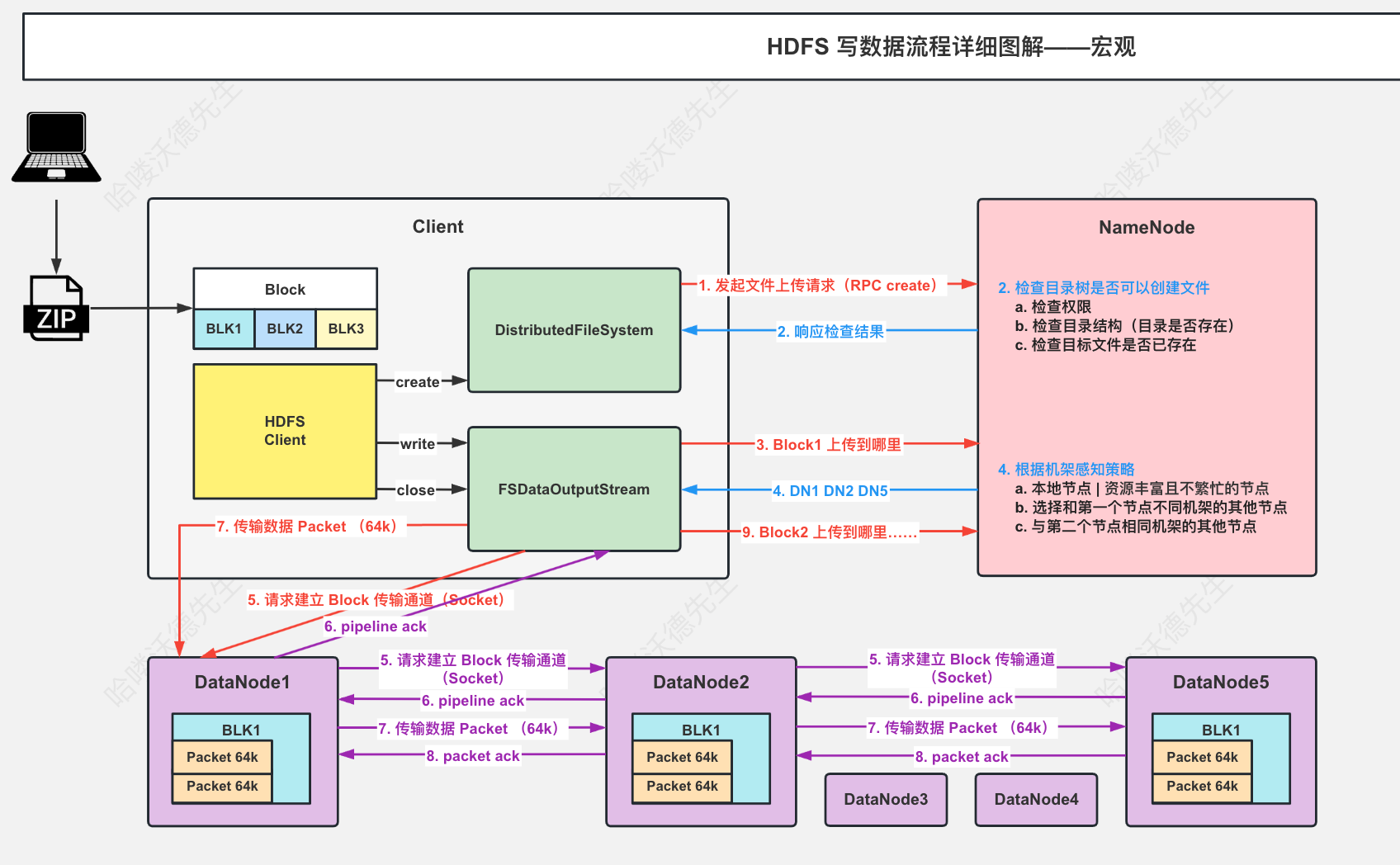
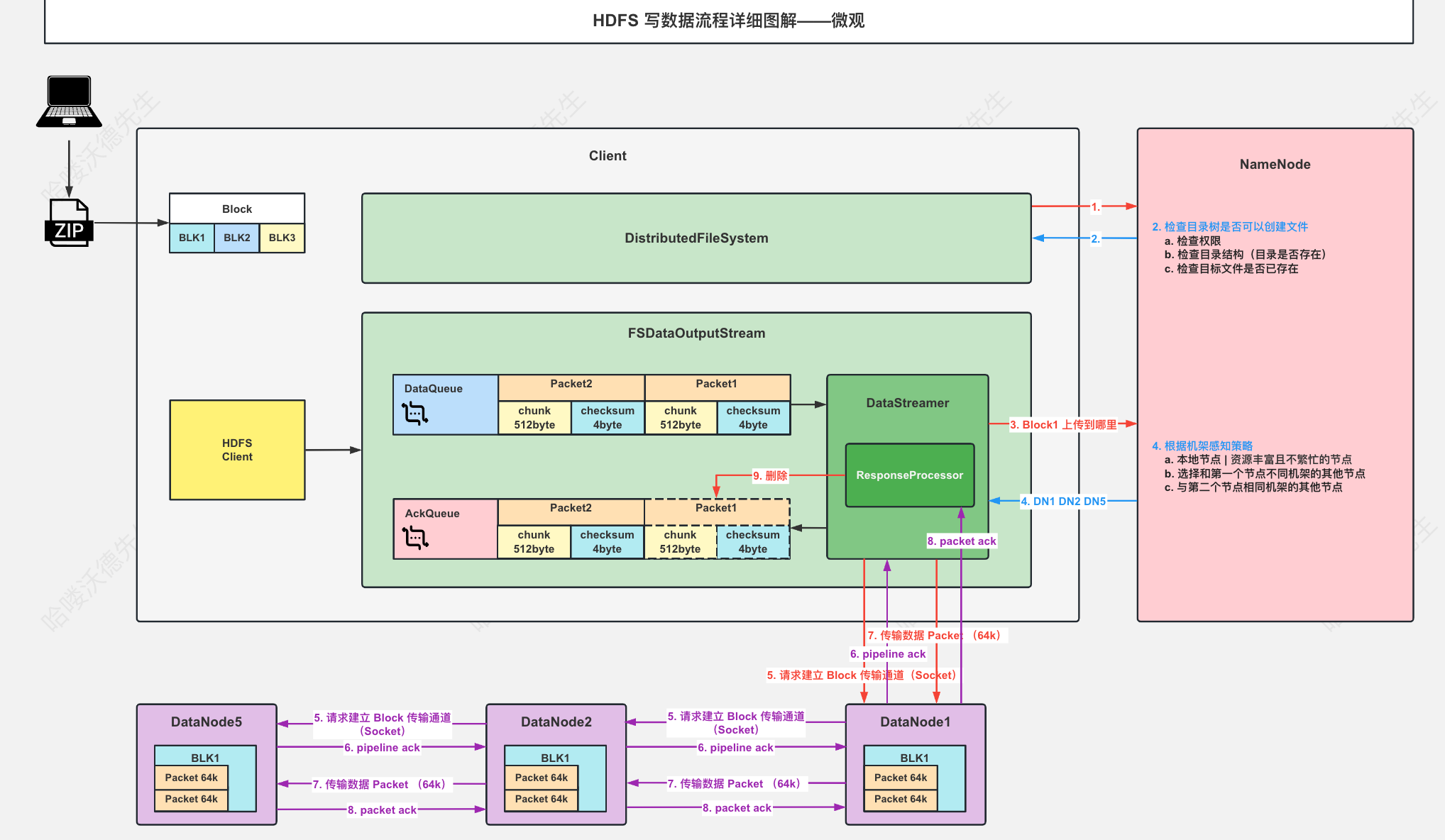
写数据流程(未考虑异常情况)
FileSystem.get
- 通过spi机制和ur类型实例化找到FileSystem实现类并返回,这里是DistributedFileSystem
fs.create
- 创建DFSOutputStream
- 携带文件路径,是否overwrite,副本数,block大小等信息 调用namenode.create 由服务端校验权限,目录结构,并返回HdfsFileStatus
- 通过status以及之前传递的参数创建DFSOutputStream ,并且在构造器实例化DataStreamer
- 调用DFSOutputStream.start() ,然后再start()方法内再调用streamer.start() ,streamer是一个Thread
- 如果是新的block(流状态为PIPELINE_SETUP_CREATE),向namenode申请addBlock,然后连接第一个datanode,初始化ResponseProcessor(Thread)用于接受ack,变更流状态为DATA_STREAMING
- ResponseProcessor 线程校验datanode返回回来的ack,将packet从ackQueue中移除,释放buffer,唤醒dataQueue
- 将dataQueue中的packet转移到ackQueue,然后发送数据到datanode
- 如果已经是最后一个packet在这个block中,阻塞(dataQueue,wait())等待所有ackQueue应答,并关闭输出流,ResponseProcessor,清空pipeline,重置流状态为PIPELINE_SETUP_CREATE
- 如果是新的block(流状态为PIPELINE_SETUP_CREATE),向namenode申请addBlock,然后连接第一个datanode,初始化ResponseProcessor(Thread)用于接受ack,变更流状态为DATA_STREAMING
- beginFileLease(),开始续签租约,默认续签间隔是softlimit/2
- 将DFSOutputStream 包装为 HdfsDataOutputStream返回
- 创建DFSOutputStream
out.write
- chunk满了计算校验和放进packet
- packet满了放进dataQueue准备发送
out.close
- flush
- 停止
DataStreamer和ResponseProcessor线程等 - 通知namenode文件已经上传完成
服务端NameNodeRpcServer.create:
- 校验path长度(8000)和深度(1000)
- 当前NameNode的状态(active、backup、standby)是否支持该操作
- 检查重试缓存RetryCache
- 开始创建文件
- 检查路径是否合法
- 确认nameNode不是在安全模式
- 权限校验
- 校验副本数,block大小合法
- 创建文件或者是删除原文件重新创建(如果是overwrite),该过程目录会上锁
- 给文件添加Lease租约
- 根据参数LAZY_PERSIST设置存储策略
- 预写日志
- 预写日志落盘
- 如果有需要删除block,删除block(添加到invalidateBlocks ,blocksMap删除对应信息)
- RetryCache 添加信息,并返回结果
服务端NameNodeRpcServer.addBlock:
下面主要描述选取datanode的过程
- 副本数超过datanode个数,副本数=datanode个数
- 第一个节点,如果上传文件的节点就是DataNode 优先选取这个,如果不是选择同一个机架的随机一个节点,还不行就集群随机选一个
- 第二个节点,优先与第一个节点不同机架的随机节点。
- 第三个节点,优先与第二个节点同机架的随机节点。
- 3个以上,随机
- 返回结果依据网络拓扑图的贪心算法排序返回,该顺序就是数据流向顺序
//副本状态
enum ReplicaState {
/** Replica is finalized. The state when replica is not modified. */
FINALIZED(0),
/** Replica is being written to. */
RBW(1),
/** Replica is waiting to be recovered. */
RWR(2),
/** Replica is under recovery. */
RUR(3),
/** Temporary replica: created for replication and relocation only. */
TEMPORARY(4);
...
}
// block状态
enum BlockUCState {
/**
* Block construction completed.<br>
* The block has at least the configured minimal replication number
* of {@link ReplicaState#FINALIZED} replica(s), and is not going to be
* modified.
* NOTE, in some special cases, a block may be forced to COMPLETE state,
* even if it doesn't have required minimal replications.
*/
COMPLETE,
/**
* The block is under construction.<br>
* It has been recently allocated for write or append.
*/
UNDER_CONSTRUCTION,
/**
* The block is under recovery.<br>
* When a file lease expires its last block may not be {@link #COMPLETE}
* and needs to go through a recovery procedure,
* which synchronizes the existing replicas contents.
*/
UNDER_RECOVERY,
/**
* The block is committed.<br>
* The client reported that all bytes are written to data-nodes
* with the given generation stamp and block length, but no
* {@link ReplicaState#FINALIZED}
* replicas has yet been reported by data-nodes themselves.
*/
COMMITTED
}DataNode接受写请求
在启动DataNode时调用 DataNode.initDataXceiver() ,会创建一个DataXceiverServer (单独线程)统一接收请求
每接受到请求调用 DataXceiver.create()创建一个DataXceiver(单独线程) 处理具体请求
在DataXceiver.run()方法里, op=readOp() 读取输入流,获取到具体执行到操作,再调用processOp(op) 处理
如果操作是WRITE_BLOCK,调用opWriteBlock()方法
- 构建 BlockReceiver处理具体的block数据
- 如果有下游 ,构建自己的第一个下游输入输出流,然后调用 new Sender(mirrorOut).writeBlock()
- 将ack逐级返回至cli
- blockReceiver.receiveBlock() 处理具体的block
- 创建PacketResponder(单独线程)处理ack信息
- 循环调用receivePacket()
- 会判断当前节点是否是数据流管道中的最后一个节点, 或者是输入流启动了sync标识(syncBlock) 要求Datanode立即将数据包同步到磁盘。 在这两种情况下, Datanode会先将数据写入磁盘, 然后再通知PacketResponder处理确认(ACK) 消息; 否则, receivePacket()方法接收完数据包后会立即通知PacketResponder处理确认消息。
- 将数据发送给下游
- 校验checksum
- 数据落盘
- 更新block的时间戳,长度等信息
- 通知nameNode接收到了新的数据块
- 关闭流
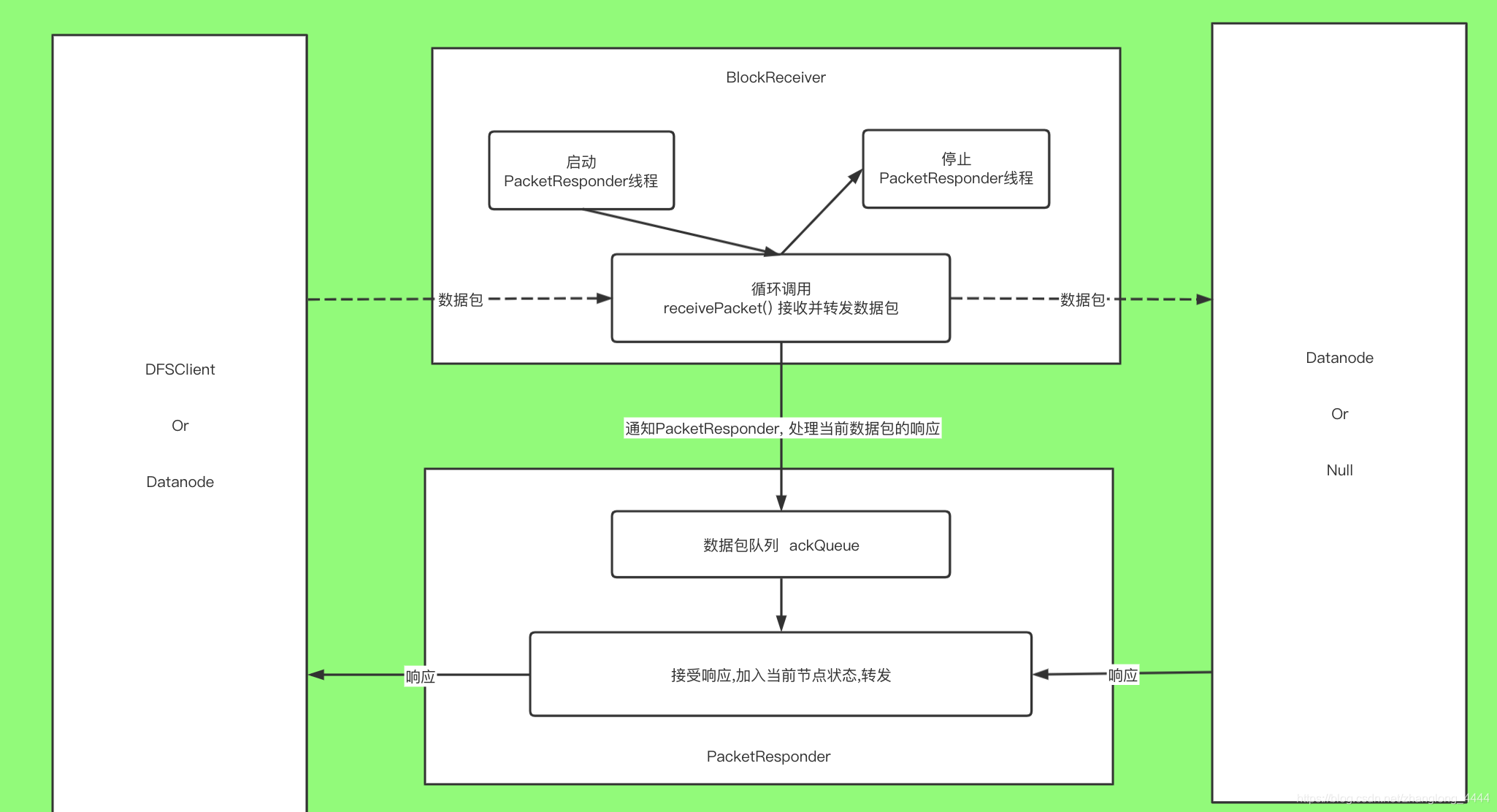
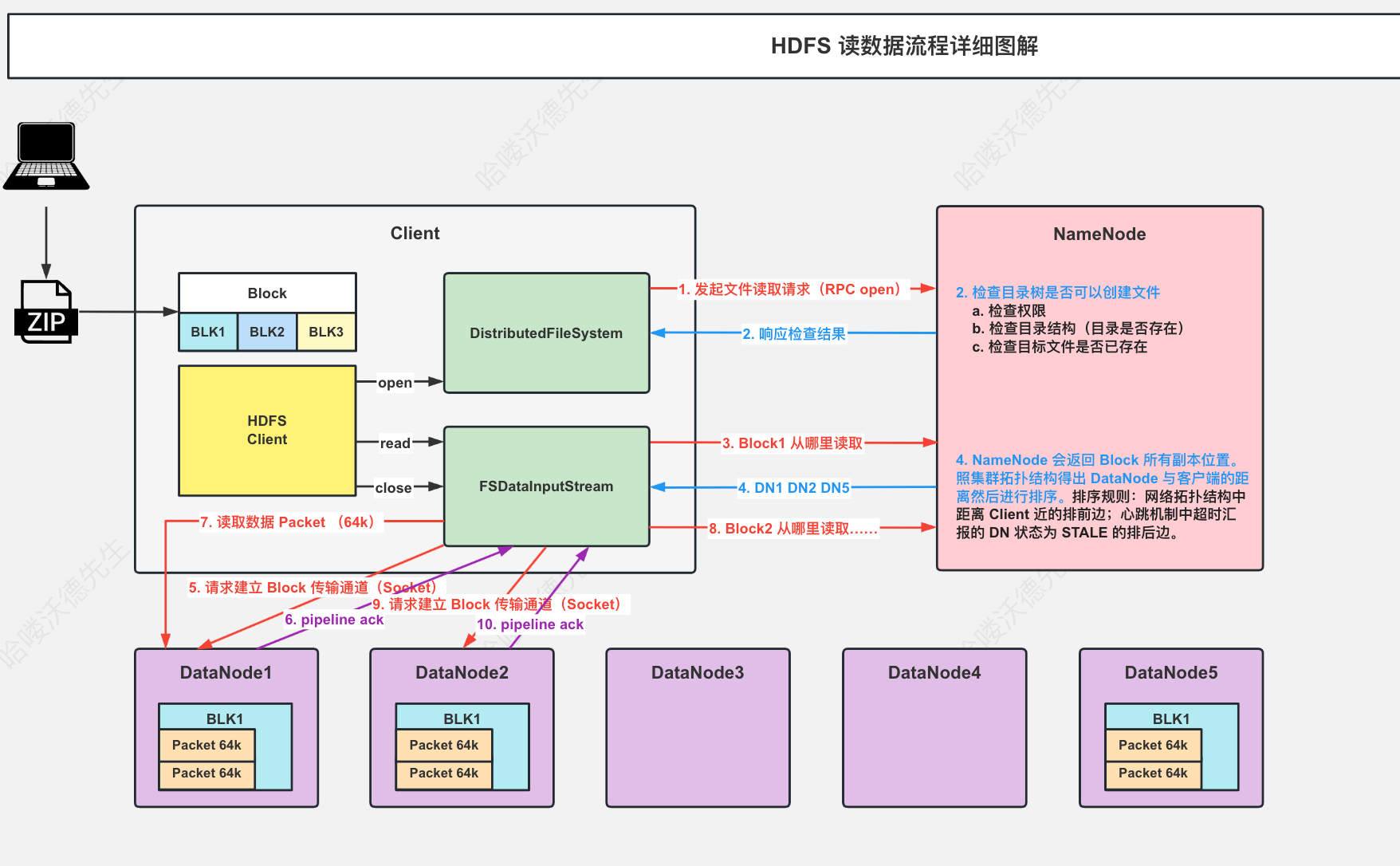
HDFS读数据
FSEditLog & FSImage
在Namenode中, 命名空间( namespace, 指文件系统中的目录树、 文件元数据等信息) 是被全部缓存在内存中的, 一旦Namenode重启或者宕机, 内存中的所有数据将会全部丢失, 所以必须要有一种机制能够将整个命名空间持久化保存, 并且能在Namenode重启时重建命名空间
Namenode的实现是将命名空间信息记录在fsimage( 命名空间镜像) 的二进制文件中
editlog是一个日志文件,HDFS客户端执行的所有写操作首先会被记录到editlog文件中。 HDFS会定期地将editlog文件与fsimage文件进行合并, 以保持fsimage跟Namenode内存中记录的命名空间完全同步
transactionId
每次namespace修改,editlog中发起一个新的transaction用于记录这次操作, 每个transaction会用一个唯一的transactionId标识
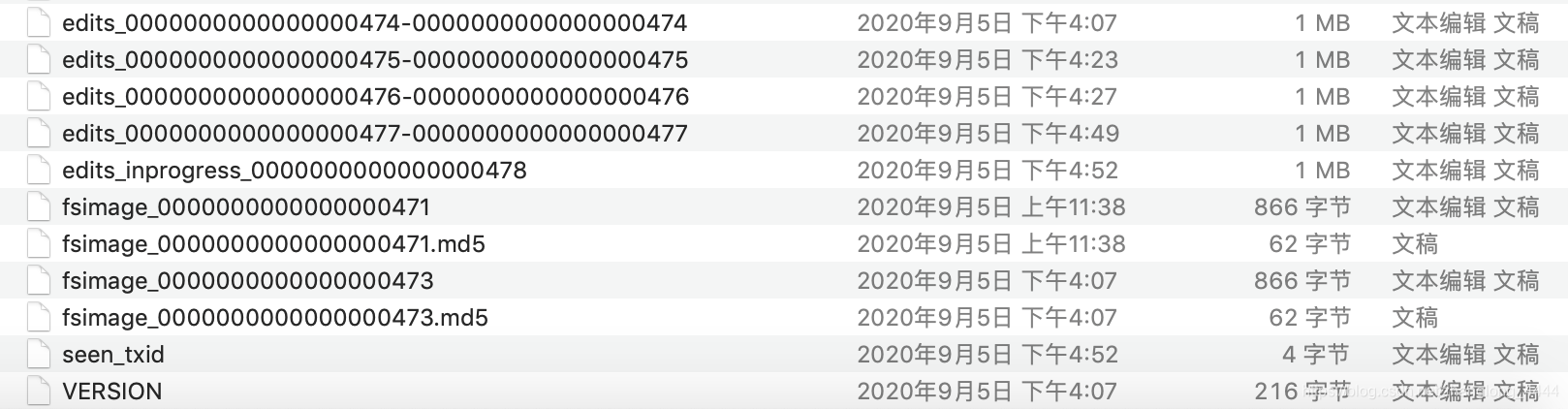
- edits_start-end: edits文件,保存start-end的所有事务操作
- fsimage_end:保存end之前的所有元数据镜像,每个fsimage文件还有一个对应的md5文件, 用来确保fsimage文件的正确性
- edits_inprogress_start:从start开始的所有事务,重置操作会将该文件关闭,重命名为edits文件,并新开一个inprogress文件
- seen_txid: the largest Tx ID that has been safely written to its edit log files. 用于启动时确认事务没有丢失
FSEditLog 5个状态
- UNINITIALIZED: editlog的初始状态。
- BETWEEN_LOG_SEGMENTS: editlog的前一个segment已经关闭, 新的还没开始。
- IN_SEGMENT: editlog处于可写状态。
- OPEN_FOR_READING: editlog处于可读状态。
- CLOSED: editlog处于关闭状态。
对于非HA机制的情况:
FSEditLog应该开始于UNINITIALIZED或者CLOSED状态(因为在构造FSEditLog对象时,FSEditLog的成员变量state默认为State.UNINITIALIZED) ,
FSEditLog初始化完成之后进入BETWEEN_LOG_SEGMENTS 状态
BETWEEN_LOG_SEGMENTS表示前一个segment已经关闭,新的还没开始,日志已经做好准备了。
IN_SEGMENT状态,表示可以写editlog文件了。
对于HA机制的情况:
FSEditLog同样应该开始于UNINITIALIZED或者CLOSED状 态,但是在完成初始化后FSEditLog并不进入BETWEEN_LOG_SEGMENTS状态,而是进入OPEN_FOR_READING状态(因为目前Namenode启动时都是以Standby模式启动的,然后通过DFSHAAdmin发送命令把其中一个Standby NameNode转换成Active Namenode)。
JournalSet
存放所有的JournalManager(根据URI实例化成对应的对象),JournalManager具体实现日志写到哪里
FileJournalManager:本地文件
QuorumJournalManager:多个JournalNode节点组成集群来管理和共享EditLog,Paxos协议类似,当NameNode向JournalNode请求读写时,要求至少大多数成功返回才认为本次请求成功
或者自定义插件写到NFS等
可以同时写到多个地方
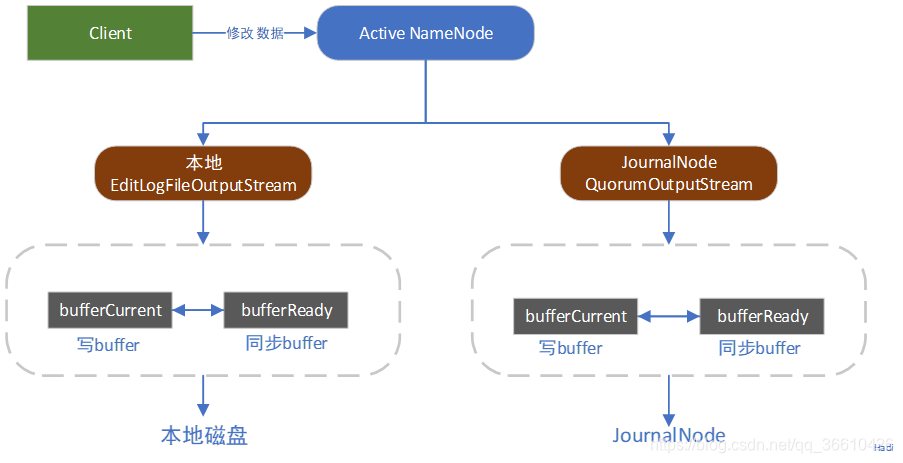
记录日志&日志落盘
FSEditLog 中重点关注的几个变量
// a monotonically increasing counter that represents transactionIds.
// All of the threads which update/increment txid are synchronized,
// so make txid volatile instead of AtomicLong.
// 当前最新的事务ID,volatile修饰保证线程可见性并且在涉及到修改事务ID的地方都加了syncronize 关键字
// 从而确定了该id的唯一性和递增特性
private volatile long txid = 0;
// stores the last synced transactionId.
// 上次落盘的最新事务id
private long synctxid = 0;
// is a sync currently running?
// 标识是否正在同步
private volatile boolean isSyncRunning;
private static class TransactionId {
public long txid;
TransactionId(long value) {
this.txid = value;
}
}
// stores the most current transactionId of this thread.
// 使用ThreadLoad来保存当前操作的事务id
private static final ThreadLocal<TransactionId> myTransactionId = new ThreadLocal<TransactionId>() {
@Override
protected synchronized TransactionId initialValue() {
return new TransactionId(Long.MAX_VALUE);
}
};记录日志(大致,细节未描述):
- 例如 logOpenFile ,构建FSEditLogOp.AddOp
- 申请新的事务id
- 写入bufferCurrent
落盘:
- 如果自己当前事务id大于上次落盘的最新事务id ,并且isSyncRunning,循环等待
- 再次判断当前事务id是否上次落盘的最新事务id,有可能刚才的同步已经把自己的事务id已经同步了(一次同步操作是同步上次落盘的最新事务id到当前事务id区间的事务)
- 交换bufferCurrent和bufferReady, bufferCurrent用于其他线程保存事务不阻塞,
- bufferReady里面的事务flush到磁盘
- 更新synctxid
StandbyNameNode
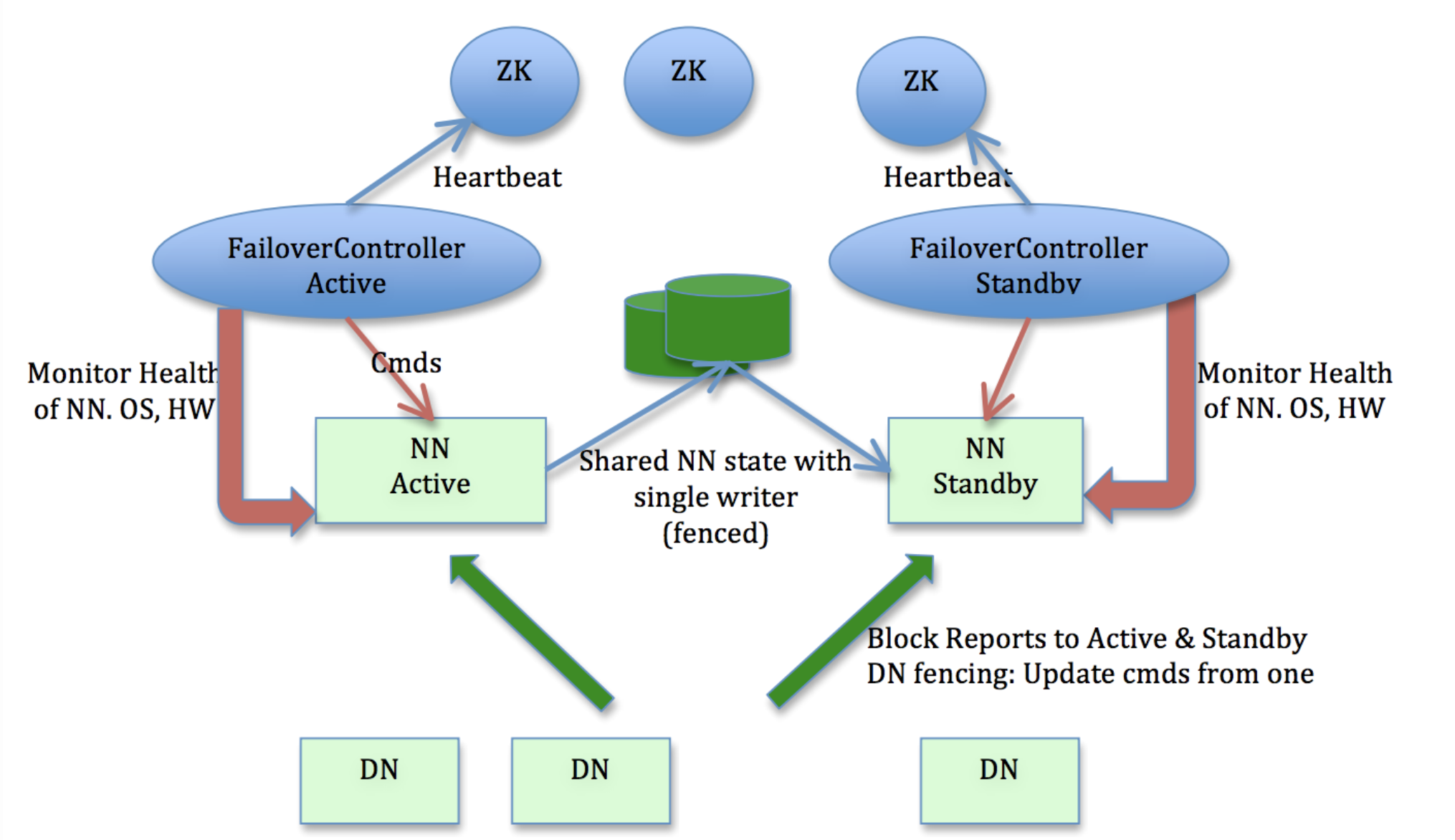
在同一个HA HDFS集群中, 将会同时运行两个Namenode实例, 其中一个为Active Namenode,用于实时处理所有客户端请求; 另一个为Standby Namenode, StandbyNamenode的命名空间与ActiveNamenode是完全保持一致的。 所以当ActiveNamenode出现故障时, Standby Namenode可以立即切换成Active状态。
当Active Namenode执行任何修改命名空间的操作时, 它至少需要将产生的editlog文件持久化到N-(N-1)/2个JournalNode节点上才能保证命名空间修改的安全性
NameNode.startStandbyServices()
线程1:EditLogTailer.EditLogTailerThread
- 如果超过默认时间2min,ANN(ActiveNameNode)没有Logroll,发请求到ANN,主动触发Logroll
- 从JN(JournalNode) 拉取edits,并合并至内存
- 默认60s循环
线程2:StandbyCheckpointer.CheckpointerThread
checkpoint操作不会给整个名称空间上锁,因为SBN(StandbyNameNode) 只有日志重放会修改树结构
- 超过1h或者没有checkpoint的事务数超过100w,执行checkpoint操作
- 将当前的名称空间写到镜像文件fsimage.ckpt_xxxx
- 将fsimage.ckpt_txid 从命名为 fsimage_xxxx
- 将fsImage通过Http发送给ANN
SecondaryNameNode
在非HA部署环境下, 合并FSImage操作是由Secondary Namenode来执行的
SNN启动两种模式
- run a command (i.e. checkpoint or geteditsize) then terminate
- run as a daemon when {@link #parseArgs} yields no commands (作为一个守护进程)
SecondaryNameNode.main()
- startInfoServer
- startCheckpointThread
- 通过rpc获取最新的事务id ,综合判断事务差和时间差(与上面类似),决定是不是要checkpoint
- 通知nameNode rollEditLog
- rpc调用getEditLogManifest(sinceTxId) ,获取sinceTxId 后可以下载的所有edit日志信息
- 下载镜像(如果检查点不一致)和edit日志
- 合并镜像
- 上传镜像至nameNode
HDFS Federation
Hadoop 1.0 HDFS 架构只允许整个集群中存在一个 namespace,而该 namespace 被仅有的一个 namenode 管理。
HDFS 的底层存储,即 Datanode 节点是可以水平扩展的,但 namespace 不可以。当前的 namespace 只能存放在单个namenode 上,而 namenode 在内存中存储了整个分布式文件系统中的元数据信息,这限制了集群中数据块,文件和目录的数目
文件操作的性能制约于单个 namenode 的吞吐量,单个 namenode 当前仅支持约 60,000 个并发 task
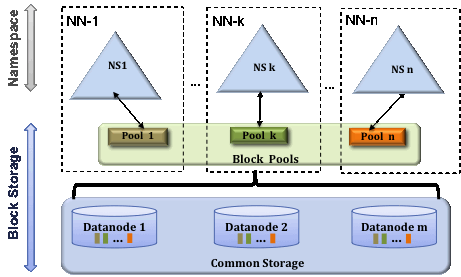
为了水平扩展 namenode,federation 使用了多个独立的 namenode / namespace。这些 namenode 之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的 datanode 被用作通用的数据块存储存储设备。每个 datanode 要向集群中所有的 namenode 注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode 的命令。
每个 block pool 内部自治,也就是说各自管理各自的 block,不会与其他 block pool 交互。一个 namenode 挂掉了,不会影响其他 namenode。
某个 namenode 上的 namespace 和它对应的 block pool 一起被称为 namespace volume(命名空间卷)。它是管理的基本单位。当一个 namenode / nodespace 被删除后,其所有 datanode 上对应的 block pool 也会被删除
Federation局限性
- 为了确定数据在哪个nameSpace上,引入了ViewFs(相当于客户端的路由)
- 可能会对历史任务(历史任务为原来的hdfs schema)有影响
- 如果要对不同namespace下的数据进行转移,需要使用distcp,拷贝效率低,对网络,存储有影响
- 重度依赖客户端
- Hive、Spark等上层应用对Federation的支持仍然存在问题
HDFS Router-based Federation
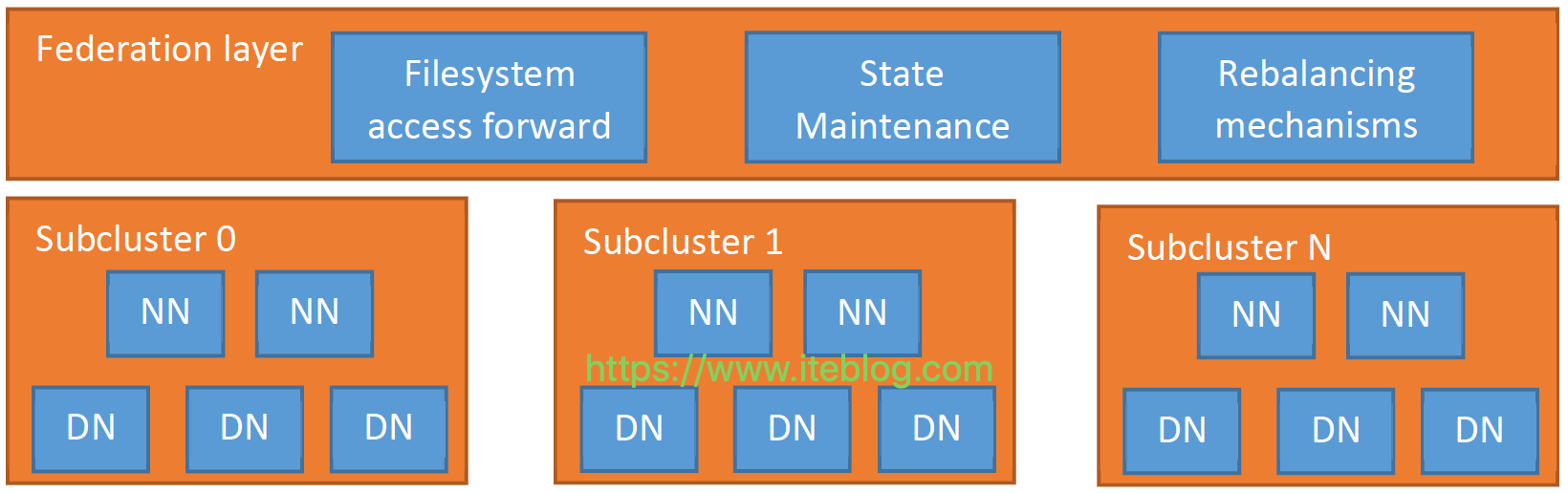
从Hadoop 2.9.0和Hadoop 3.0.0版本开始引入了一种基于路由的Federation方案
基于路由的Federation方案是在服务端添加了一个Federation layer,这个额外的层允许客户端透明地访问任何子集群,让子集群独立地管理他们自己的block pools,并支持跨子集群的数据平衡。
Federation layer包含了多个组件:Router、State Store 以及 Rebalancing mechanisms。Router组件和Namenode具有相同的接口,并根据State Store里面的信息将客户端请求转发到正确的子集群。
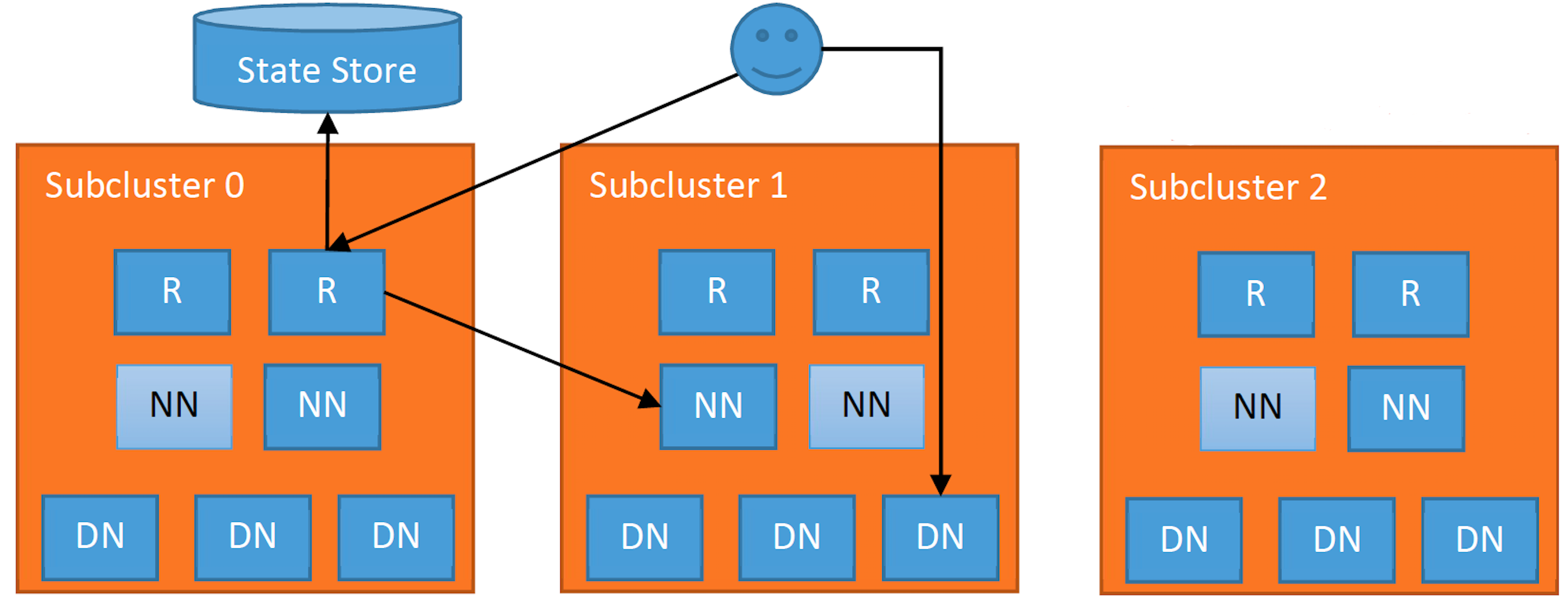
- 客户端向集群中任意一个Router发出某个文件的读写请求操作;
- Router从 State Store里面的Mount Table查询哪个子集群包含这个文件,并从State Store里面的Membership table里面获取正确的NN;
- Router获取到正确的NN后,会将客户端的请求转发到NN上,然后也会给客户端一个请求告诉它需要请求哪个子集群;
- 此后,客户端就可以直接访问对应子集群的DN,并进行读写相关的操作。
Balancer
hdfs balancer
Balancer负责整个集群的数据平衡
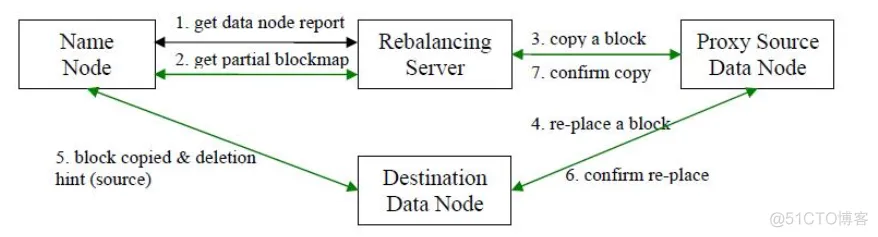
- 数据均衡服务(Rebalancing Server)首先要求 NameNode 生成 DataNode 数据分布分析报告,获取每个DataNode磁盘使用情况
- Rebalancing Server汇总需要移动的数据分布情况,计算具体数据块迁移路线图。数据块迁移路线图,确保网络内最短路径
- 开始数据块迁移任务,Proxy Source Data Node复制一块需要移动数据块
- 将复制的数据块复制到目标DataNode上
- 删除原始数据块
- 目标DataNode向Proxy Source Data Node确认该数据块迁移完成
diskbalancer
因大量的写入和删除,或者由于磁盘更换和扩容等操作,导致数据在节点上的磁盘之间分布不均匀,引起HDFS并发读写性能的下降等问题时,可通过HDFS Diskbalancer将数据均匀地分布在DataNode的所有磁盘上
plan: 生成执行计划
hdfs diskbalancer -plan <hostname> [options]execute:执行计划
hdfs diskbalancer -execute <planfile>query:查询执行计划
hdfs diskbalancer -query <hostname> [options]cancel: 取消执行计划
hdfs diskbalancer -cancel <planFile> | -cancel <planID> -node <hostname>report: 查看报告
hdfs diskbalancer -fs http://namenode.uri -report -node <file://> | [<DataNodeID|IP|Hostname>,...]BlockScanner
每个Datanode都会初始化一个数据块扫描器周期性地验证Datanode上存储的所有数据块的正确性, 并把发现的损坏数据块报告给Namenode。 BlockScanner类就是Datanode上数据块扫描器的实现。BlockScanner里面有多个VolumeScanner, 每个BlockScanner对应一个volume , 每个BlockScanner都是单独的线程负责扫描block任务…
如何确保HDFS不丢数据
- 创建文件时,nameNode会保存editlog以及定期checkpoint生成fsimage保证元数据完整
- 上传文件时,pipeline中最后一个dataNode会对数据进行checkSum,确保每个chunk数据完整,读取数据时也会checkSum
- DataNode会定期扫描block,并把发现的损坏数据块报告给NameNode
- 一般保存数据 会有冗余副本
- 提供快照机制
- 提供回收站机制
列式存储和行式存储
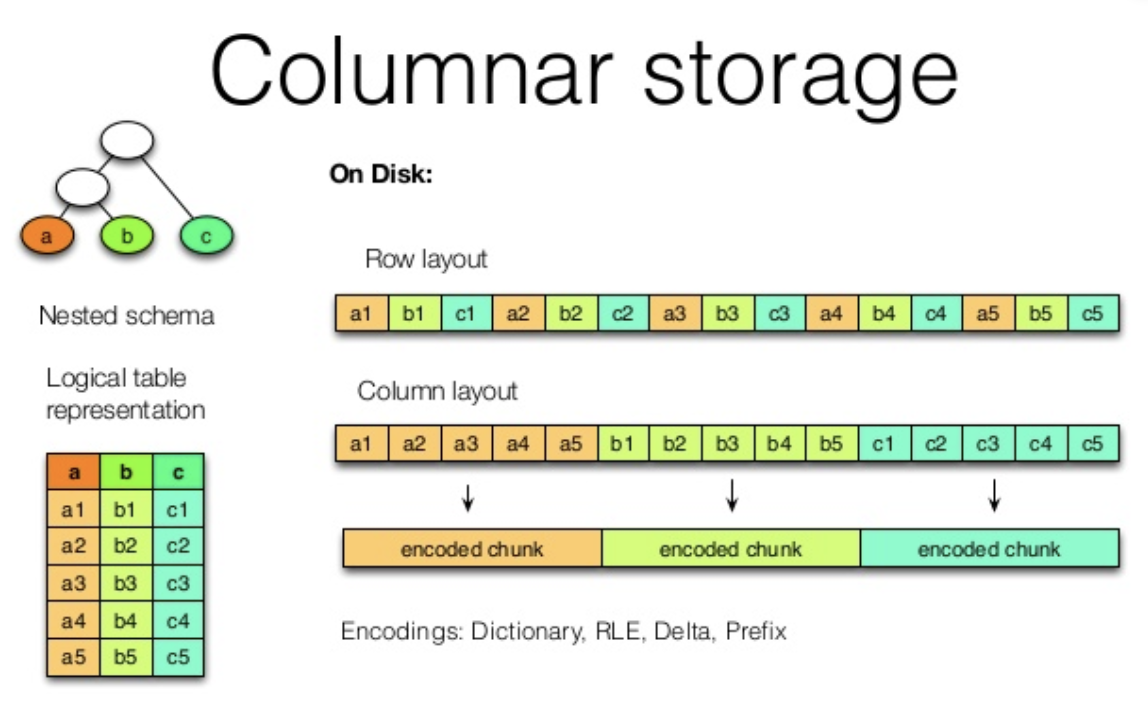
列式存储是指一列中的数据在存储介质中是连续存储的;
行式存储是指一行中的数据在存储介质中是连续存储的。
行式存储优势
适合随机增删改操作
需要经常读取整行数据
聚集运算少
列式存储的优势
- 自动索引,因为基于列存储,所以每一列本身就相当于索引。
- 利于压缩,将相似度很高、信息熵很低的数据放在一起,用更小的空间表达相同的信息量
- 延时物化,把物化的时机尽量地拖延到整个查询声明的后期。延迟物化意味着在查询执行的前一段时间内,查询执行的模型不是关系代数,而是基于 Column 的
SELECT name FROM person WHERE id > 10 and age > 20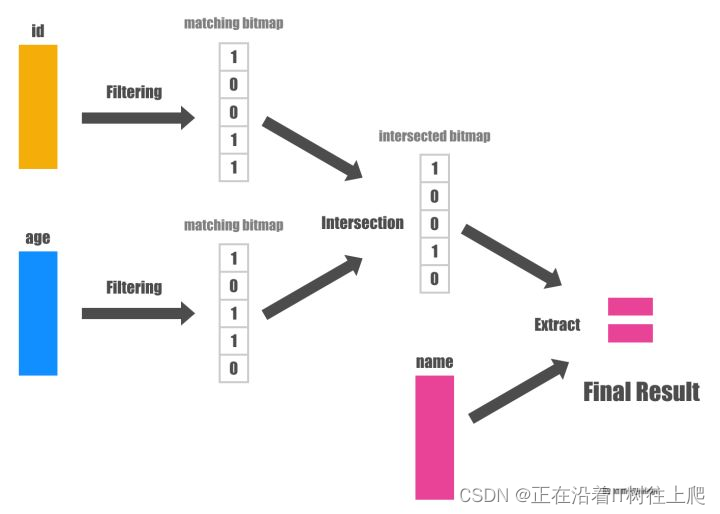
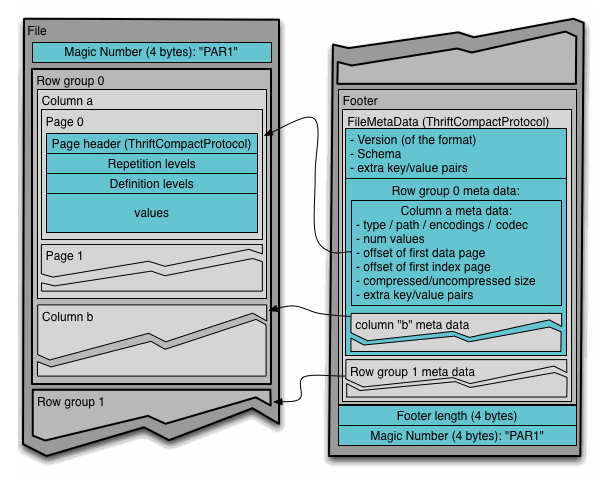
Parquet 文件格式
- 行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的,例如记录占用空间比较小的Schema可以在每一个行组中存储更多的行。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
- 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
YARN
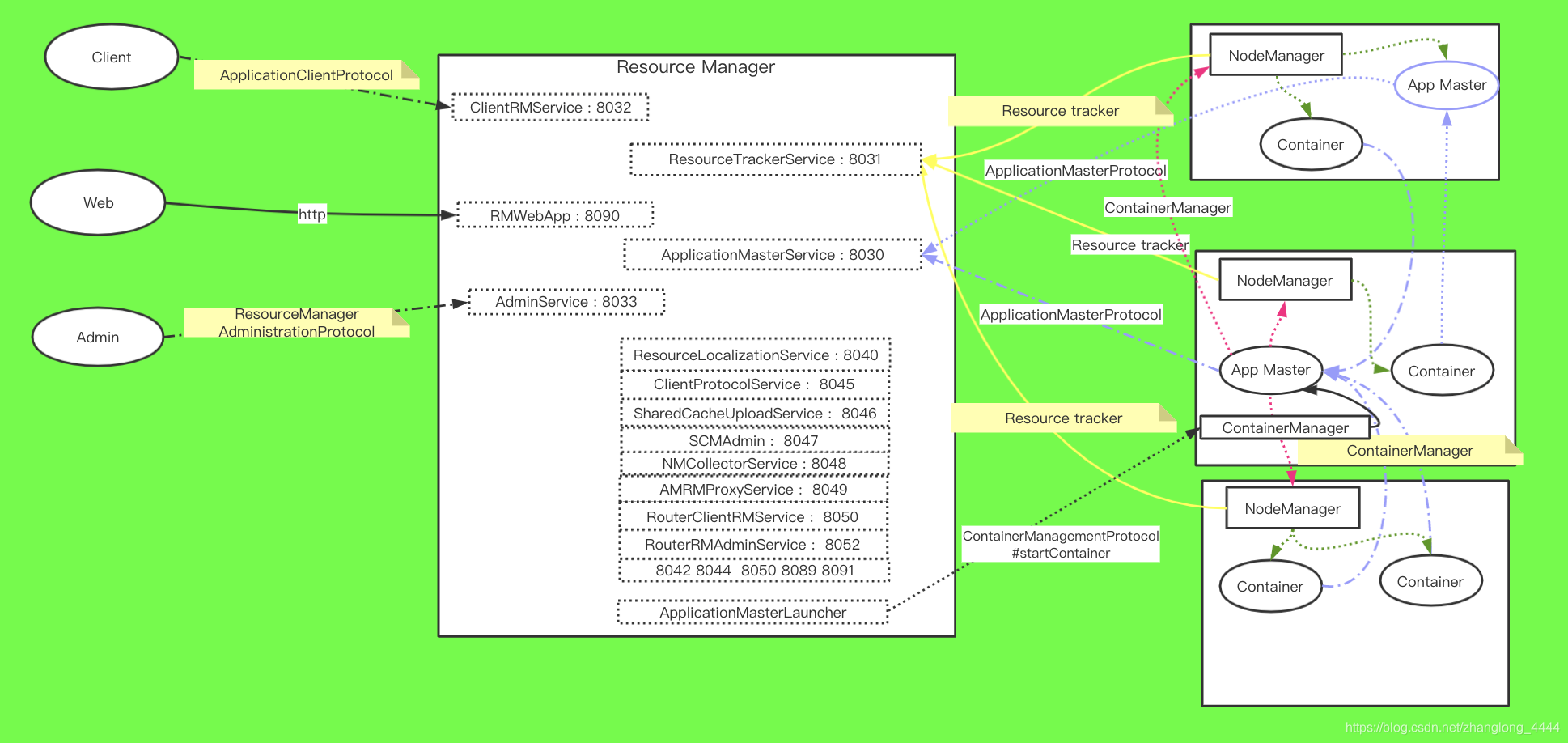
协议类型:
ApplicationClientProtocol:clients与RM之间的协议, JobClient通过该RPC协议提交应用程序、 查询应用程序状态、kill等
ResourceManagerAdministrationProtocol:Admin与RM之间的通信协议, Admin通过该RPC协议更新系统配置文件, 例如节点黑白名单等
ApplicationMasterProtocol:AM与RM之间的协议, AM通过该RPC协议向RM注册和撤销自己, 并为各个任务申请资源。
ContainerManagementProtocol:AM与NM之间的协议, AM通过该RPC要求NM启动或者停止Container, 获取各个Container的使用状态等信息
ResourceTracker:NM与RM之间的协议, NM通过该RPC协议向RM注册, 并定时发送心跳信息汇报当前节点的资源使用情况和Container运行情况
ResourceManager高可用
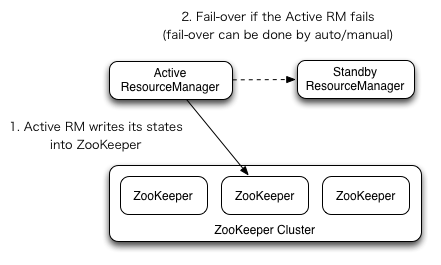
ResourceManager HA通过一个主从架构实现——在任意时刻,总有一个RM是active的,而一个或更多的RM处于standby状态等待随时成为active。触发active的转换的条件是通过admin命令行或者在automatic-failover启用的情况下通过集成的failover-controller触发。
手动转换和failover
当自动failover没有启用时,管理员需要手动切换众多RM中的一个成为active。为了从一个RM到其他RM进行failover,做法通常是先将现在的Active的RM切为Standby,然后再选择一个Standby切为Active。所有这些都可以通过”yarn rmadmin”的命令行完成。
自动failover
RM有一个选项可以嵌入使用Zookeeper的ActiveStandbyElector来决定哪个RM成为Active。当Active挂掉或者不响应时,另一个RM会自动被选举为Active然后接管集群。注意,并不需要像HDFS一样运行一个隔离的ZKFC守护进程,因为对于嵌入到RM中的ActiveStandbyElector表现出来就是在做failure检查和leader选举,不用单独的ZKFC。
在RM failover时的Client, ApplicationMaster和 NodeManager
当有多个RM时,被client和node使用的配置文件yarn-site.xml需要列出所有的RM。Clients, ApplicationMasters (AMs) 和 NodeManagers (NMs) 会以一种round-robin轮询的方式来不断尝试连接RM直到其命中一个active的RM。如果当前Active挂掉了,他们会恢复round-robin来继续寻找新的Active。
从之前的主RM状态恢复
伴随ResourceManager的重启机制开启,升级为主的RM会加载RM内部状态并且恢复原来RM留下的状态,而这依赖于RM的重启特性。而之前提交到RM的作业会发起一个新的尝试请求。应用作业会周期性的checkpoint来避免任务丢失。状态存储对于所有的RM都必须可见。当前,有两种RMStateStore实现来支持持久化—— FileSystemRMStateStore 和 ZKRMStateStore。
ResourceManager主要组件
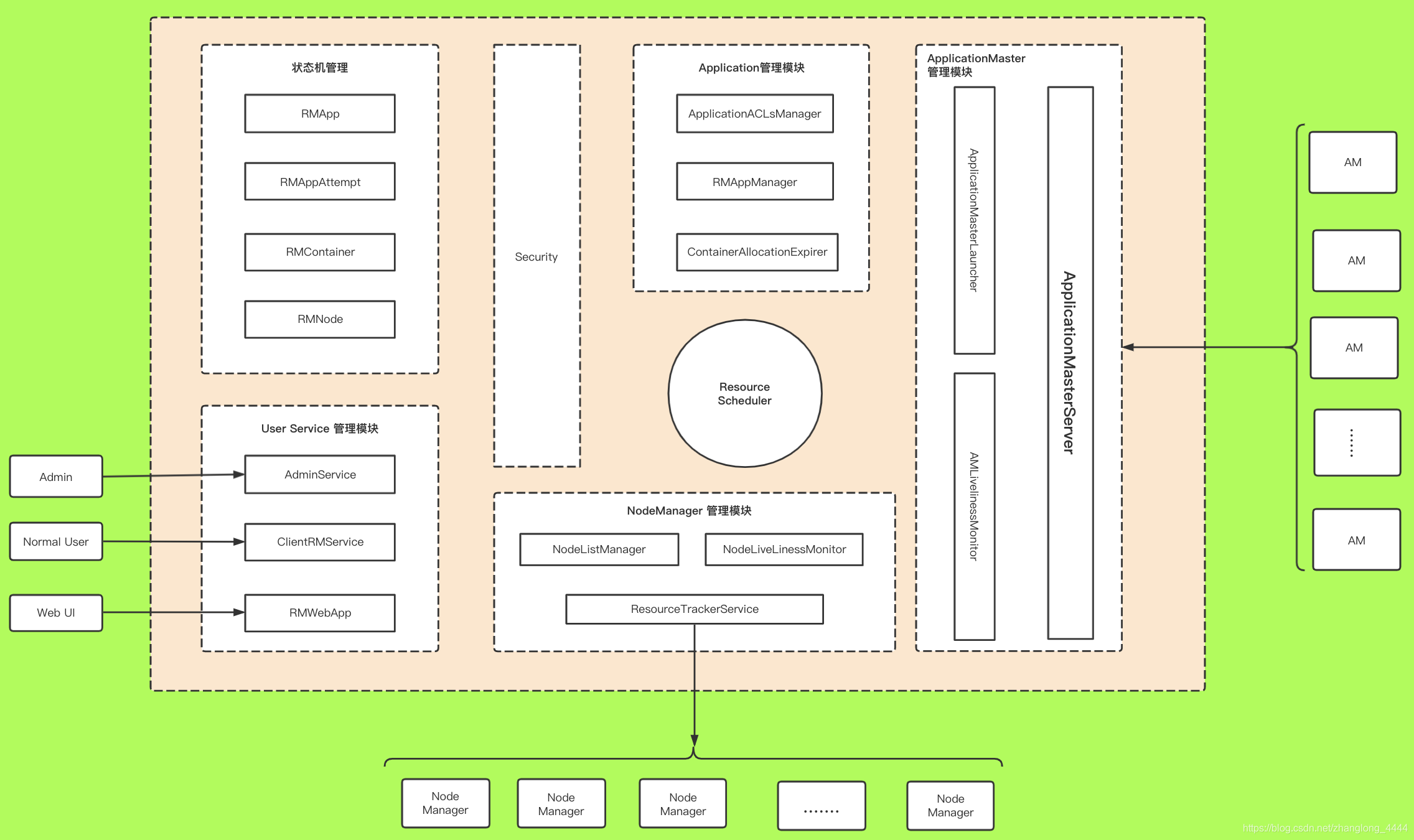
ResourceManager#管理NodeManager
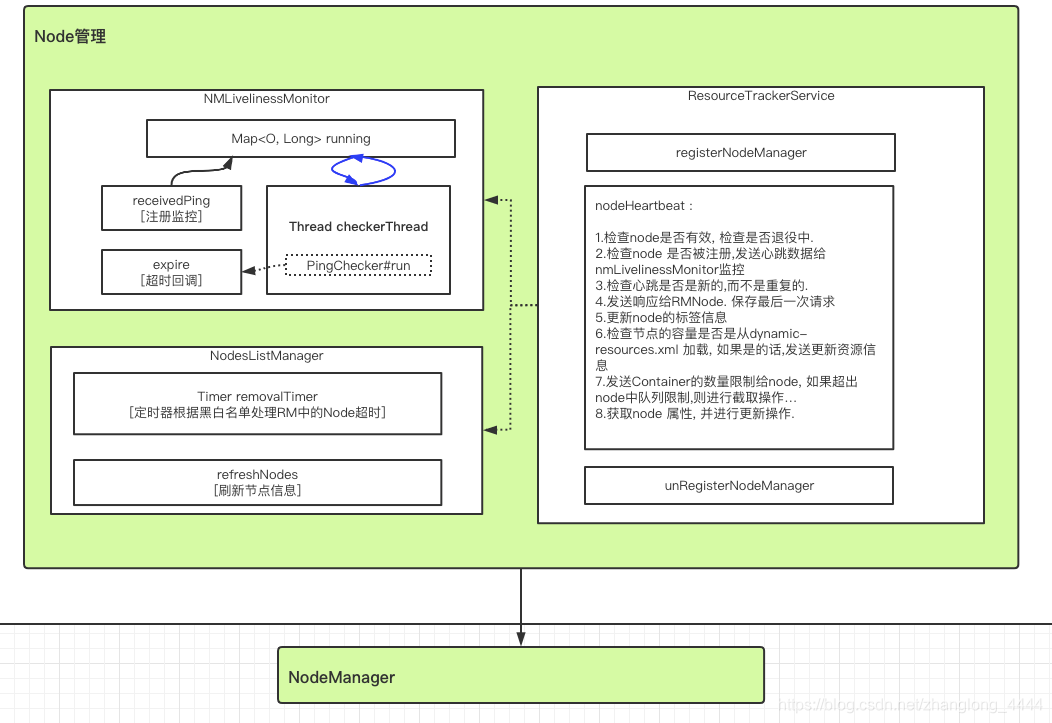
NMLivelinessMonitor
期性遍历集群中所有NodeManager, 如果一个NodeManager在一定时间(可通过参数yarn.nm.liveness-monitor.expiry-interval-ms配置, 默认为10min) 内未汇报心跳信息, 则认为它死掉了, 它上面所有正在运行的Container将被置为运行失败。 需要注意的
是, RM不会重新执行这些Container, 它只会通过心跳机制告诉对应的AM, 由AM决定是否重新执行。 如果需要, 则AM重新向RM申请资源, 然后由AM与对应的NodeManager通信以重新运行失败的Container .
单独启动一个线程 PingChecker ,每10min/3 检查一次是否超时,如果超时 触发new RMNodeEvent(id, RMNodeEventType.EXPIRE)
NodesListManager
NodesListManager管理exlude(类似于黑名单) 和inlude(类似于白名单) 节点列表,这两个列表所在的文件分别可通过yarn.resourcemanager.nodes.include-path和yarn.resourcemanager.nodes.exclude-path配置
默认情况下, 这两个列表均为空,表示任何节点均被允许接入RM。
管理员可通过命令”bin/yarn rmadmin -refreshNodes”动态加载这两个文件。
ResourceTrackerService
ResourceTrackerService实现了RPC协议ResourceTracker, 负责处理来自各个NodeManager的请求, 请求主要包括注册和心跳两种,
注册是NodeManager启动时发生的行为, 请求包中包含节点ID, 可用的资源上限等信息;
心跳是周期性行为, 包含各个Container运行状态, 运行的Application列表、 节点健康状况 ,
而ResourceTrackerService则为NM返回待释放的Container列表、Application列表等
使用 DecommissioningNodesWatcher 来跟踪 DECOMMISSIONING 节点,以决定在节点上所有正在运行的容器完成后何时转换为 DECOMMISSIONED 状态(NodeManager 将被告知关闭)。 无论容器或应用程序是否运行,DECOMMISSIONING 节点都将在不晚于 DECOMMISSIONING_TIMEOUT 的情况下被 DECOMMISSIONED。
ResourceManager#管理Application
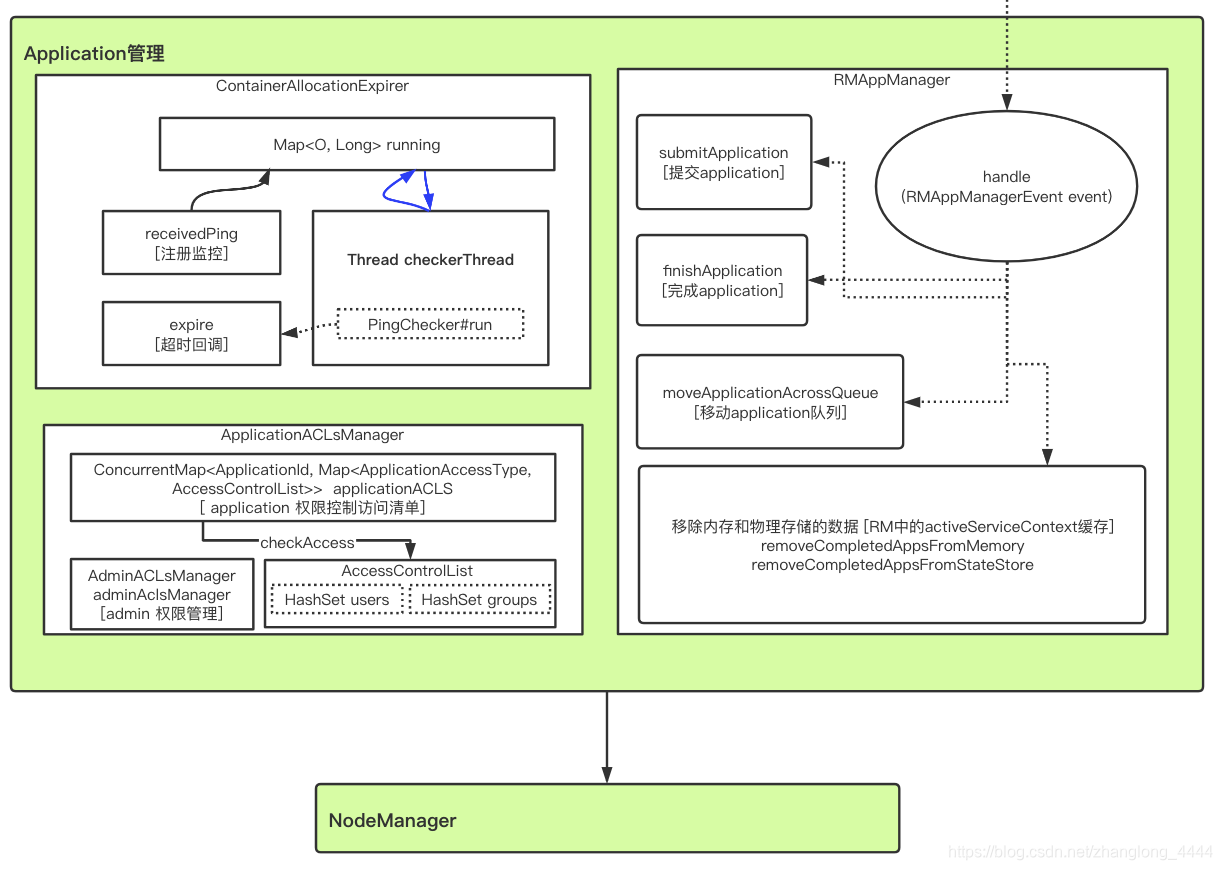
ApplicationACLsManager
负责管理应用程序的访问权限, 包含两部分权限: 查看权限和修改权限。
**查看权限主要用于查看应用程序基本信息, 比如运行时间、 优先级等信息; **
修改权限则主要用于修改应用程序优先级、 杀死应用程序等。 默认情况下, 任意一个普通用户可以查看所有其他用户的应用程序。
RMAppManager
RMAppManager负责应用程序的启动和关闭。
ClientRMService收到来自客户端的提交应用程序请求后, 将调用函数RMAppManager#submitApplication创建一个RMAppImpl对象,触发RMAppEventType.START
当RMApp运行结束后, 将向RMAppManager发送一个RMAppManagerEventType.APP_COMPLETED事件, 它收到该事件后将调用RMAppManager#finishApplication进行收尾工作。①将该应用程序放入已完成应用程序列表中, 以便用户查询历史应用程序运行信息 ②将应用程序从RMStateStore中移除。 RMStateStore记录了运行中的应用程序的运行日志, 当集群故障重启后, ResourceManager可通过这些日志恢复应用程序运行状态, 从而避免全部重新运行, 一旦应用程序运行结束后, 这些日志便失去了意义, 故可以对其进行删除
ContainerAllocationExpirer
当一个AM获得一个Container后, YARN不允许AM长时间不对其使用, 因为这会降低整个集群的利用率。 当AM收到RM新分配的一个Container后, 必须在一定的时间(默认为10min, 管理员可通过参数yarn.resourcemanager.rm.container-allocation.expiry-interval-ms修改) 内在对应的NM上启动该Container, 否则RM将强制回收该Container。
ResourceManager#管理ApplicationMaster
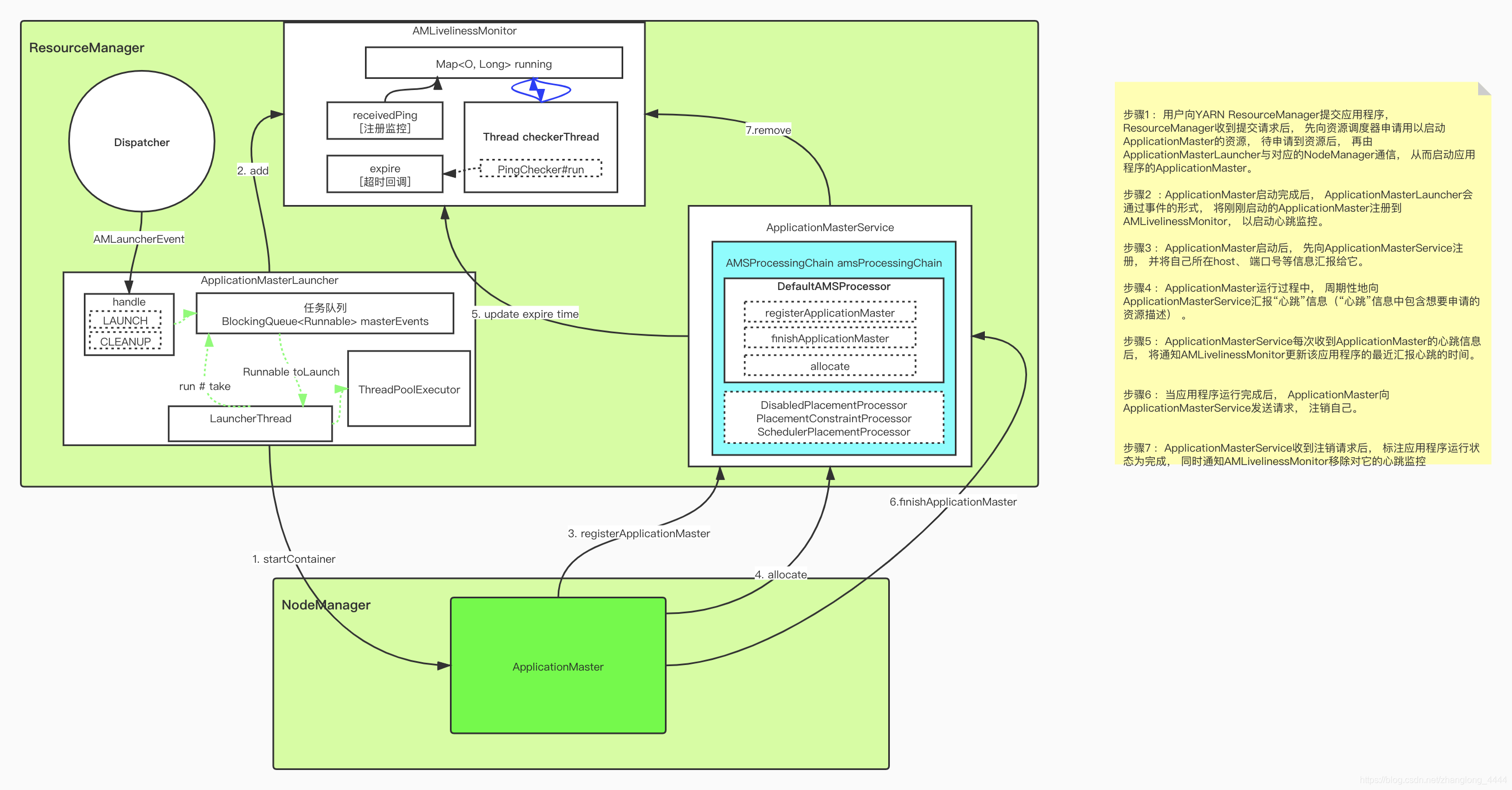
ApplicationMasterLauncher
ApplicationMasterLauncher既是一个服务, 也是一个事件处理器, 它处理AMLauncherEvent类型的事件, 该类型事件有两种, 分别是请求启动一个ApplicationMaster的”LAUNCH”事件和请求清理一个ApplicationMaster的”CLEANUP”事件。 ApplicationMasterLauncher维护了一个线程池, 从而能够尽快地处理这两种事件。
如果ApplicationMasterLauncher收到了”LAUNCH”类型的事件, 它会与对应的NodeManager通信, 要求它启动ApplicationMaster。 整个过程比较简单, 首先创建一个ContainerManagementProtocol协议的客户端, 然后向对应的NodeManager发起连接请求,接着将启动AM所需的各种信息, 包括启动命令、 JAR包、 环境变量等信息, 封装成一个StartContainerRequest对象, 然后通过RPC函数ContainerManagementProtocol#startContainer发送给对应的NM。
AMLivelinessMonitor
该服务周期性遍历所有应用程序的ApplicationMaster, 如果一个ApplicationMaster在一定时间(可通过参数yarn.am.liveness-monitor.expiry-interval-ms配置, 默认为10min) 内未汇报心跳信息, 则认为它死掉了, 它上面所有正在运行的Container将被置为运行失败(RM不会重新执行这些Container, 它只会通过心跳机制告诉对应的AM, 由AM决定是否重新执行。 如果需要, 则AM重新向RM申请资源) ; 如果AM运行失败, 则由RM重新为它申请资源, 以便能够重新分配到另外一个节点上(用户可在提交应用程序时通过函数ApplicationSubmissionContext#setMaxAppAttempts设置ApplicationMaster重试次数, 如果未设置, 则采用全局参数yarn.resourcemanager.am.max-attempts设置的值, 默认是2) 执行
ApplicationMasterService
ApplicationMasterService实现了RPC协议ApplicationMasterProtocol, 负责处理来自ApplicationMaster的请求,
请求主要包括注册、 心跳和清理三种:
注册是ApplicationMaster启动时发生的行为, 请求包中包含AM所在节点、 RPC端口号和trackingURL等信息;
心跳是周期性行为, 包含请求资源的类型描述、 待释放的Container列表等,而AMS为之返回新分配的Container、 失败的Container等信息;
清理是应用程序运行结束时发生的行为, ApplicationMaster向RM发送清理应用程序的请求, 以回收资源和清理各种内存空间
ApplicationMasterProtocol#allocate
❑请求资源;
❑获取新分配的资源;
❑形成周期性心跳, 告诉RM自己还活着。
ContainerExecutor
用于在底层操作系统上启动container的机制的抽象类。 所有的executor 必须继承ContainerExecutor.
ContainerExecutor可与底层操作系统交互, 安全存放Container需要的文件和目录, 进而以一种安全的方式启动和清除Container对应的进程。 目前,YARN提供了DefaultContainerExecutor和LinuxContainerExecutor两种实现
DefaultContainerExecuter 类提供通用的container执行服务. 负责启动Container . 是默认实现, 未提供任何权安全措施, 它以NodeManager启动者的身份启动和停止Container
LinuxContainerExecutor的核心设计思想是, 赋予NodeManager启动者以root权限, 进而使它拥有足够的权限以任意用户身份执行一些操作, 从而使得NodeManager执行者可以将Container使用的目录和文件的拥有者修改为应用程序提交者, 并以应用程序提交者的身份运行Container, 防止所有Container以NodeManager执行者身份运行进而带来的各种安全风险。 比如防止用户在Container中执行一些只有NodeManager用户有权限执行的命令(杀死其他应用程序的命令、 关闭或者杀死NodeManager进程等) 。
为了实现上述机制, NodeManager采用C语言实现了一个具有setuid功能的工具—container-executor, 它拥有root权限, 可以完成任意操作, 比如创建Cgroups层级树、 设置Cgroups属性(资源隔离)等。 LinuxContainerExecutor通过调用这个可执行文件可以修改Container的一些属性以限制Container的非法操作(比如关闭NodeManager、 杀死NodeManager等)
StateMachineFactory
YARN采用了基于事件驱动的并发模型, 该模型能够大大增强并发性, 从而提高系统整体性能。 为了构建该模型, YARN将各种处理逻辑抽象成事件和对应事件调度器, 并将每类事件的处理过程分割成多个步骤, 用有限状态机表示。
处理请求会作为事件进入系统, 由中央异步调度器(AsyncDispatcher) 负责传递给相应事件调度器(Event Handler) 。 该事件调度器可能将该事件转发给另外一个事件调度器, 也可能交给一个带有有限状态机的事件处理器, 其处理结果
也以事件的形式输出给中央异步调度器。 而新的事件会再次被中央异步调度器转发给下一个事件调度器, 直至处理完成(达到终止条件)
在YARN中, 所有核心服务实际上都是一个中央异步调度器, 包括ResourceManager、 NodeManager、 MRAppMaster等
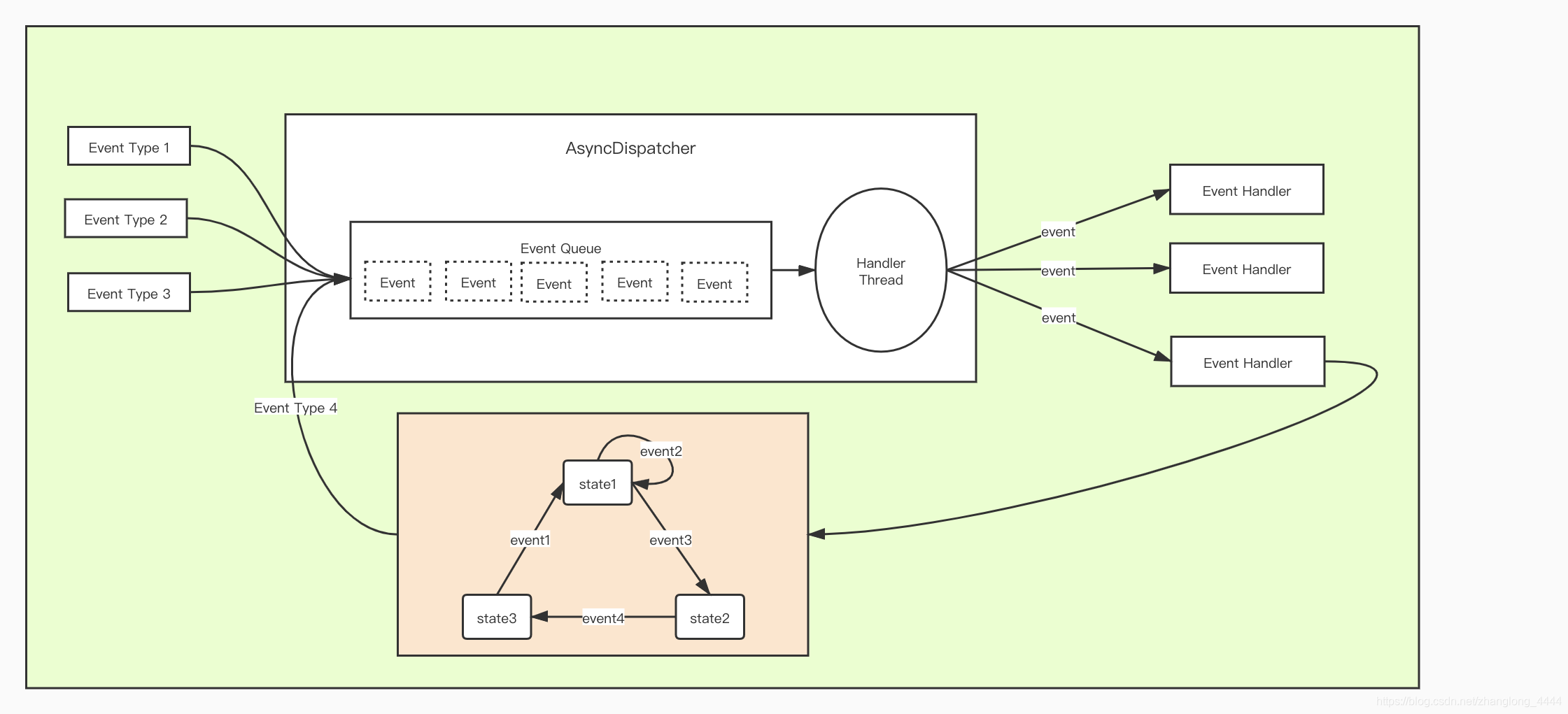
RMNodeImpl.stateMachineFactory nodemanager状态
public enum NodeState {
/** New node */
NEW,
/** Running node */
RUNNING,
/** Node is unhealthy */
UNHEALTHY,
/** Node is out of service 已经退役*/
DECOMMISSIONED,
/** Node has not sent a heartbeat for some configured time threshold*/
LOST,
/** Node has rebooted */
REBOOTED,
/** Node decommission is in progress 退役中*/
DECOMMISSIONING,
/** Node has shutdown gracefully. */
SHUTDOWN;
public boolean isUnusable() {
return (this == UNHEALTHY || this == DECOMMISSIONED
|| this == LOST || this == SHUTDOWN);
}
}**RMAppImpl.stateMachineFactory Application状态 **
public enum RMAppState {
NEW, //初始状态为NEW
NEW_SAVING, //记录应用程序基本信息时所处的状态,以便故障重启后可以自动恢复运行该应用程序
SUBMITTED,//通过合法性验证以及完成日志记录后, RM会创建了一个RMAppAttemptImpl对象, 以进行第一次运行尝试,并将Application( 运行) 状态置为SUBMITTED
ACCEPTED, //资源调度器同意接受该应用程序后所处状态
RUNNING, // 该应用程序的ApplicationMaster已经成功在某个节点上开始运行
FINAL_SAVING, //FINAL_SAVING状态表示正在保存RMAppImpl到存储器
FINISHING, //FINISHING状态表示RM上相应的App状态已经完成存储工作,在等待RMAppEventType.ATTEMPT_FINISHED事件。因为只有RMAppAttempt结束后RMApp才能结束。
FINISHED, //NodeManager通过心跳汇报ApplicationMaster所在的Container运行结束
FAILED,
KILLING,
KILLED
}RMAppAttemptImpl.stateMachineFactory AppAttempt状态
public enum RMAppAttemptState {
NEW, SUBMITTED, SCHEDULED, ALLOCATED, LAUNCHED, FAILED, RUNNING, FINISHING,
FINISHED, KILLED, ALLOCATED_SAVING, LAUNCHED_UNMANAGED_SAVING, FINAL_SAVING
}每个Application可能会尝试运行多次, 每次称为一次“运行尝试”(Application Attempt, 也可称为运行实例)
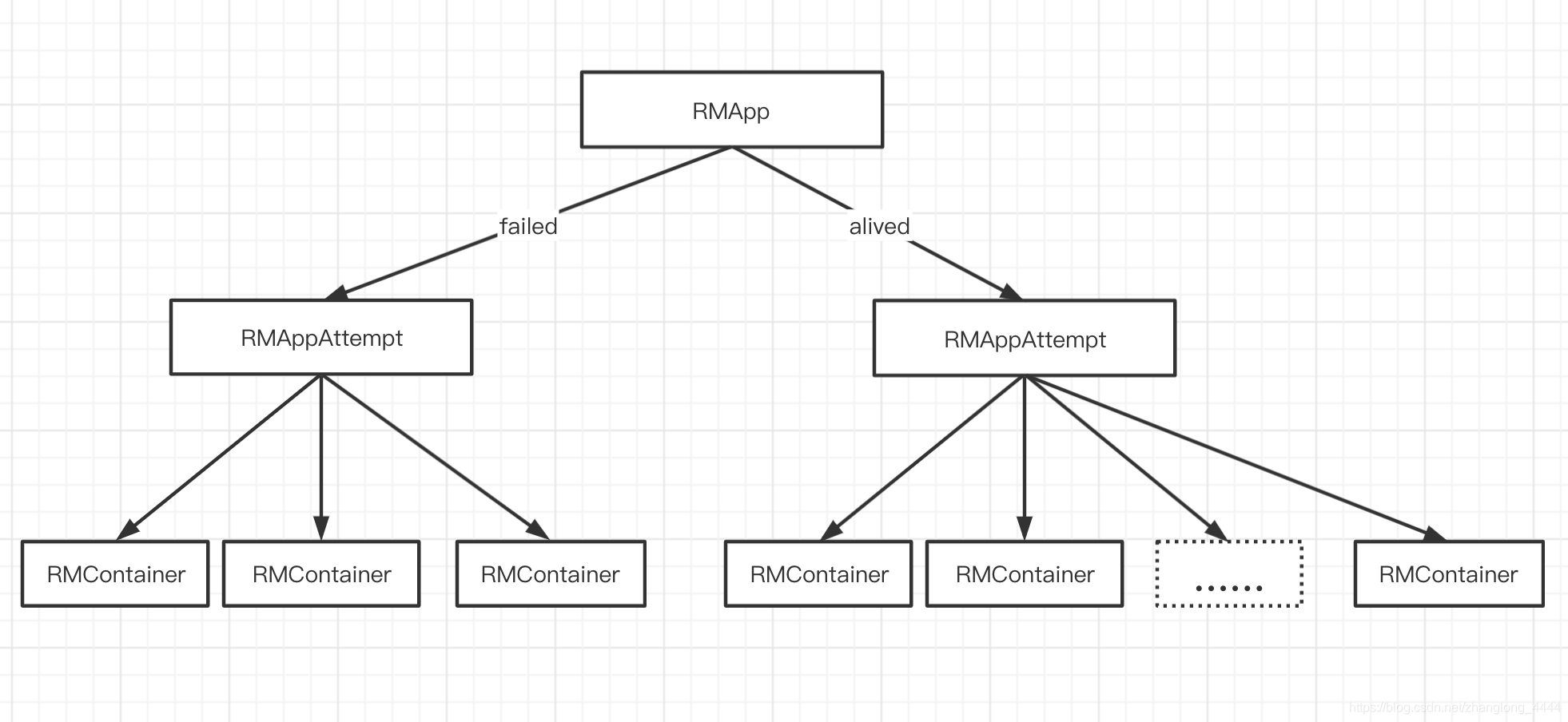
RMContainerImpl.stateMachineFactory Container状态
public enum RMContainerState {
NEW,
RESERVED,
ALLOCATED,
ACQUIRED,
RUNNING,
COMPLETED,
EXPIRED,
RELEASED,
KILLED
}
NodeManager节点健康检测
NodeManager自带的健康状况诊断机制, 通过该机制,NodeManager可时刻掌握自己的健康状况, 并及时汇报给ResourceManager。 而ResourceManager则根据每个NodeManager的健康状况适当调整分配的任务数目。 当NodeManager认为自己的健康状况“欠佳”时, 可通知ResourceManager不再为之分配新任务, 待健康状况好转时, 再分配任务。
NodeHealthCheckerService
该类提供了检查节点的运行状况并向其要求运行状况检查程序报告的服务的功能。
NodeManager上有专门一个服务判断所在节点的健康状况, 该服务通过两种策略判断节点健康状况,
- 通过管理员自定义的Shell脚本(NodeManager上专门有一个周期性任务执行该脚本, 一旦该脚本输出以”ERROR”开头的字符串, 则认为节点处于不健康状态)
yarn.nodemanager.health-checker.script.path健康检查脚本所在的绝对路径yarn.nodemanager.health-checker.script.opts健康检查脚本参数yarn.nodemanager.health-checker.interval-ms健康检查脚本检测周期 : 10minyarn.nodemanager.health-checker.script.timeout-ms健康检查脚本超时时间 : 20min
- 另一种是判断磁盘好坏(NodeManager上专门有一个周期性任务检测磁盘的好坏, 如果坏磁盘数目达到一定的比例, 则认为节点处于不健康状态)
yarn.nodemanager.disk-health-checker.enable启用该功能yarn.nodemanager.disk-health-checker.min-healthy-disks(默认是0.25) , 就认为该节点处于“不健康”的状态
程序文件目录&分布式缓存
分布式缓存
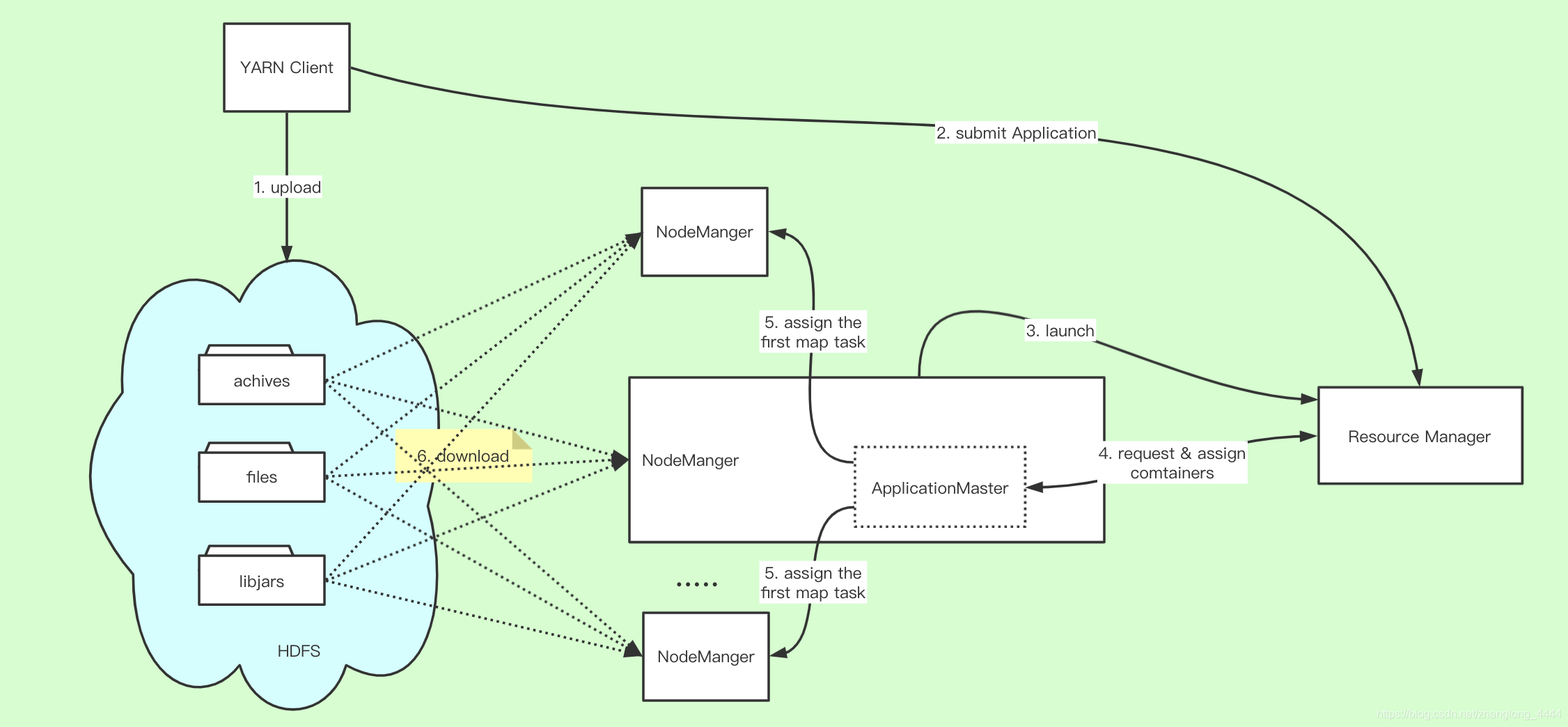
Distribute cache , mapjoin 就是先将文件缓存到本地
- 步骤1 客户端将应用程序所需的文件资源(外部字典、 JAR包、 二进制文件等) 提交到HDFS上。
- 步骤2 客户端将应用程序提交到ResourceManager上。
- 步骤3 ResourceManager与某个NodeManager通信, 启动应用程序ApplicationMaster,NodeManager收到命令后, 首先从HDFS下载文件(缓存) , 然后启动ApplicationMaster。
- 步骤4 ApplicationMaster与ResourceManager通信, 以请求和获取计算资源。
- 步骤5 ApplicationMaster收到新分配的计算资源后, 与对应的NodeManager通信, 以启动任务。
- 步骤6 如果该应用程序第一次在该节点上启动任务, 则NodeManager首先从HDFS上下载文件缓存到本地, 然后启动任务。
- 步骤7 NodeManager后续收到启动任务请求后, 如果文件已在本地缓存, 则直接运行任务, 否则等待文件缓存完成后再启动。
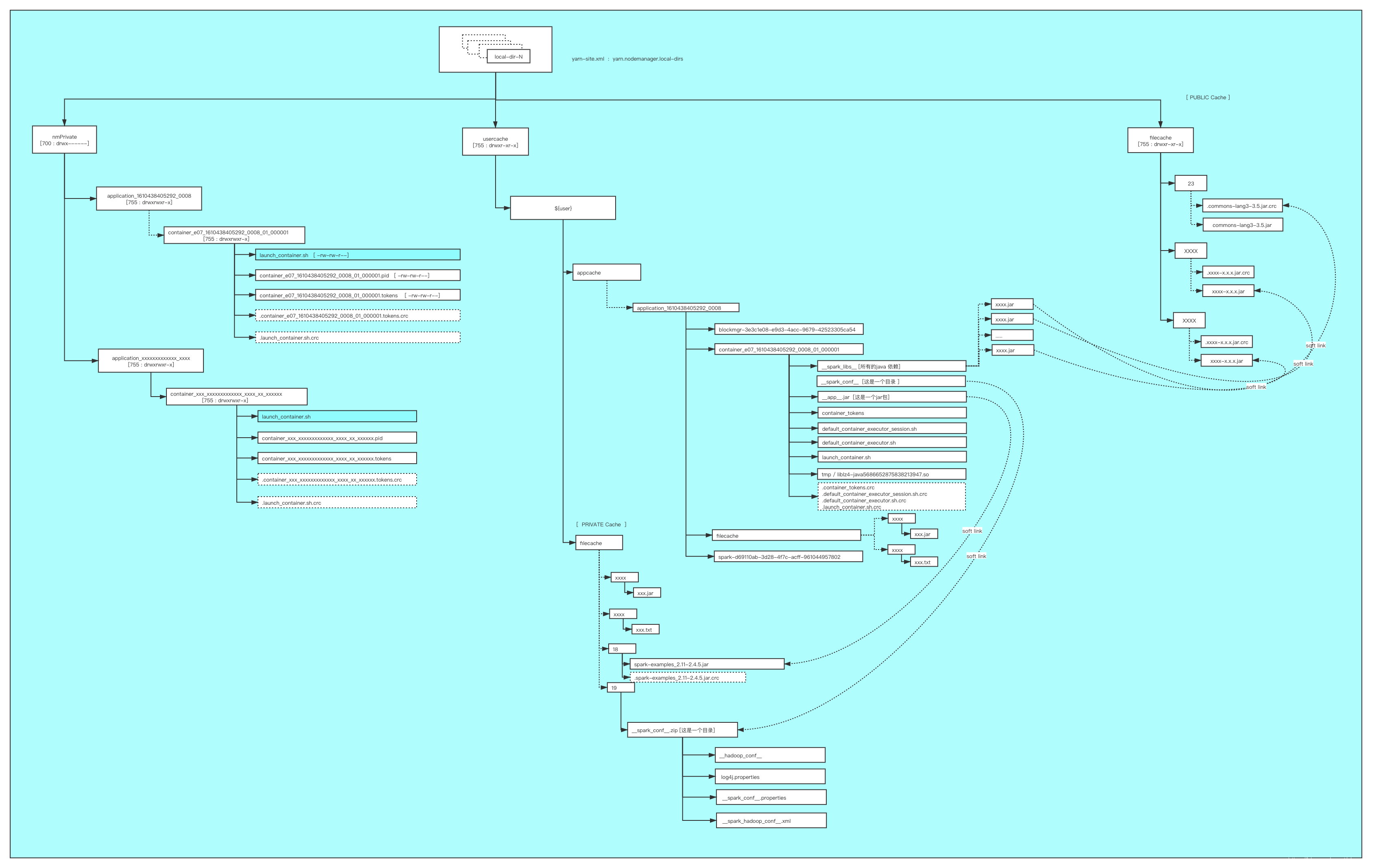
资源分类
PUBLIC 资源:存放在
${yarn.nodemanager.local-dirs}/filecache/目录下,每个资源将单独存放在以一个随机整数命名的目录中PRIVATE 资源:存放在
${yarn.nodemanager.local-dirs}/usercache/${user}/filecache/目录下,每个资源将单独存放在以一个随机整数命名的目录中APPLICATION 资源:存放在
${yarn.nodemanager.local-dirs}/usercache/${user}/${appcache}/${appid}/filecache/目录下,每个资源将单独存放在以一个随机整数命名的目录中
Container 的工作目录位于 ${yarn.nodemanager.local-dirs}/usercache/${user}/${appcache}/${appid}/${containerid} 目录下,其主要保存 jar 包文件、字典文件对应的软链接
假设某个NodeManager上通过参数yarn.nodemanager.local-dirs配置了N个目录/mnt/disk0,/mnt/disk1,…/mnt/diskN-1, 且这N个目录正好挂在了N个不同的磁盘, 某一时刻用户提交了一个ID为appid的应用程序, 该应用程序需要K个Container, 则NodeManager为该作业创建的目录。
NodeManager在每个磁盘上为该作业创建了相同的目录结构, 且采用轮询的调度方式将目录(磁盘) 分配给不同的Container的不同模块以避免干扰,并且提高读写io
数据目录结构
日志目录
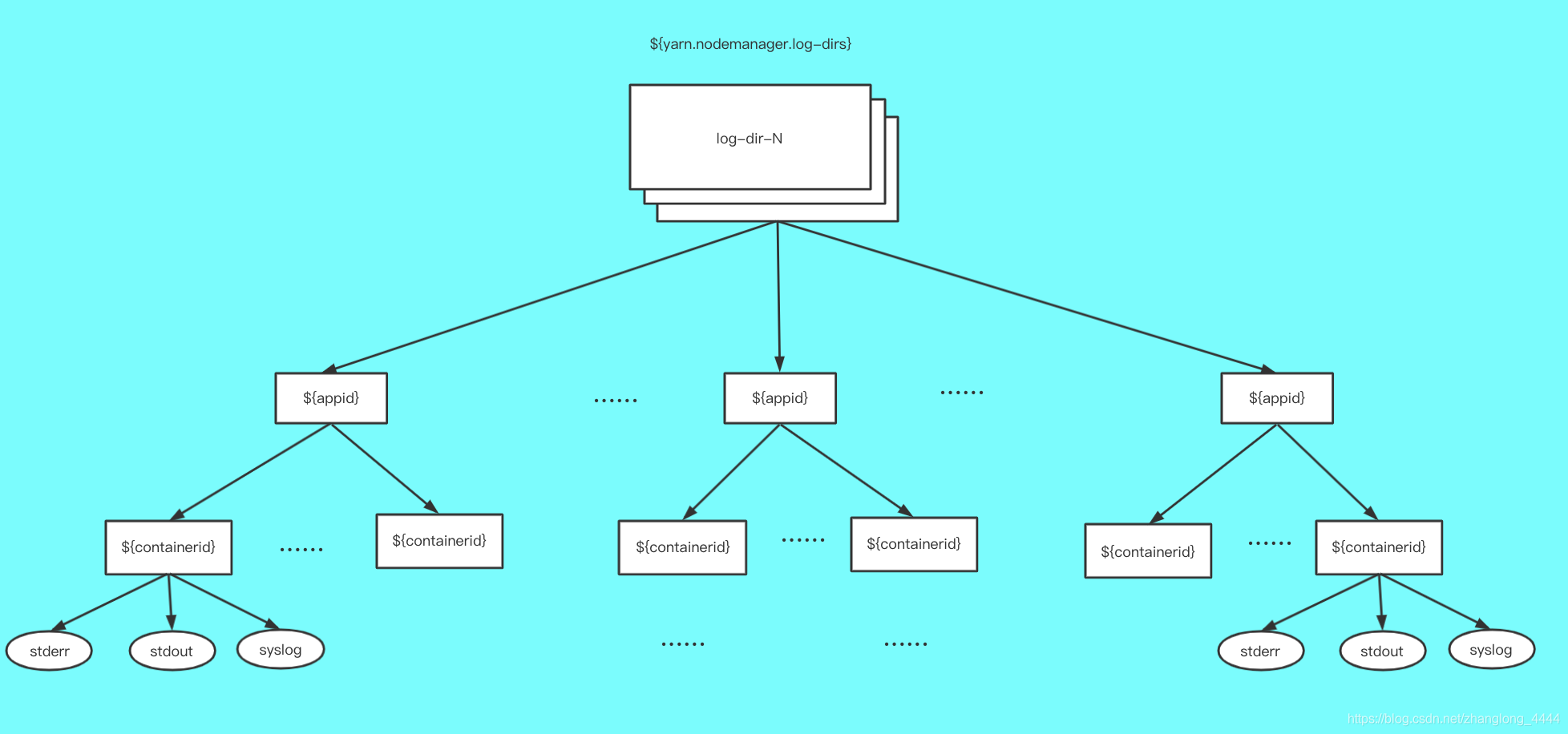
yarn.nodemanager.log-dirs
日志清理机制
(1) 定期删除
NodeManager允许一个应用程序日志在磁盘上的保留时间为yarn.nodemanager.log.retain-seconds(单位是秒, 默认为3×60×60, 即3小时) , 一旦超过该时间, NodeManager会将该应用程序所有日志从磁盘上删除。
(2) 日志聚集转存
除定期删除外, NodeManager还提供了另一种日志处理方式——日志聚集转存, 管理员可通过将配置参数yarn.log-aggregation-enable置为true启用该功能。 该机制将HDFS作为日志聚集仓库, 它将应用程序产生的日志上传到HDFS上, 以便统一管理和维护。
当一个应用程序运行结束时, 它产生的所有日志将被统一上传到HDFS上的${remoteRootLogDir}/${user}/${suffix}/${appid}目录中(${remoteRootLogDir}值由参数yarn.nodemanager.remote-app-log-dir指定, 默认是”/tmp/logs”; ${user}为应用程序拥有者;${suffix}值由参数yarn.nodemanager.remote-app-log-dir-suffix指定, 默认是”logs”; ${appid}为应用程序ID) , 且同一个节点中所有日志保存到该目录中的同一个文件, 这些文件以节点ID命名
一旦日志全部上传到HDFS后, 本地磁盘上的日志文件将被删除。 此外, 为了减少不必要的日志上传, NodeManager允许用户指定要上传的日志类型。 当前支持的日志类型有三种: ALL_CONTAINERS(上传所有Container日志) 、APPLICATION_MASTER_ONLY(仅上传ApplicationMaster产生的日志) 和AM_AND_FAILED_CONTAINERS_ONLY(上传ApplicationMaster和运行失败的Container产生的日志) , 默认情况下采用ALL_CONTAINERS。
转存到HDFS上的日志的生命周期不再由NodeManager负责, 而是由JobHistory服务管理。每个日志文件最多存留时间为yarn.log-aggregation.retainseconds(单位是秒, 默认为3×60×60, 即3小时
Yarn资源调度策略
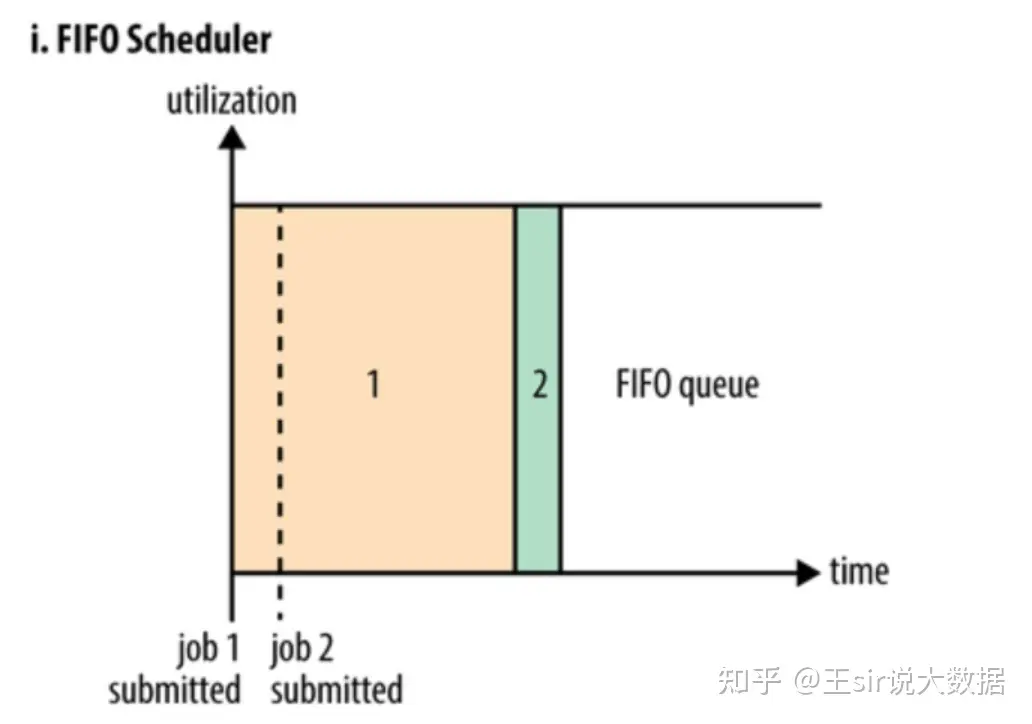
FIFO Scheduler
FIFO是Hadoop设计之初提供的一个最简单的调度机制: 即先来先服务。所有应用程序被统一提交到一个队里中,Hadoop按照提交顺序依次运行这些作业。只有等先来的应用程序资源满足后,再开始为下一个应用程序进行调度运行和分配资源。
无法适应多租户资源管理。先来的大应用程序把集群资源占满,导致其他用户的程序无法得到及时执行。也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿
Capacity Scheduler
每个队列设置资源最低保证(capacity)和资源使用上限(maximum-capacity,默认100%),即设置一个资源占比,这样可以保证每个队列都不会占用整个集群的资源,而所有提交到该队列的应用程序可以共享这个队列中的资源。
如果队列中的资源有剩余或者空闲,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序需要资源运行,则其他队列释放的资源会归还给该队列(非强制回收),从而实现弹性灵活分配调度资源,提高系统资源利用率,直到恢复到各个队列设置的比例
支持多用户共享集群资源和多应用程序同时运行。且可对每个用户可使用资源量(user-limit-factor)设置上限。
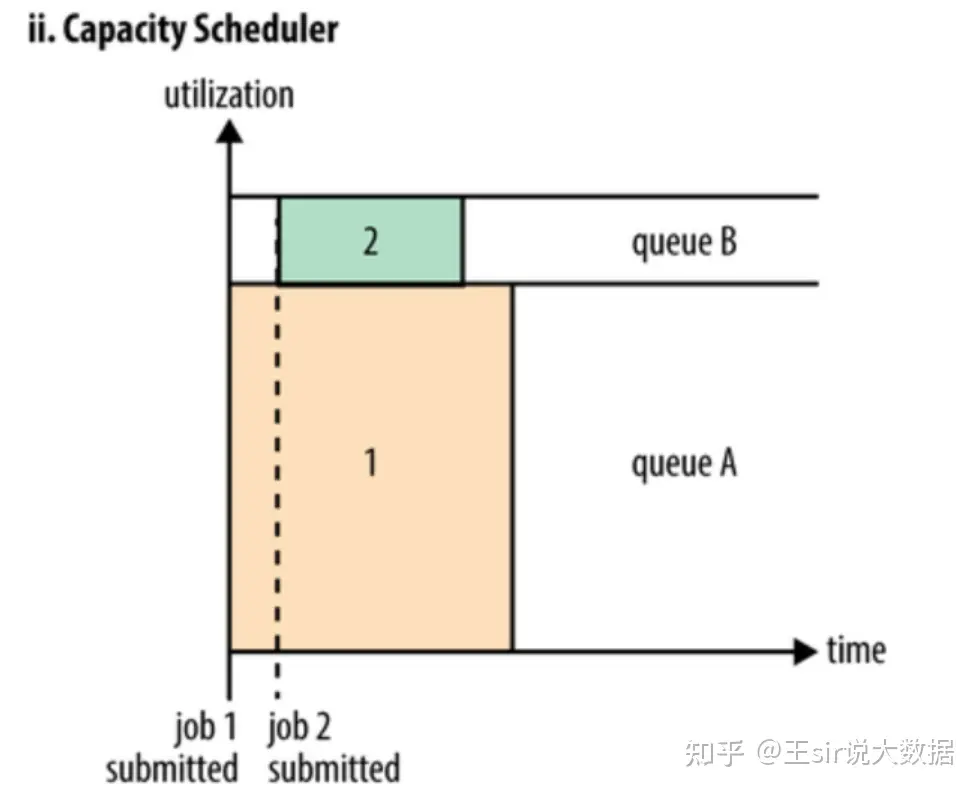
Fair Scheduler
与Capacity Scheduler不同点
- 每个队列中,Fair Scheduler可选择FIFO、Fair(默认,只考虑内存)或者DRF(考虑内存和vcore)策略(SchedulingPolicy)为应用程序分配资源。默认情况下,每个队列内部采用Fair策略方式分配资源。
- 队列空闲资源被共享给其他队列后,如果再提交用户程序,需要计算资源,调度器需要为它回收资源。为了尽可能降低不必要的计算浪费,调度器采用了先等待再强制回收的策略。如果等待一段时间后尚有未归还的资源,则会进行资源抢占:从超额使用资源的队列中杀死一部分任务,进而释放资源。
什么情况下会发生抢占
1)最小资源抢占, 当前queue的资源无法保障时,而又有apps运行,需要向外抢占。
2)公平调度抢占, 当前queue的资源未达到max,而又有apps运行,需要向外抢占。
抢占过程?
- 步骤1 RM 探测到需要抢占的资源**(UpdateThread),并标注**这些待抢占的Container。
- 步骤2 RM收到AppMaster的心跳信息,并通过心跳应答将待释放的资源总量和待抢占的Container列表返回给AppMaster。它收到这些Container列表。可以选择如下操作:
- 杀死这些Container。
- 选择并杀死其他Container以凑够总量。
- 不做任何处理,过段时间可能有container自行释放资源或者由RM杀死Container。
- 步骤3 RM探测到一段时间内,AppMaster未自行杀死约定的Container,则将这些Container标注。等收到这些Container所在NM的心跳信息后,并通过心跳应答将待杀死的Container列表返回给它,NM将这些容器杀死,并通过心跳告知RM。
- 步骤4 RM收到AppMaster的心跳信息后,并通过心跳应答将已经杀死的Container列表发送给它(也有可能AppMaster早已经通过内部通讯机制获取到这些Container已经被杀死)。
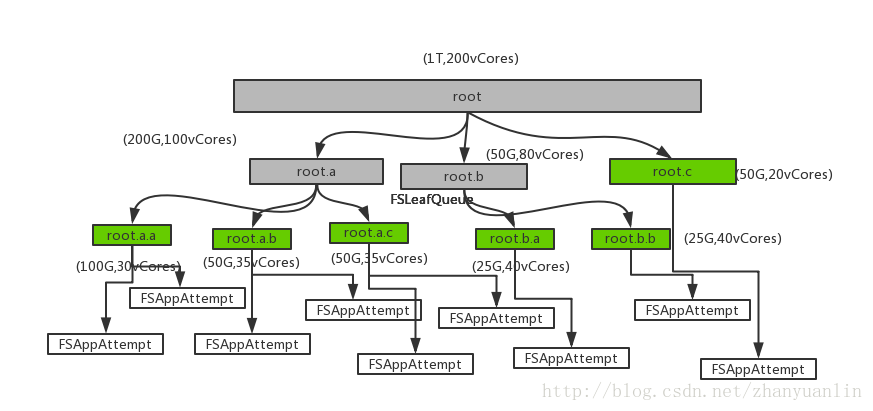
Yarn基于树的队列管理逻辑,在资源层面,无论是树的根节点(root 队列),非根节点、叶子节点,都是资源的抽象,在Yarn中,都是一个Schedulable,因此,无论是FSLeafQueue(队列树的叶子节点), 还是FSParentQueue(队列树的非叶子节点),或者是FSAppAttempt(FairScheduler调度器层面的应用),是实现了Schedulable的preemptContainer()方法,他们都有自己的fair share属性(资源量)、weight属性(权重)、minShare属性(最小资源量)、maxShare属性(最大资源量),priority属性(优先级)、resourceUsage属性(资源使用量属性)以及资源需求量属性(demand)
根据Yarn的设计,由于资源抢占本身是一种资源的强行剥夺,会带来一定的系统开销。因此,Yarn会在实际抢占发生前,耐心等待一段时间,以尽量直接使用其它应用释放的资源来使用,而尽量避免使用抢占的方式。
因此,我们在FairScheduler.xml中,需要配置这两个超时时间:
minSharePreemptionTimeout 表示如果超过该指定时间,Scheduler还没有获得minShare的资源,则进行抢占fairSharePreemptionTimeout 表示如果超过该指定时间,Scheduler还没有获得fairShare的资源,则进行抢占
抢占从root queue开始,找出一个可以被抢占的container进行抢占。决策和遍历过程实际上是一个递归调用的过程,从root queue开始,不断由下级队列决定抢占自己下一级的哪个queue或者application或者container最终,是由LeafQueue选择一个Application,然后Application选择一个Container,由于都实现了Schedulable接口,且维护在同一个树下面,不断递归调用即可实现
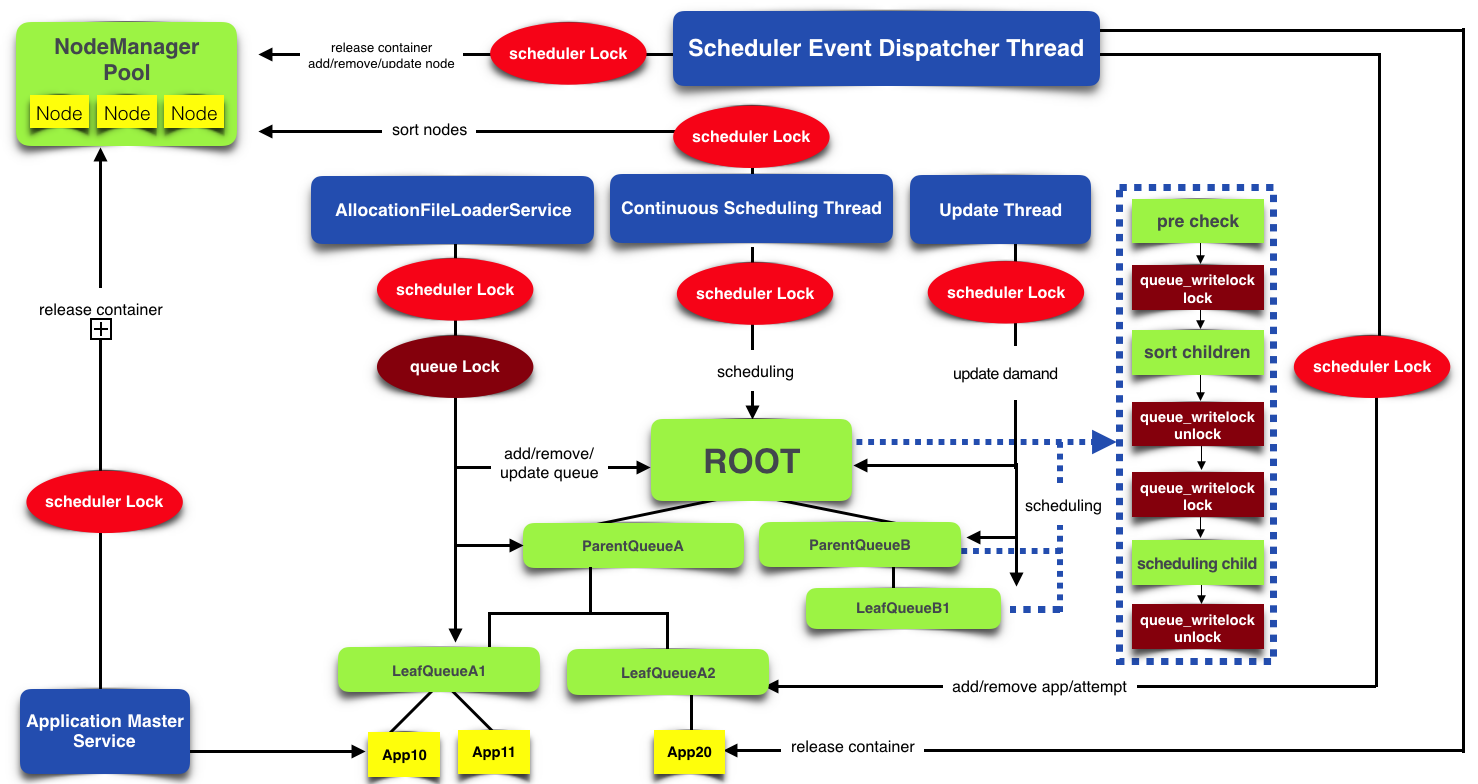
两种调度时机-心跳调度和持续调度
心跳调度 :Yarn的NodeManager会通过心跳的方式定期向ResourceManager汇报自身状态,当NodeManager向ResourceManager汇报了自身资源情况(比如,当前可用资源,正在使用的资源,已经释放的资源),这个RPC会触发ResourceManager调用nodeUpdate()方法,这个方法为这个节点进行一次资源调度,即,从维护的Queue中取出合适的应用的资源请求(合适 ,指的是这个资源请求既不违背队列的最大资源使用限制,也不违背这个NodeManager的剩余资源量限制)放到这个NodeManager上运行。这种调度方式一个主要缺点就是调度缓慢,当一个NodeManager即使已经有了剩余资源,调度也只能在心跳发送以后才会进行,不够及时。
连续资源调度:不用等待NodeManager向ResourceManager发送心跳才进行任务调度,而是由一个独立的线程(ContinuousSchedulingThread)进行的资源分配等调度,与NodeManager的心跳出发的调度相互异步并行进行。当心跳到来,只需要把调度结果通过心跳响应告诉对应的NodeManager即可。可能会加重锁冲突影响性能
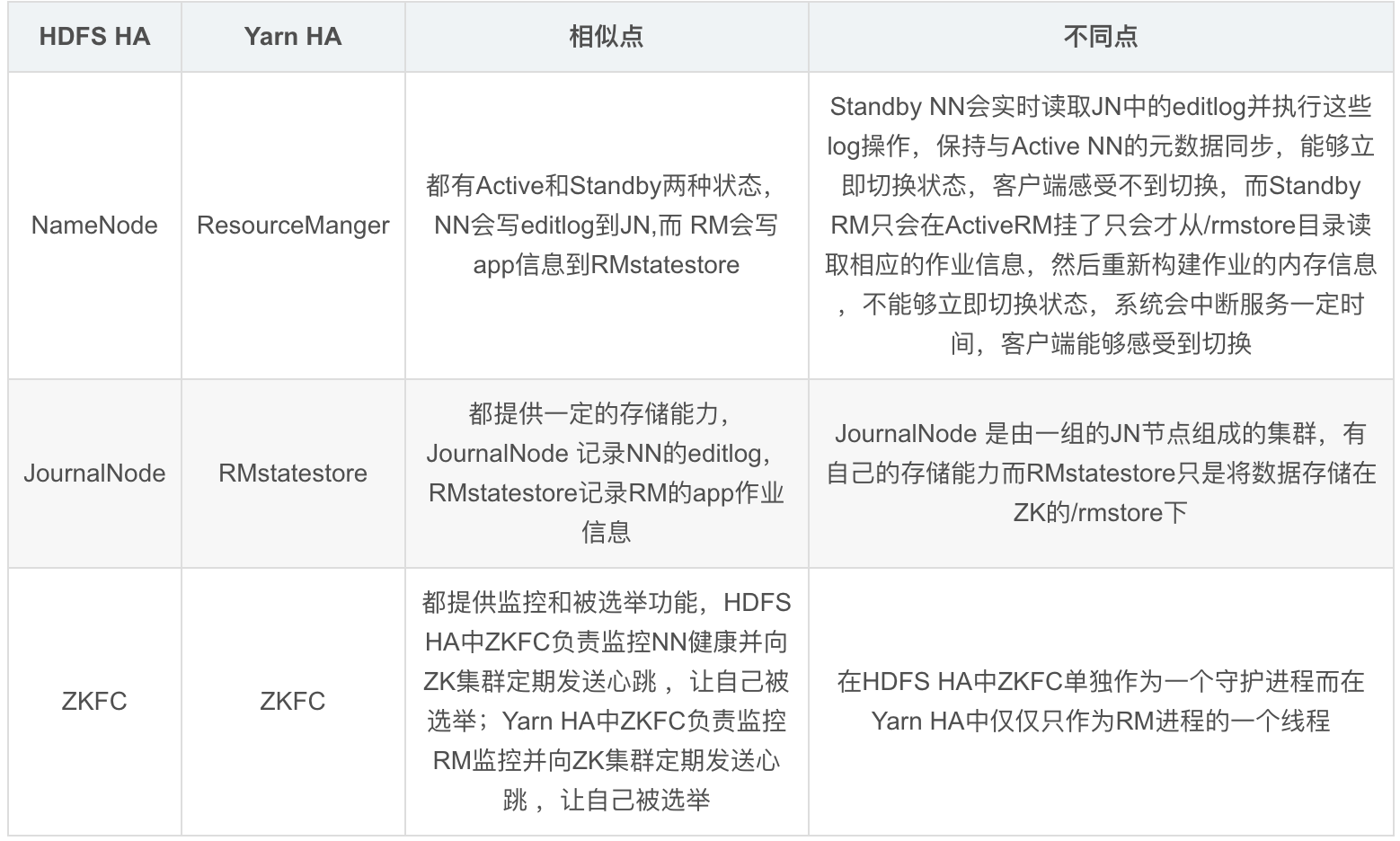
HDFS HA和YARN HA架构区别
Spark
Spark yarn集群模式提交流程
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/export/servers/spark/examples/jars/spark-examples_2.11-2.0.2.jar \
10
1.spark-submit
执行org.apache.spark.deploy.SparkSubmit 的main方法
2.反射
根据不同的运行环境和部署模式反射不同的实例
yarn集群模式下反射执行org.apache.spark.deploy.yarn.YarnClusterApplication的start()方法
3.new org.apache.spark.deploy.yarn.Client().run()
构造函数创建 YarnClient 与yarn通信
submitApplication 在yarn上申请一个application
如果是集群模式则向yarn提交:org.apache.spark.deploy.yarn.ApplicationMaster
4.ApplicationMaster.main
new ApplicationMaster().run()
如果是集群模式runDriver()
启动一个线程使用反射的方式启动用户程序(shell提交的– class)
这个线程的名称就叫Driver
在用户程序中创建SparkContext
_taskScheduler.postStartHook()唤醒主线程,并阻塞当前线程
主线程等待Driver线程的唤醒(通过ApplicationMaster静态变量sparkContextPromise)
主线程被Driver线程唤醒后
向RM注册Application Master
向RM申请container资源,
在container中启动org.apache.spark.executor.YarnCoarseGrainedExecutorBackend
环境准备完成,唤醒Driver线程继续执行用户逻辑
5.YarnCoarseGrainedExecutorBackend
向driver注册RegisterExecutor
注册成功后 实例化 new org.apache.spark.executor.Executor 内部 维护了最终执行task的线程池
向driver注册 LaunchedExecutor
Spark yarn客户端模式提交
2.反射
这里与集群模式的差异在于 反射时 直接反射用户程序(shell提交的– class)
3.执行用户程序
执行用户程序并没有提交到yarn
创建SparkContext
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
匹配masterUrl
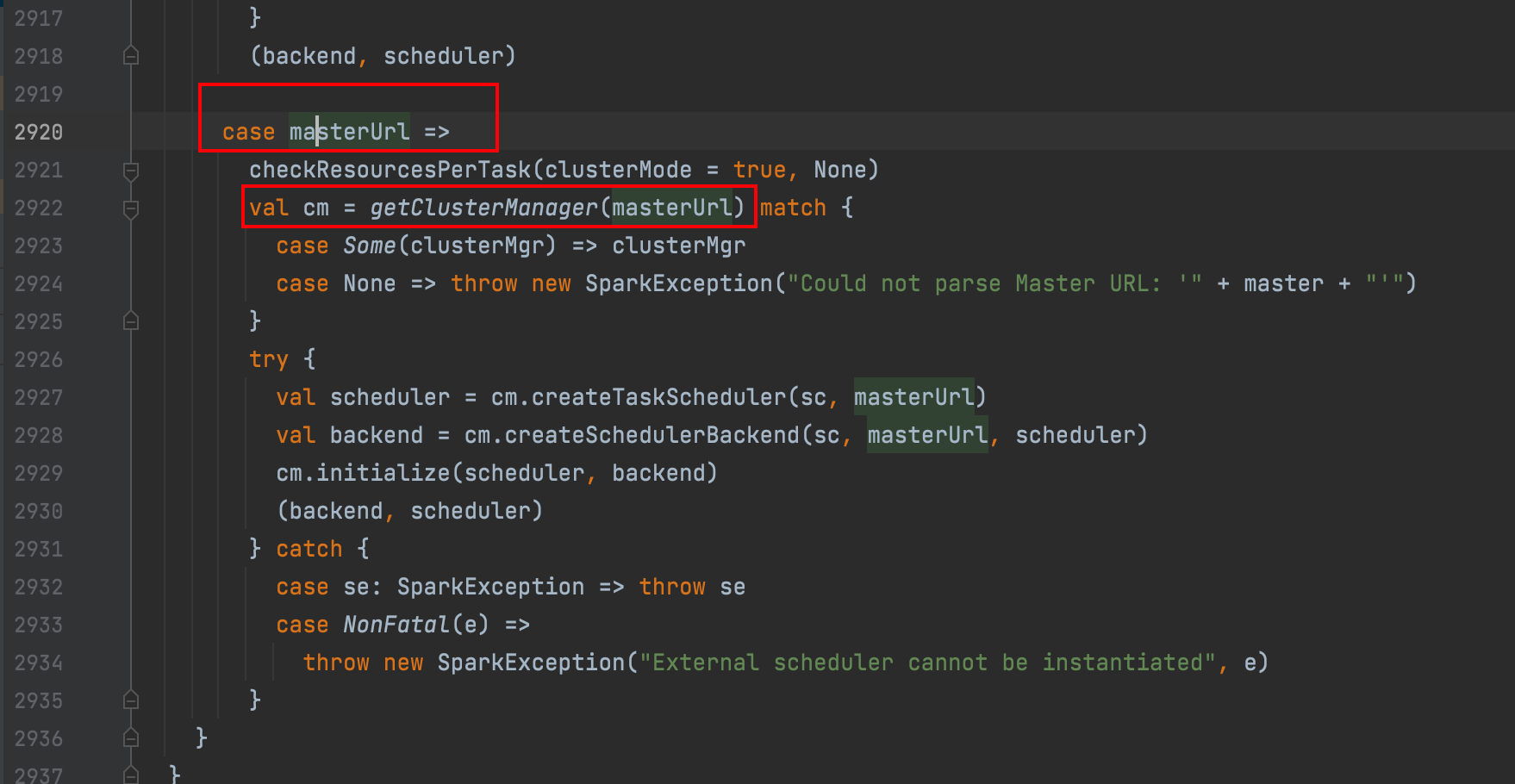
getClusterManager
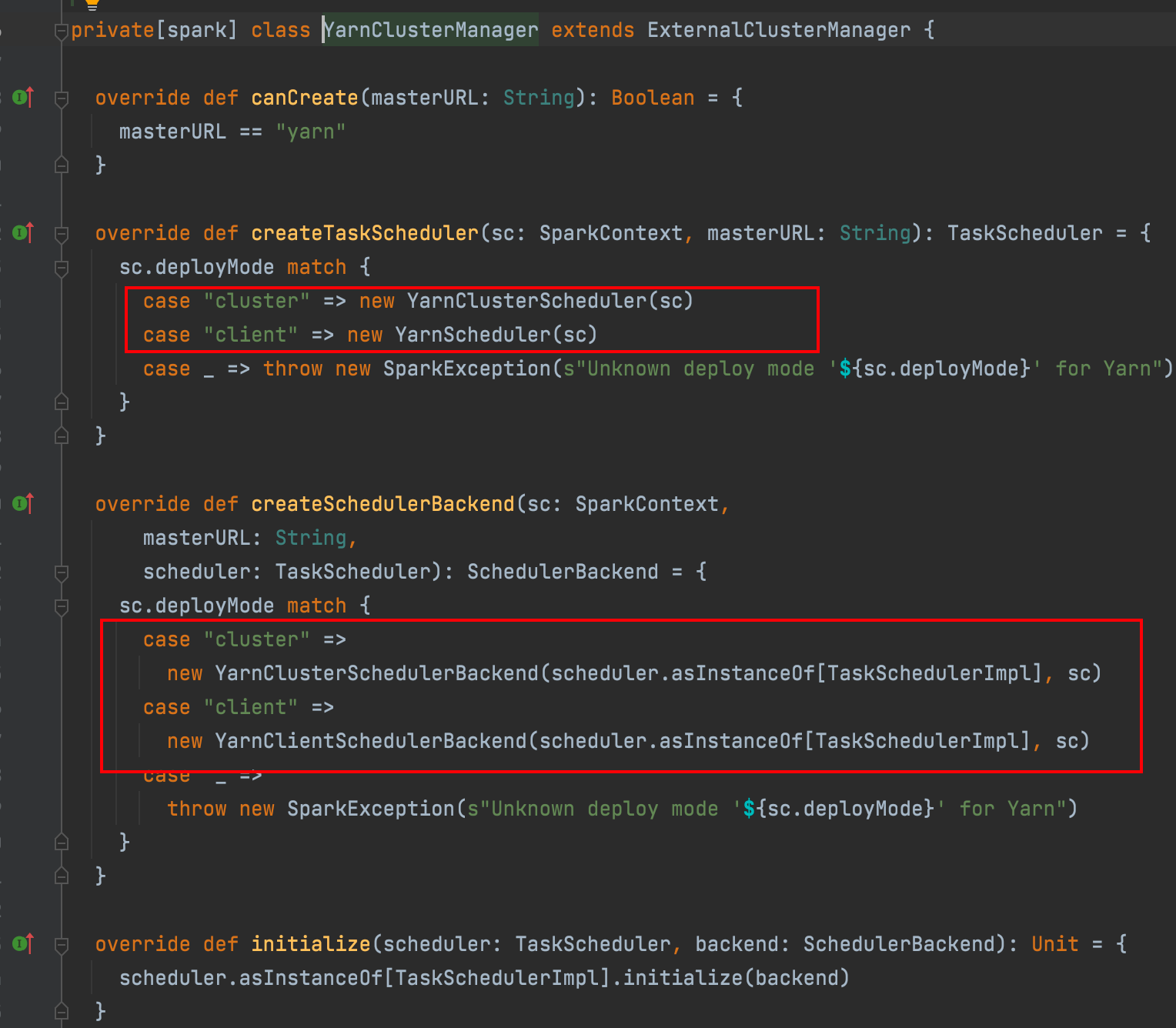
schedulerBackend实例为YarnClientSchedulerBackend,然后在这里实例化Client() 也就和集群模式类似了
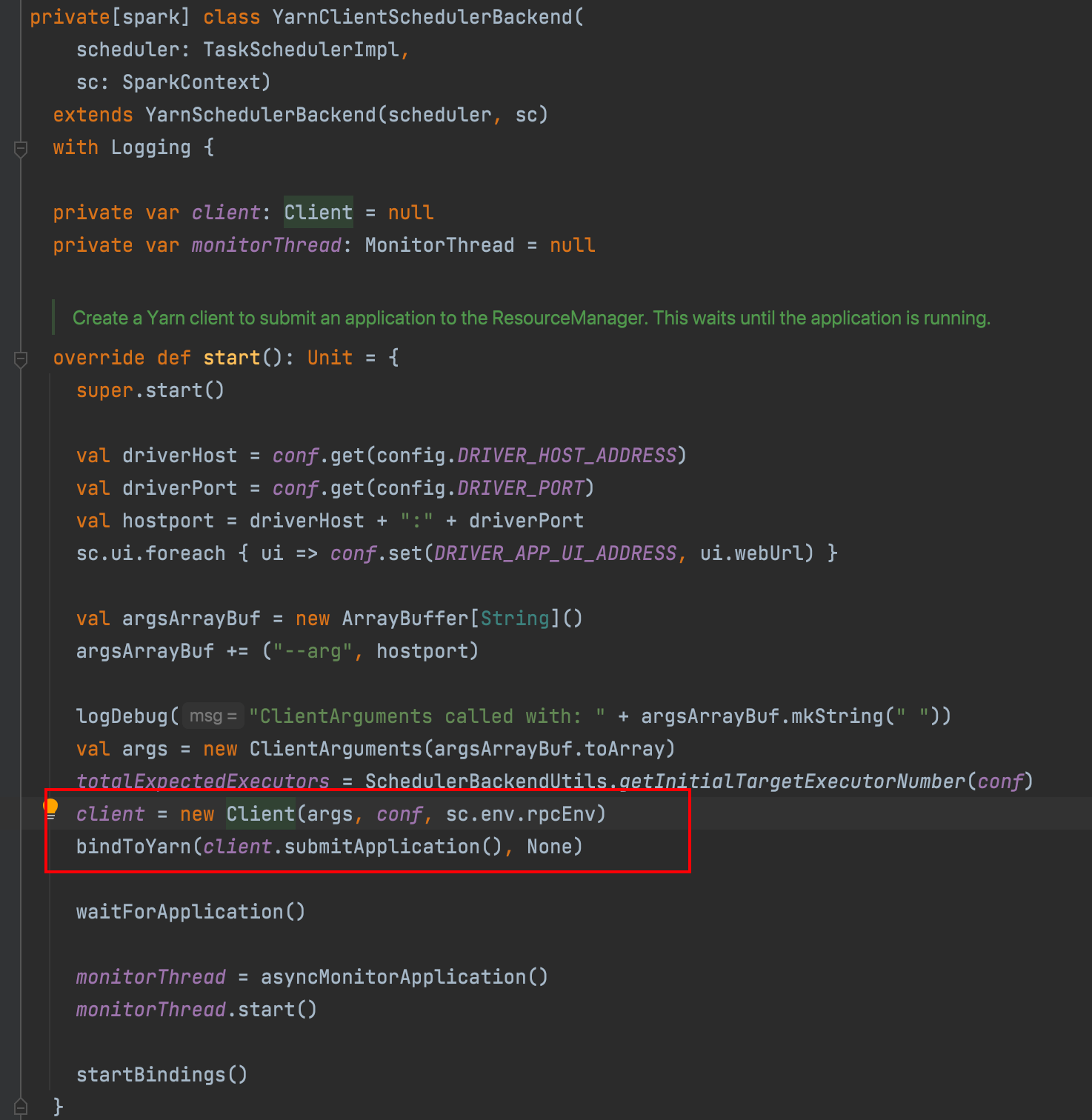
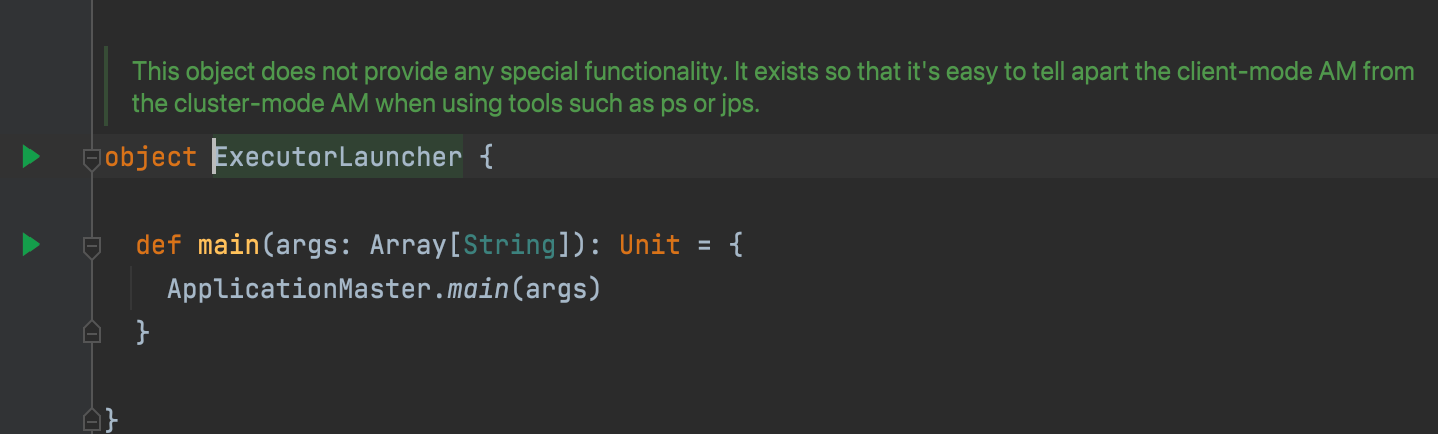
向yarn提交:org.apache.spark.deploy.yarn.ExecutorLauncher

runDriver 需要启动driver线程执行用户代码 和申请资源
runExecutorLauncher 只负责资源
cluster模式下和client模式下AM执行的入口类是不同的,在cluster模式下,AM进程既要执行Driver,也要负责Executor的资源申请和调度。而在client模式下,客户端spark-submit进程充当着Driver的角色,AM只负责Executor的资源调度
本质上跟cluster模式执行的入口类是一样的,ExecutorLauncher为了区别出与cluster AM进程的不同,如使用ps, jps工具
在没有开启动态分配的情况下,Executor的启动并没有依赖于task的任务,他跟Driver的运行几乎是同步的。也就是说Executor是不知道task的数据本地化策略的,所以container是随机分配的。
Spark动态Executor机制
用户提交Spark应用到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor个数,随后,ApplicationMaster会为这些executor申请资源,每个executor作为一个Container在Yarn上运行。Spark调度器会把Task按照合适的策略分配到executor上执行。所有任务执行完后,executor被杀死,应用结束。在job运行的过程中,无论executor是否领取到任务,都会一直占有着资源不释放。生命周期与job一致。
spark动态资源分配默认是不开启的,并且只要设置了num-executors设置了作业的executor数,就不再有效
开启动态分配策略后,会按照事先的配置,启动最小的集群资源,比如申请一个executor。当一段时间没有执行任务后,executor会因长期空闲而被释放掉,资源也会被yarn一类的资源调度框架回收。当再次接收到命令时,会重新向资源调度框架申请资源运行任务。也就是说当应用没有任务提交时,不会占用集群的过多资源,提前释放以供其他应用使用,这样整个集群的资源利用率就更高了。
如果Executor中缓存了数据,那么该Executor的Idle-timeout时间就不是由executorIdleTimeout决定,而是用spark.dynamicAllocation.cachedExecutorIdleTimeout控制,默认值:Integer.MAX_VALUE。如果手动设置了该值,当这些缓存数据的Executor被kill后,我们可以通过NodeManannger的External Shuffle Server来访问这些数据。这就要求NodeManager中spark.shuffle.service.enabled必须开启。
spark.dynamicAllocation.enabled
默认值,false
是否使用动态资源分配,将会动态扩展executor的数量。
spark.dynamicAllocation.executorIdleTimeout
默认值,60s
executor空闲多长时间会被回收。
spark.dynamicAllocation.cachedExecutorIdleTimeout
默认值,infinity
exectuor缓存数据的时间,超过这个时间还是空闲状态,将会移除executor
spark.dynamicAllocation.initialExecutors
默认值,spark.dynamicAllocation.minExecutors
如果配置了 --num-executors 或 spark.execturo.instancese,则优先使用这两个参数的配置。
spark.dynamicAllocation.maxExecutors
默认值,infinity
exectuors的上限
spark.dynamicAllocation.minExecutors
默认值,0
executors的下限
spark.dynamicAllocation.executorAllocationRatio
默认值,1
一般spark会使用动态分配申请足够多的资源来保证任务进程的并行度。这样会最小化任务的延迟。对于一些小任务,这个配置会导致浪费很多资源,并且其他的executor可能并没有做任何工作。1提供最大的并行度,0.5则会将exectuor的数量减半。
spark.dynamicAllocation.schedulerBacklogTimeout
默认值,1s
待执行的任务积压超过这个时间,将会请求新的执行者。
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout
默认值,schedulerBacklogTimeout
资源不足时,多长时间开始申请executor。SparkJob提交流程
Action算子会触发
sparkContext.runJob()最终调用
dagScheduler.runJob,然后如果有checkPoint会执行checkPoint在dagScheduler中触发JobSubmitted事件,由
handleJobSubmitted处理事件根据rdd的依赖进行stage的划分,从最后一个rdd递归往前划分遇到宽依赖就生成一个stage(ShuffleMapStage),最后一个stage是ResultStage
生成一个ActiveJob ,将job赋值给finalStage,并提交finalStage
提交finalStage时如果有parentStage,则先提交parentStage,自己加入到等待列表
如果没有未执行完毕的parentStage,那就提交stage的Tasks,
submitMissingTasks- 获取stage中需要计算的partition(分区数量与task数量一致)
- 获取每个partition数据所在位置
- 创建taskBinaryBytes(rdd+计算逻辑序列化)
- 包装为ShuffleMapTask和ResultTask
- 将tasks封装成一组TaskSet,交给TaskScheduler处理,实现在
taskScheduler.submitTasks()
创建TaskSetManager
将TaskSetManager添加到schedulableBuilder中,schedulableBuilder中有调度池,调度模式有FIFO和FAIR,决定了TaskSetManager调度的先后顺序。
通知SchedulerBackEnd开始进行任务分发
根据TaskSetManager的调度策略(FIFO,FAIR)和本地化策略(PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY) 分配task
launchTasks,向executor发送LaunchTask事件
executor执行
Spark driver中的几个组件(不完整)
DAGScheduler
将 RDD 转换操作划分为多个阶段
TaskScheduler
任务分发到各个 Executor 上执行
SchedulerBackend
通信
BlockManager
管理数据块(Block)的存储和检索,包括RDD的持久化数据
BroadcastManager
广播
Spark的数据本地化和延迟调度策略
Spark数据本地化即计算向数据移动,但数据块所在的Executor不一定有足够的的计算资源提供,为了让task能尽可能的以最优本地化级别(Locality Levels)来启动,Spark的延迟调度应运而生,资源不够可在该Locality Levels对应的限制时间内重试,超过限制时间后还无法启动则降低Locality Levels再尝试启动。
几种本地化级别:
- 1.PROCESS_LOCAL:进程本地化,表示 task 要计算的数据在同一个 Executor 中。
- 2.NODE_LOCAL: 节点本地化,速度稍慢,因为数据需要在不同的进程之间传递或从文件中读取。分为两种情况,第一种:task 要计算的数据是在同一个 worker 的不同 Executor 进程中。第二种:task 要计算的数据是在同一个 worker 的磁盘上,或在 HDFS 上恰好有 block 在同一个节点上。如果 Spark 要计算的数据来源于 HDFS 上,那么最好的本地化级别就是 NODE_LOCAL。
- 3.NO_PREF: 没有最佳位置,数据从哪访问都一样快,不需要位置优先。比如 Spark SQL 从 Mysql 中读取数据。
- 4.RACK_LOCAL:机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据以及文件 IO,比 NODE_LOCAL 慢。
- 5.ANY:跨机架,数据在非同一机架的网络上,速度最慢。
1.PROCESS_LOCAL
TaskScheduler 根据数据的位置向数据节点发送 Task 任务。如果这个任务在 worker1 的 Executor 中等待了 3 秒。(默认的,可以通过spark.locality.wait 来设置),可以通过 SparkConf() 来修改,重试了 5 次之后,还是无法执行,TaskScheduler 就会降低数据本地化的级别,从 PROCESS_LOCAL 降到 NODE_LOCAL。
2.NODE_LOCAL
TaskScheduler 重新发送 task 到 worker1 中的 Executor2 中执行,如果 Task 在worker1 的 Executor2 中等待了 3 秒,重试了 5 次,还是无法执行,TaskScheduler 就会降低数据本地化的级别,从 NODE_LOCAL 降到 RACK_LOCAL。
宽窄依赖
窄依赖
父rdd一个分区的只对应子rdd一个分区
宽依赖
父rdd的一个分区对应子rdd的多个分区
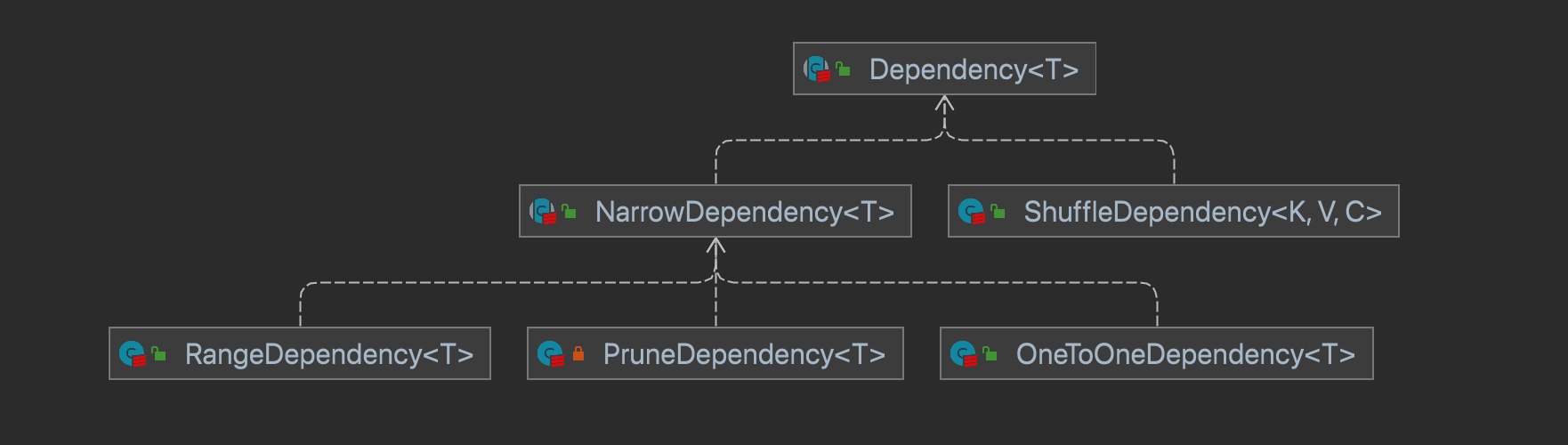
- NarrowDependency 窄依赖
- RangeDependency 子分区依赖多个父分区
- PruneDependency 裁剪 过滤部分父分区
- OneToOneDependency 一对一
- ShuffleDependency 宽依赖
SparkShuffle
写数据:
org.apache.spark.scheduler.ShuffleMapTask#runTask->dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition)- 如果有预聚合 执行预聚合
- maybeSpillCollection ,根据预估内存占用(抽样)判断是否需要溢写
- 如果溢写将内存中的数据按照分区+key排序写到临时文件和临时索引
- 合并临时文件(没有再次预聚合)
读数据:
org.apache.spark.rdd.ShuffledRDD#computeBlockStoreShuffleReader#read- 预聚合 如果有必要
- 排序 如果有必要
写数据Writer
| Handle | Writer | 判断条件 |
|---|---|---|
| BypassMergeSortShuffleHandle | BypassMergeSortShuffleWriter | 1.不能有combine 2. 分区数不超过spark.shuffle.sort.bypassMergeThreshold(默认200) |
| SerializedShuffleHandle | UnsafeShuffleWriter | 1.序列化支持重定位(kryo支持,java不支持)2.不能有combine 3.分区数不能超过16777215+1 |
| BaseShuffleHandle | BaseShuffleHandle | 默认 |
BypassMergeSortShuffleWriter会根据RDD的分区数打开此数量的文件,然后通过rdd的迭代器,迭代出每一条数据,对这些record的分区号进行计算,到当前这条数据写入的分区号,然后写入到该分区对应的文件中。最后数据迭代完毕,会生成许多分区记录文件,之后将所有分区的数据会合并为同一个文件。此外还会生成一个索引文件,是为了索引到每个分区的起始地址,可以随机访问某个partition的所有数据。但是需要注意的是,这种方式不宜有太多分区,因为过程中会并发打开所有分区对应的临时文件,会对文件系统造成很大的压力。
UnsafeShuffleWriter 在内部维护了一块内存,这里的内存分为两部分。一部分是以Page(默认4KB)的形式存在的,存储是真正的记录。另一部分是一个存储数据指针的LongArray数组。这些数据都是被序列化存储的,其中指针是采用了8个字节来代表一条数据,8个字节的定义的数据结构具体存储的信息为24 bit partition number[27 bit offset in page] ,其中存储了这条数据的partition和真实记录数据的指针。数据记录被传入,先进行序列化,写入到内存页Page中,同时对该数据产生一条指针存储到LongArray数组中,做排序操作,排序操作使用的算法是默认是 RadixSort。在每次排序比较的时候,只需要线性的查找指针区域的数据,不用根据指针去找真实的记录数据做比较,同时序列化器支持对二进制的数据进行排序比较,不会对数据进行反序列化操作,这样避免了反序列化和随机读取带来的开销,因为不会序列化成对象,可以减少内存的消耗和GC的开销。UnsafeShuffleWriter中内存管理(申请、释放)工作,由ShuffleExternalSorter来完成。ShuffleExternalSorter还有一个作用就是当内存中数据太多的时候,会先spill到磁盘,防止内存溢出。之后,如果一个Page内存满了,就会申请内存,如果申请不到内存,就 spill到文件中。在spill时,会根据指针的顺序溢写,这样就保证了每次溢写的文件都是根据Partition来进行排序的。一个文件里不同的partiton的数据用fileSegment来表示,对应的信息存在 SpillInfo 数据结构中。最后的merge阶段会根据分区号去每个溢写文件中去拉取对应分区的数据,然后写入一个输出文件,最终合并成一个依据分区号全局有序的大文件。此外还会将每个partition的offset写入index文件方便reduce端拉取数据。
SortShuffleWriter 使用 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 在内存中进行排序, 排序的Key是(partitionId, hash(key)) 这样一个元组。如果超过内存阈值,spill 到一个文件中,这个文件中元素也是有序的,首先是按照 partitionId的排序,如果 partitionId 相同, 再根据 hash(key)进行比较排序。如果需要输出全局有序的文件的时候,就需要对之前所有的输出文件和当前内存中的数据结构中的数据进行mergeSort,进行全局排序。SortShuffleWriter 中使用 ExternalSorter 来对内存中的数据进行排序,ExternalSorter内部维护了两个集合PartitionedAppendOnlyMap、PartitionedPairBuffer
读数据fetch
- 同一个Executor会生成多个Task,单个Executor里的Task运行可以直接获取本地文件,不需要通过网络
- 同一台机器多个Executor,在这种情况下,不同的Executor获取相同机器下的其他的Executor的文件,需要通过网络
- 获取非本Executor的文件,在Spark里会生成一个FetchRequest,为了避免单个Executor的MapId过多发送多个FetchRequest请求,会合并同一个Executor的多个请求
Spark cache persist checkPoint localCheckpoint
cache和persist区别
cache是persist的特殊情况,等同于 persist(StorageLevel.MEMORY_ONLY)

checkPoint和persist区别
persist不会斩断rdd的血缘,当数据丢失的时候,可以重新计算,checkPoint会斩断血缘,但是可以将数据保存至hdfs,有多副本容错
一般在checkPoint前会对数据进行persist,因为等计算完成后会单独启动一个job去完成checkPoint,不然会计算两次
persist由Driver上blockManager管理,当程序结束时cache到磁盘上的数据也会被清空,checkPoint在程序结束以后也不会删除数据
checkPoint和localCheckPoint区别
checkPoint和localCheckPoint都可以斩断血缘,localCheckPoint适用于单纯想斩断血缘关系的情景,例如迭代计算
checkPoint可以将数据存储在可靠的分布式存储系统,localCheckPoint存储在本地文件,一旦节点失败,数据会丢失。但是性能可能会优于checkPoint
localCheckPoint等同于persist+斩断血缘,所以调用时是对数据做一个需要cache的标记,而不再立即求出它的值
persist大致实现原理
调用persist方法,标记rdd需要缓存
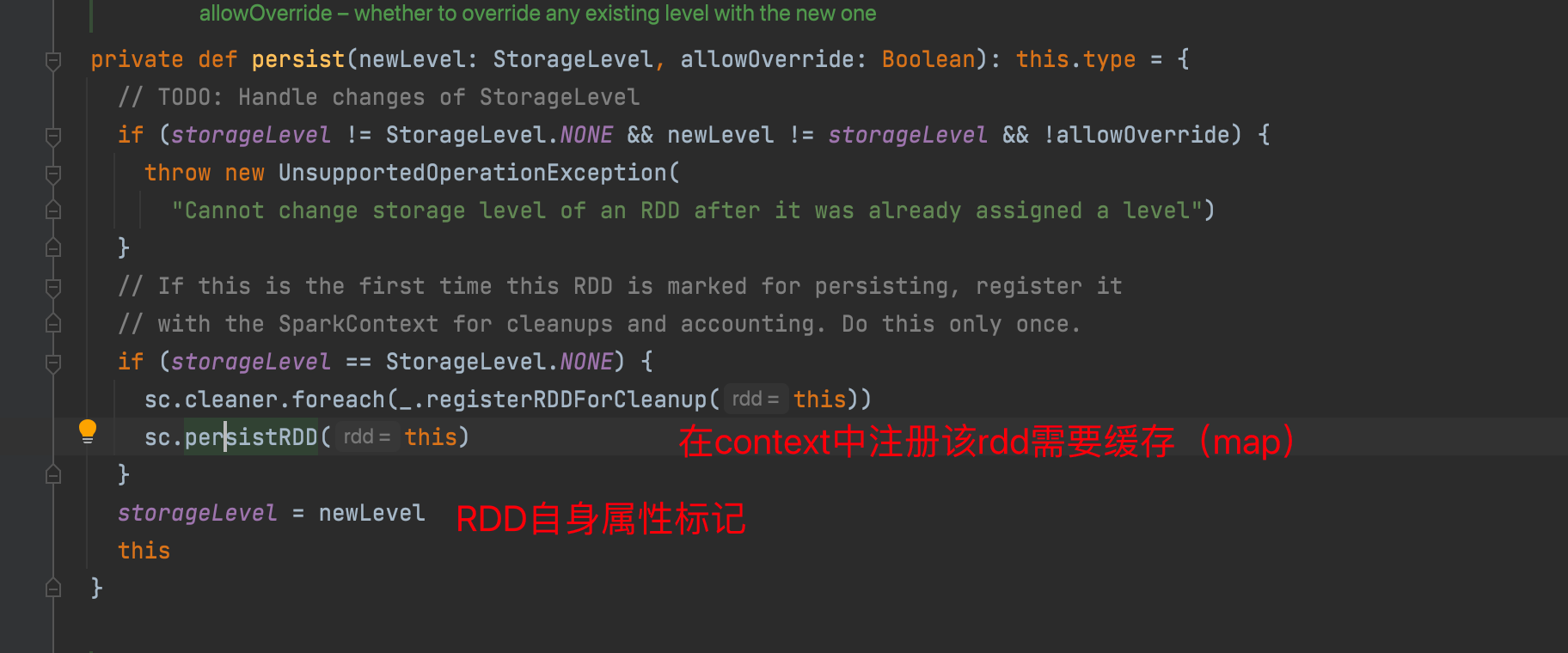
rdd读取数据时 最终会调用到 RDD#iterator

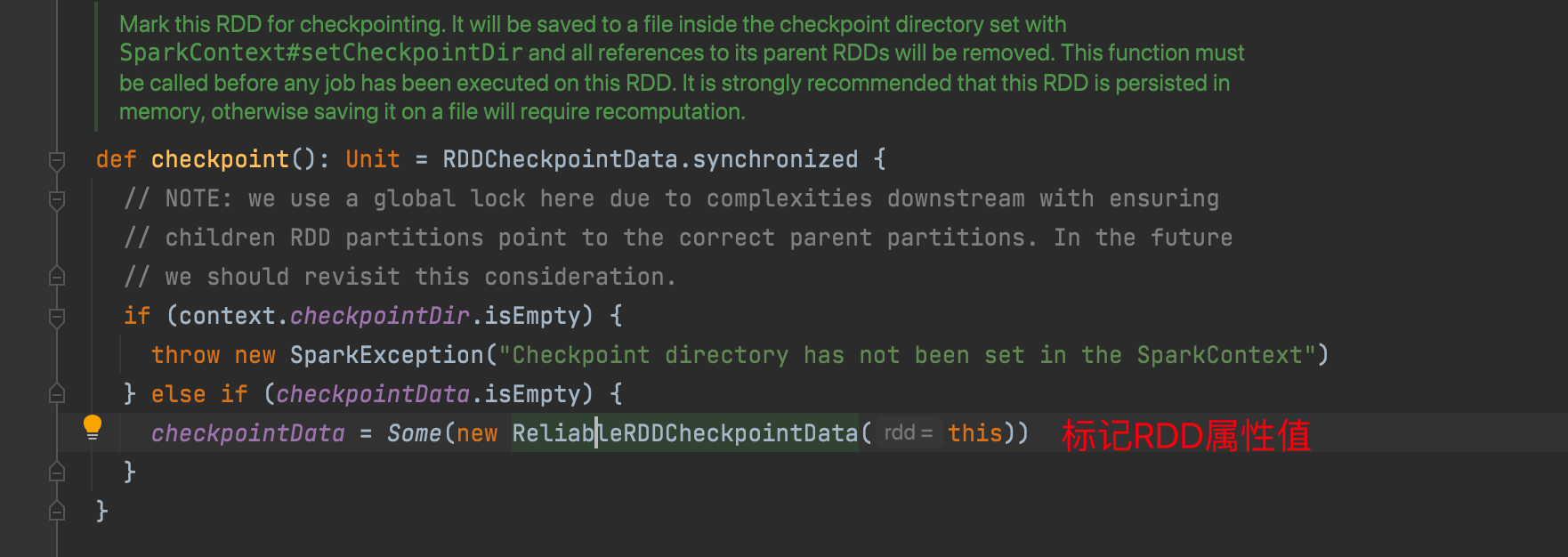
checkPoint大致原理
调用checkPoint方法,判断是否设置checkPoint的目标路径,标记需要checkPoint
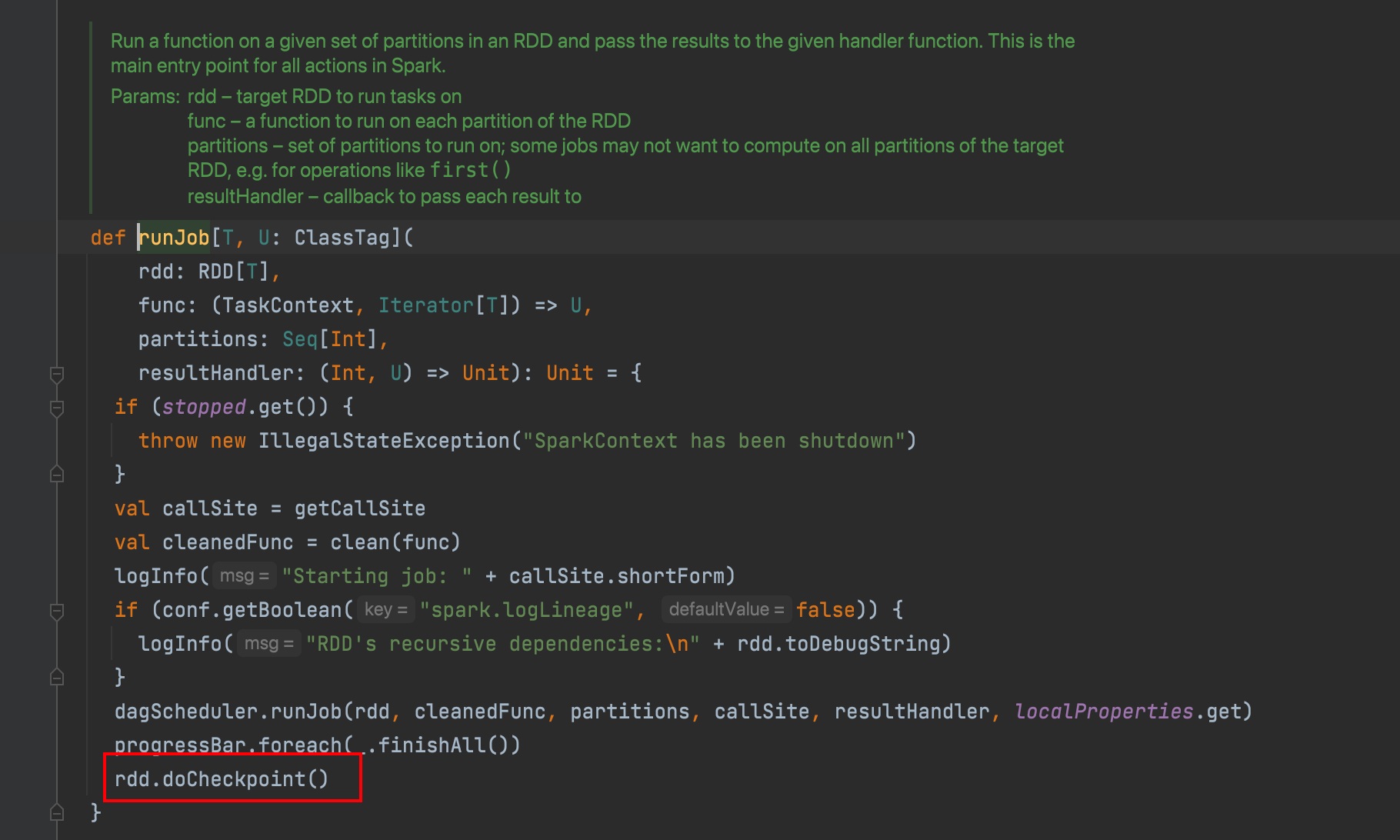
执行行动算子,会调用runJob,在runJob最后会执行doCheckPoint
默认只对最后一个标记的rdd执行checkPoint
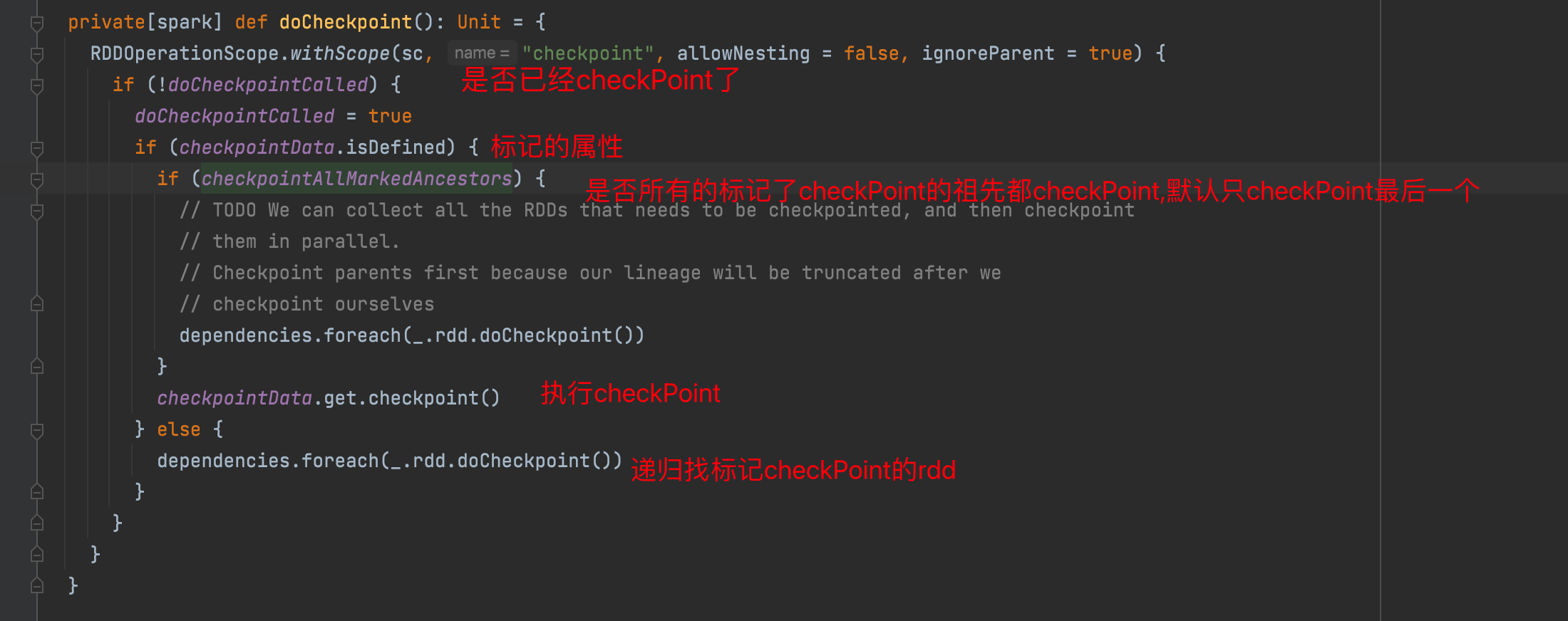
执行checkPoint
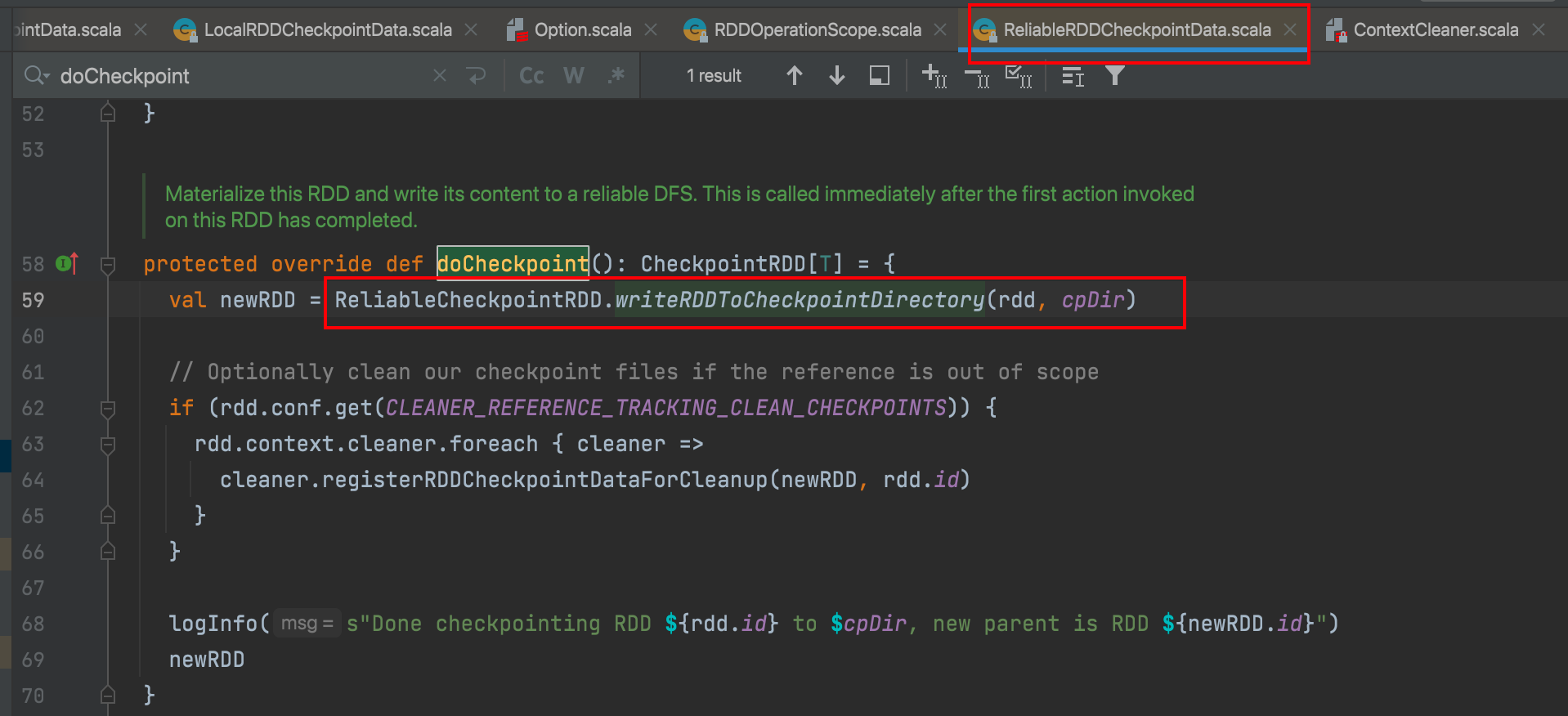
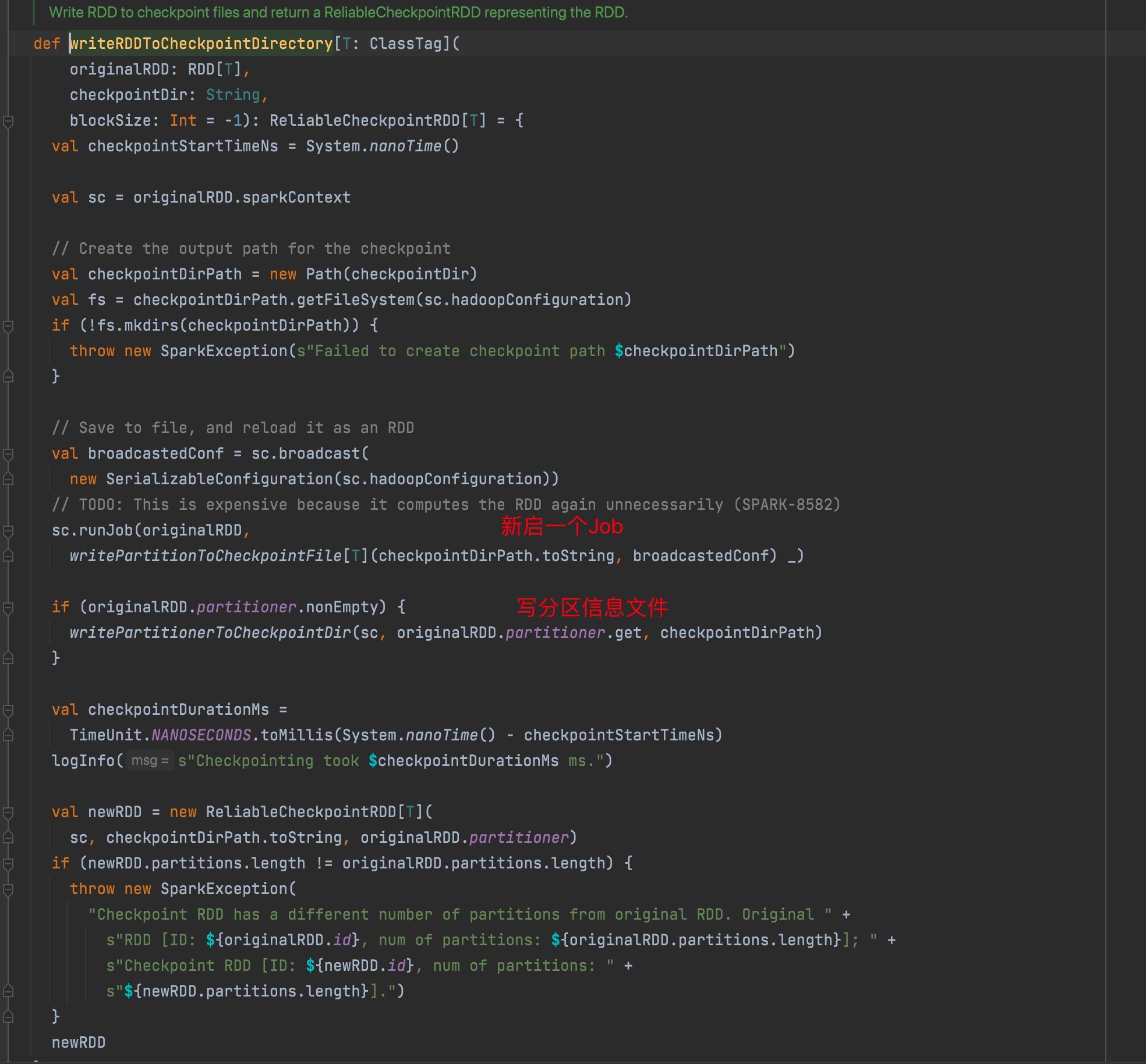
Spark内存管理
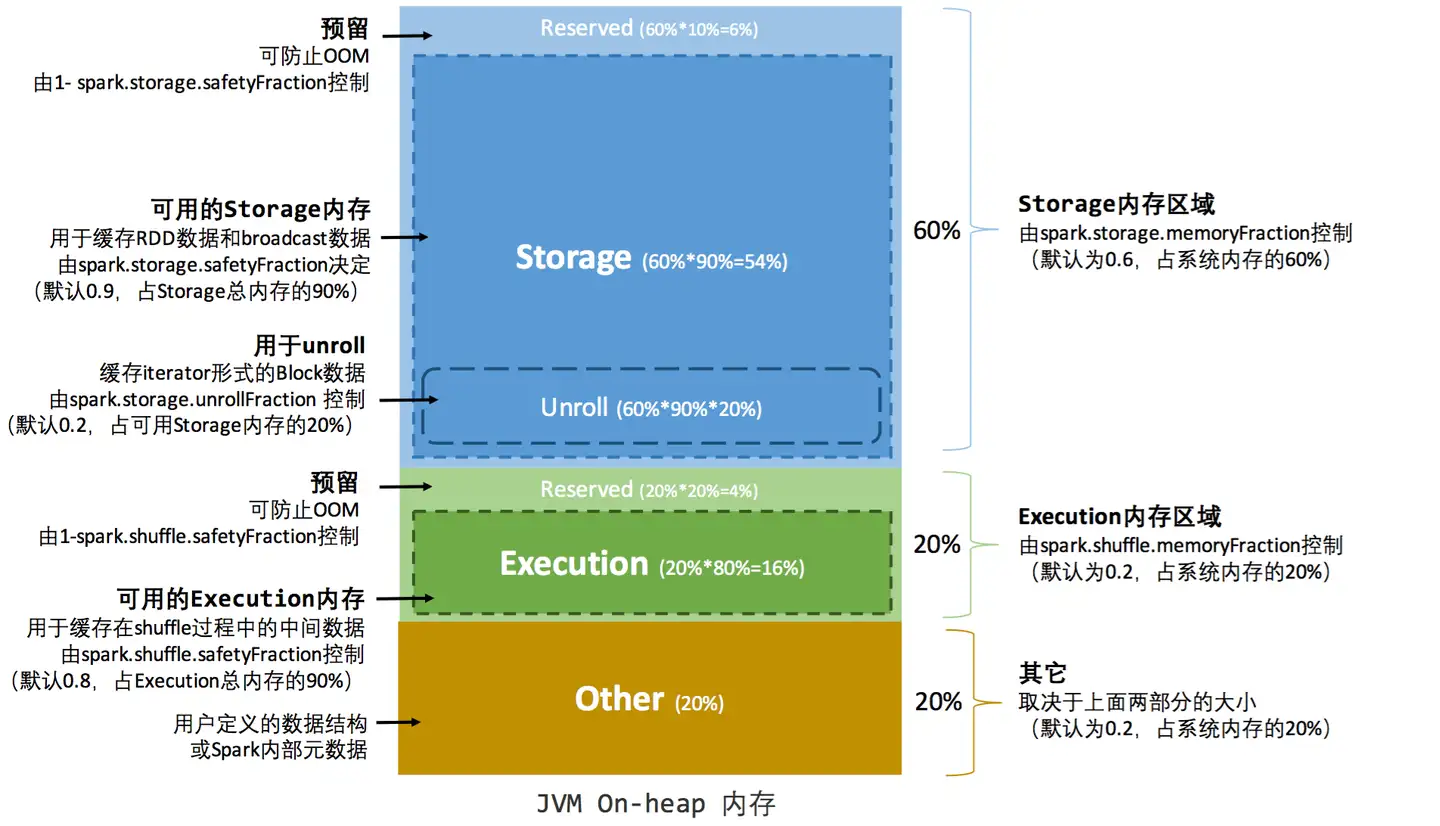
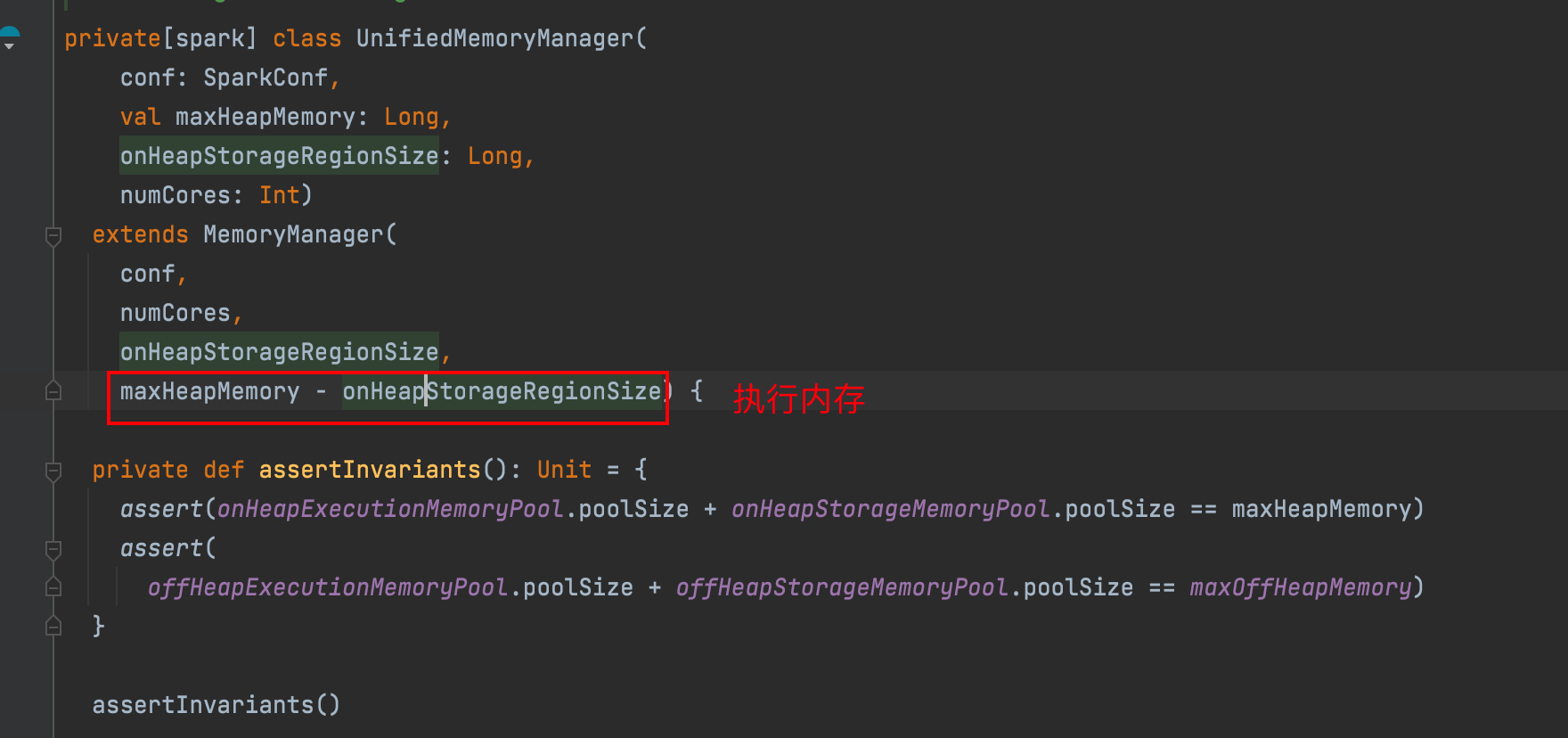
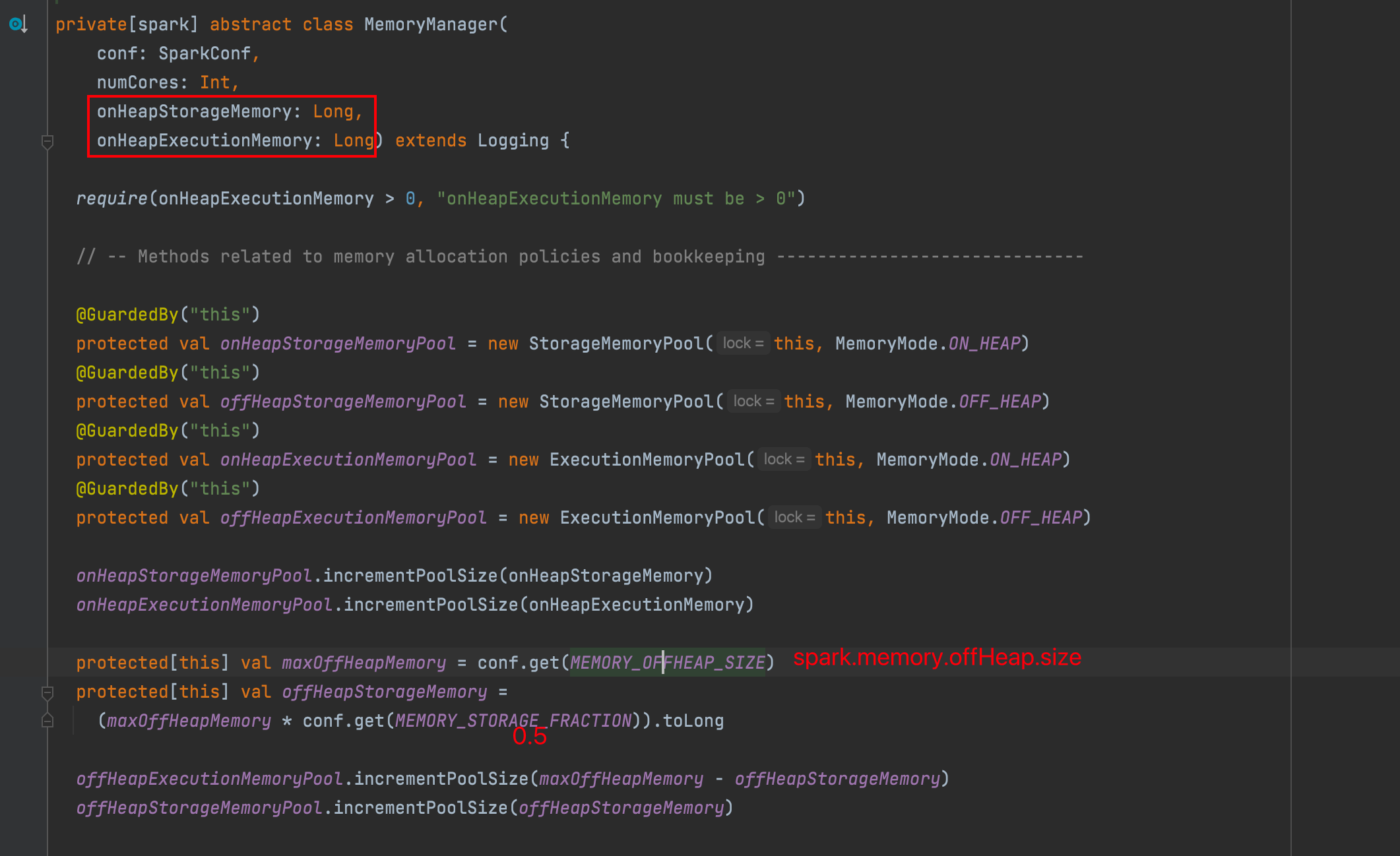
静态内存管理
在 Spark 最初采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置
统一内存管理
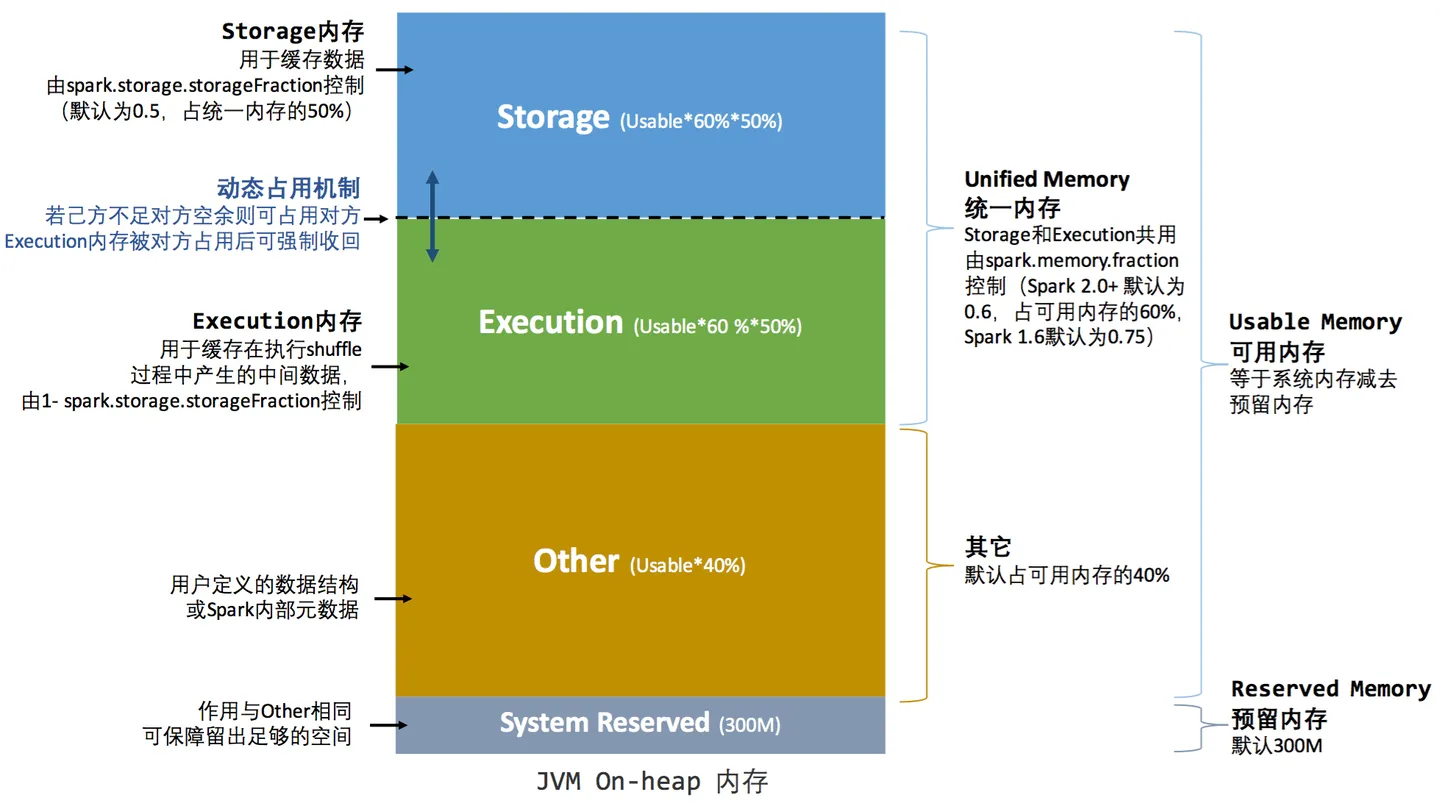
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域
堆内:
堆外:
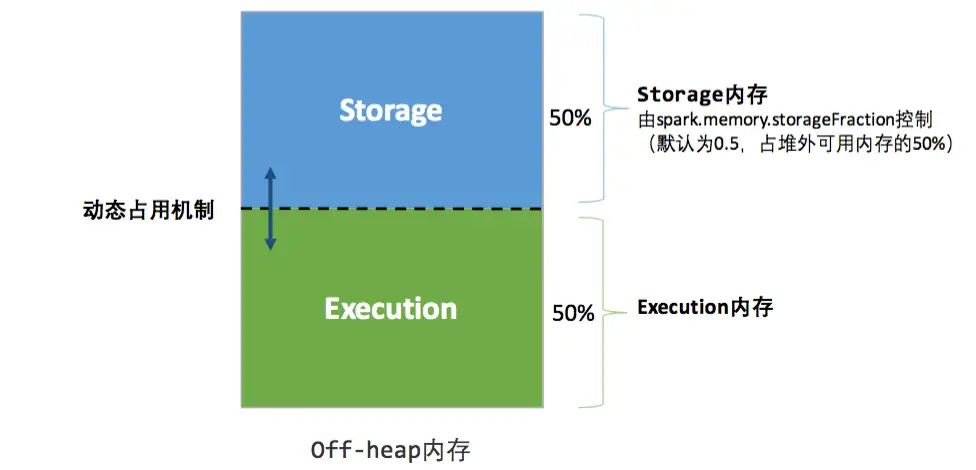
动态占用机制:
- 设定基本的存储内存和执行内存区域(
spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间的范围 - 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间
- 存储内存的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂
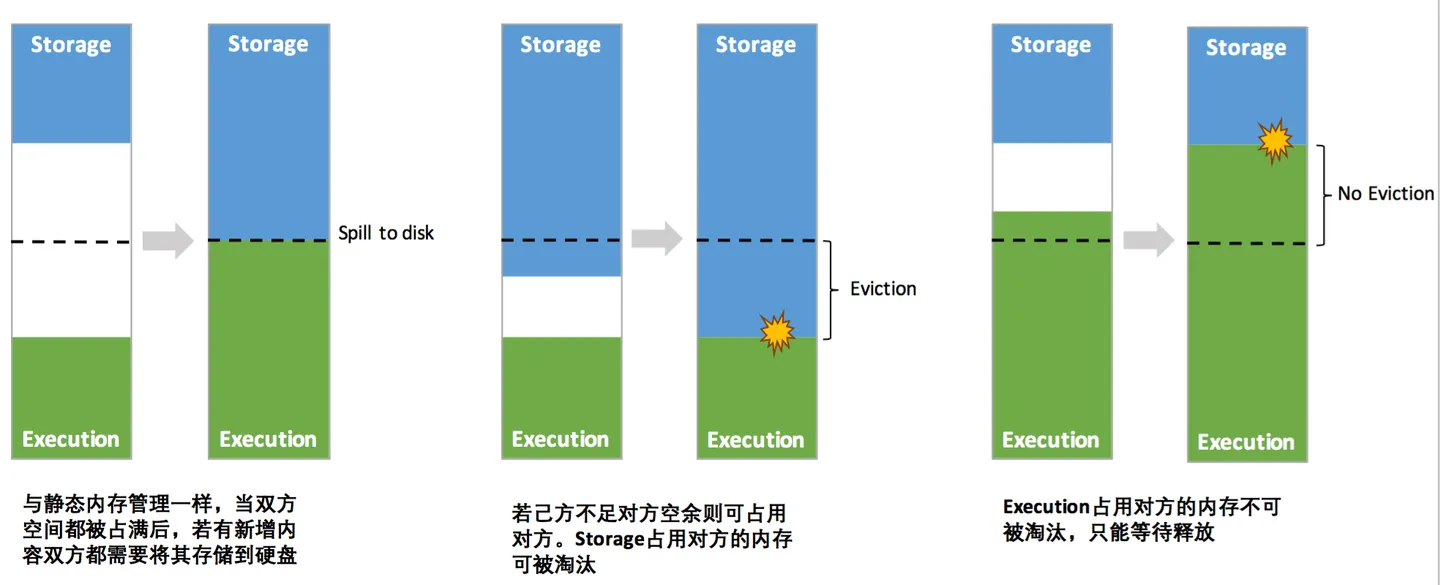
大致原理:
SparkEnv初始化统一内存管理器
Spark RangePartitioner & 水塘抽样
水塘抽样:
水塘抽样的目标是从一个很大的或未知大小的数据集中随机选取k个样本。 时间复杂度 O(n)
- 首先,将数据流的前k个元素保留在“水塘”(即一个大小为k的数组)中。
- 对于第i个元素(i > k),以k/i的概率选择这个元素替换水塘中的任一元素,这个过程一直持续到数据流的末尾。
public static int[] reservoirSampling(int[] stream, int k) {
// 初始化水塘
int[] reservoir = new int[k];
// 将数据流中的前 k 个元素放入水塘
for (int i = 0; i < k; i++) {
reservoir[i] = stream[i];
}
// 处理第 k+1 个及以后的元素
Random random = new Random();
for (int i = k; i < stream.length; i++) {
int j = random.nextInt(i + 1); // 生成一个介于 0 到 i 之间的随机数
if (j < k) {
reservoir[j] = stream[i];
}
}
return reservoir;
}
public static void main(String[] args) {
// 示例数据流
int[] stream = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int k = 3; // 抽取 3 个样本
// 执行水塘抽样
int[] samples = reservoirSampling(stream, k);
// 打印抽样结果
System.out.println("抽样结果:" + Arrays.toString(samples));
}RangePartitioner
计算总体抽样大小sampleSize ,至少每个分区抽取20个数据或者最多1e6的样本的数据量
根据sampleSize和分区数量计算每个分区的数据抽样样本数量最大值sampleSizePrePartition
对每个分区进行水塘抽样(新启一个Job)
对于数据量较大的分区(fraction 抽样因子小) ,按照相同的抽样因子重新抽样(新启一个Job)
根据样本数据 计算边界数组
RDD
弹性分布式数据集 Resilient Distributed Dataset
弹性:
- 容错的弹性:通过血统信息(Lineage)记录RDD的生成过程,RDD能够在节点故障时重算丢失的数据。
- 存储的弹性:内存与磁盘的自动切换
分布式:
- RDD的数据存储在多个节点上,能够利用集群的分布式计算能力
不可变:
- RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
5个重要属性
- A list of partitions
多个分区. 分区可以看成是数据集的基本组成单位, 对于 RDD 来说, 每个分区都会被一个计算任务处理, 并决定了并行计算的粒度
- A function for computing each split
Spark 中 RDD 的计算是以分片为单位的, 每个 RDD 都会实现 compute 函数以达到这个目的.
- A list of dependencies on other RDDs
与其他 RDD 之间的依赖关系
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
对存储键值对的 RDD, 还有一个可选的分区器.只有对于 key-value的 RDD, 才会有 Partitioner
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
存储每个切片优先(preferred location)位置的列表. 比如对于一个 HDFS 文件来说, 这个列表保存的就是每个 Partition 所在文件块的位置. 按照“移动数据不如移动计算”的理念, Spark 在进行任务调度的时候, 会尽可能地将计算任务分配到其所要处理数据块的存储位置.
RDD算子
- 单value
- map
val rdd2 = rdd1.map(_ * 2) - mapPartitions
val rdd2 = rdd.mapPartitions(it=>it.map(_*2))入参数迭代器,包含一个分区的数据 - mapPartitionsWithIndex
val rdd2 = rdd.mapPartitionsWithIndex((index, it) => it.map((index, _)))index是分区序号 - flatMap
val rdd2 = rdd.flatMap(x=>List(x,x+1,x+2))出参是集合 - filter
val rdd2 = rdd.filter(_>2) - groupBy
val rdd2: RDD[(Int, Iterable[Int])] = rdd.groupBy(_%2) - sample
sample(withReplacement, fraction, seed) - distinct
- coalesce
rdd1.coalesce(2)缩减分区数到指定的数量 默认不shuffle ,第二个参数可以控制是否shuffle,第三个参数为分区器 - repartition repartition实际上是调用的coalesce,进行shuffle
- sortBy
rdd1.sortBy(x => x).collect - pipe 针对每个分区,把 RDD 中的每个数据通过管道传递给shell命令或脚本
- map
- 双value
- union
val rdd3 = rdd.union(rdd2) - subtract
val rdd3 = rdd.subtract(rdd2)从原 RDD 中减去 原 RDD 和 otherDataset 中的共同的部分 - intersection
val rdd3 = rdd.intersection(rdd2)交集 - cartesian
val rdd3 = rdd.cartesian(rdd2)笛卡尔积 - zip
val rdd3 = rdd.zip(rdd2)两个 RDD 的元素的数量和分区数都必须相同 - zipPartitions
val rdd3 = rdd.zipPartitions(rdd2)((it1,it2)=>{xxx})分区与分区之间拉,只要求分区数相同即可 - zipWithIndex
val rdd3: RDD[(Int, Long)] = rdd.zipWithIndex() - join
rdd1.join(rdd2)(K,V) & (K,W) —> (K,(V,W)) - leftOuterJoin
- rightOuterJoin
- fullOuterJoin
- union
- key-value
- groupByKey
val rdd3 = rdd2.groupByKey() - foldByKey
val rdd3 = rdd2.foldByKey(0)(_+_) - aggregateByKey
rdd.aggregateByKey(Int.MinValue)(math.max(_, _), _ +_) - combineByKey
val rdd2 = rdd.combineByKey(v=>v, (c:Int,v)=>c+v, (c1:Int,c2:Int)=>c1+c2 ) - partitionBy
rdd2.partitionBy(new HashPartitioner(2)) - sortByKey
val rdd2 = rdd.sortByKey(true)RangePartitioner - mapValues
- reduceByKey
val rdd3 = rdd2.reduceByKey(_+_) - …….
- groupByKey
- action
- collect 将分区间的的所有数据拉到driver端
- count
- take(n)
- first
- takeOrdered
- countByKey
- reduce
- fold
- aggregate
- foreach 在executer上执行
- foreachPartition
- savexxxx
reduceByKey,foldByKey,aggregateByKey,combineByKey
- reduceByKey
- 分区内聚合和分区间聚合逻辑相同
- foldByKey
- 分区内和分区间聚合逻辑相同,但是有初始值
- aggregateByKey
- 有初始值,分区内和分区间逻辑可以不同
- combineByKey
- 可以根据key的第一个value计算初始值,分区内和分区间逻辑可以不同
- groupByKey
- value是迭代器
5个函数底层都调用了combineByKeyWithClassTag
Spark rdd join
当两个rdd分区数一致时是oneToOneDependency
当两个rdd分区数不一致时是ShuffleDependency
SparkDemo
object Main {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val context = new SparkContext(conf)
val wordData: RDD[String] = context.textFile("data")
val words: RDD[String] = wordData.flatMap(_.split(" "))
val wordCnt: Array[(String, Int)] = words.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect()
wordCnt.foreach(println)
}
}SparkSQLDemo
object Main3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SQL")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val frame: DataFrame = session.read.json("jsonFile/1.json")
frame.createOrReplaceTempView("tmp_table")
session.sql("select * from tmp_table").show()
}
}SparkSQL 特点
Integrated:Seamlessly mix SQL queries with Spark programs. (整合了sql查询和spark编程)
Uniform data access:Connect to any data source the same way. (不同的数据源 统一的接入方式)
Hive integration:Run SQL or HiveQL queries on existing warehouses. (集成hive)
Standard connectivity:Connect through JDBC or ODBC. (标准连接方式)
RDD & DataSet & DataFrame
DataFrame除了数据以外,还记录数据的结构信息,即schema,type DataFrame = Dataset[Row]
DataSet具有RDD和DataFrame的优点,并且类型安全(强类型),能在编译是检查到错误(DataFrame只是知道字段,但是不知道字段的类型)
DataFrame存储在off-heap(堆外内存)中,由操作系统直接管理(RDD是JVM管理),可以将数据直接序列化为二进制存入off-heap中。操作数据也是直接操作off-heap。效率高内存占用低
优化的执行计划,通过Spark catalyst optimiser进行优化
SparkSession
SparkSession 是spark新的入口点,包含了SparkContext ,HiveContext(继承SQLContext),将Spark中所有的上下文环境统一
SparkJoin
sparksql中,join有六种实现方式:
- SortMergeJoinExec
- 仅支持等值 Join,并且要求参与 Join 的 Keys 可排序
- ShuffledHashJoinExec
- 等值join
- spark.sql.join.preferSortMergeJoin=false
- 小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions;而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是 a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes
- 进行 ShuffledHashJoin 的时候 Spark 构建了build hash map,所以如果小表分区后的数据还比较大,可能会参数 OOM 的问题
- BroadcastHashJoinExec
- 小表的数据必须很小
- 等值join ,不支持full outer
- BroadcastNestedLoopJoinExec
- Broadcast nested loop join 支持等值和不等值 Join,支持所有的 Join 类型
- right outer join 是会广播左表;left outer, left semi, left anti 或者 existence join 时会广播右表;inner join 的时候两张表都会广播。
- CartesianProductExec
- 必须是 inner Join,其支持等值和不等值 Join
等值join 选择策略
1.hint指定
2.根据 Join 的适用条件按照 Broadcast Hash Join -> Shuffle Hash Join -> Sort Merge Join ->Cartesian Product Join -> Broadcast Nested Loop Join 顺序选择 Join 策略
非等值join 选择策略
1.hint
2.Broadcast Nested Loop Join ->Cartesian Product Join -> Broadcast Nested Loop Join 顺序
join 不一定发生shuffle
hash shuffle 不等同于 hash join ,hash shuffle 数据分发策略 ,hash join 是数据关联策略 。虽然hash shuffle被弃用了但是和hash join 没有关系
Spark AQE
AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化
3大特性:
自动分区合并:在 Shuffle 过后,Reduce Task 数据分布参差不齐,AQE 将自动合并过小的数据分区。分区合并是相邻的分区合并,保证顺序读,提高IO性能。
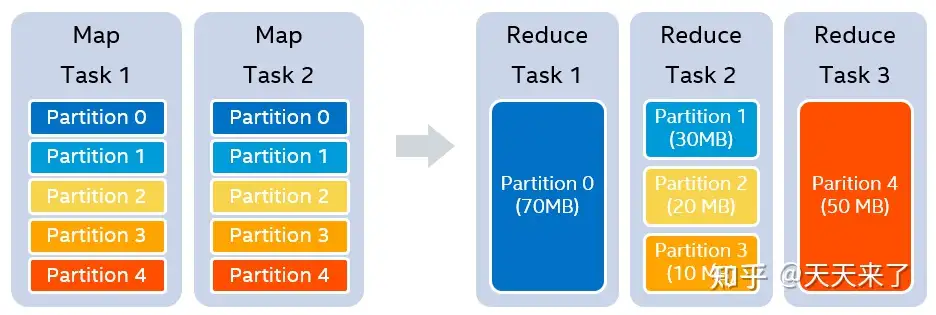
Join 策略调整:如果某张表在过滤之后,尺寸小于广播变量阈值,这张表参与的数据关联就会从 Shuffle Sort Merge Join 降级(Demote)为执行效率更高的 Broadcast Hash Join。
有两个优化规则,一个逻辑规则和一个物理策略分别是:DemoteBroadcastHashJoin 和 OptimizeLocalShuffleReader
DemoteBroadcastHashJoin 判断中间文件是否满足广播条件,降级join策略
OptimizeLocalShuffleReader 策略可以省去 Shuffle 常规步骤中的网络分发,Reduce Task 可以就地读取本地节点(Local)的中间文件,完成与广播小表的关联操作 (AQE 依赖的统计信息来自于 Shuffle Map 阶段生成的中间文件,即使已经将Shuffle Sort Merge Join 就会降级为 Broadcast Hash Join,但join两表都已经按照 Sort Merge Join 的方式走了一半)
自动倾斜处理:结合配置项,AQE 自动拆分 Reduce 阶段过大的数据分区,降低单个 Reduce Task 的工作负载。
在AQE中,执行子 QueryStages 后,收集每个分区的 shuffle 数据大小和记录数。如果一个分区的数据量或记录数比中位数大N倍,也比预先配置的值大,则判断为倾斜分区
利用 OptimizeSkewedJoin 策略,AQE 会把大分区拆成多个小分区
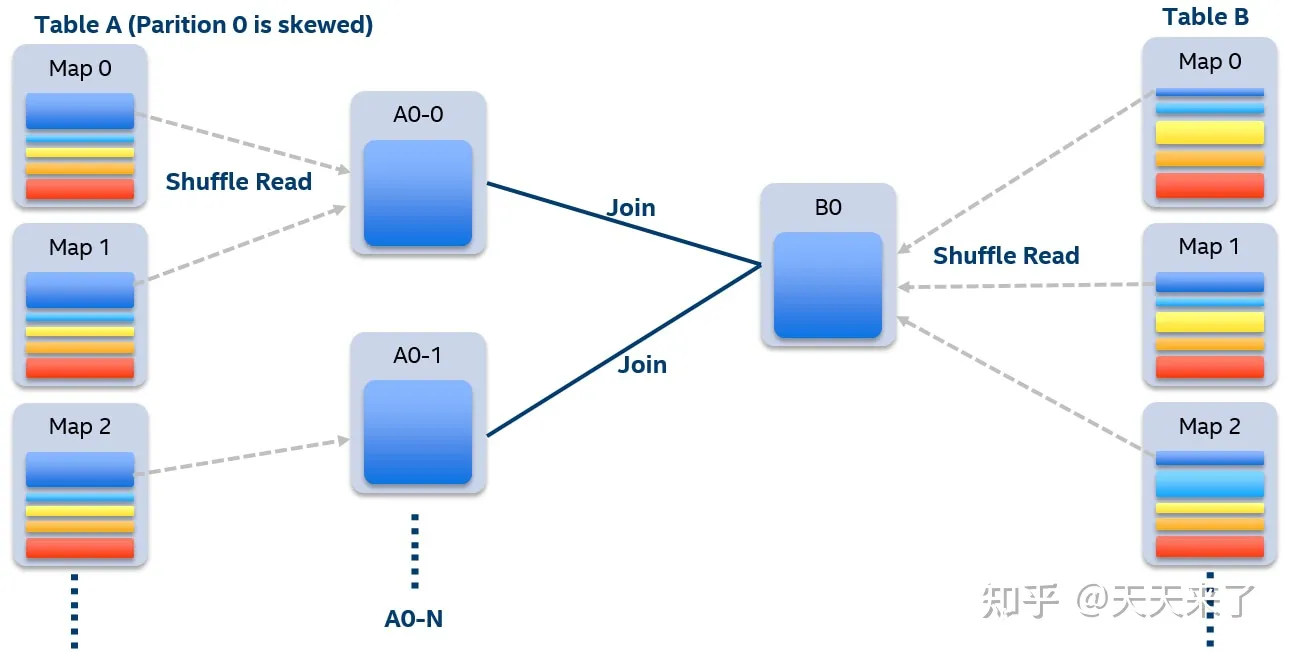
假设表 A 和表 B 执行内连接并且表 A 中的分区 0 是倾斜的。对于正常执行,表 A 和 B 的分区 0 都被洗牌到单个 reducer 进行处理。由于这个 reducer 需要通过网络和进程获取大量数据,因此它可能是延长整个阶段时间的最慢任务。
如上图所示,N个task用于处理表A的偏斜分区0,每个task只读取表A的少数mapper的shuffle输出,并与表B的分区0进行join,将这N个task的结果合并得到最终的join结果. 为了实现这一点,我们更新了 shuffle read API 以允许仅从几个映射器而不是全部读取分区。
在处理过程中,我们可以看到表 B 的分区 0 将被多次读取。尽管引入了开销,但性能改进仍然很显着。
不过这种解决数据倾斜的方式针对的是Task级别的数据倾斜,主要是将同一个executor内的倾斜task进行拆分,而对于数据全集中在个别executor内的情况就无济于事了。
Spark DPP
DPP(Dynamic Partition Pruning,动态分区剪裁)指的是在大表Join小表的场景中,可以充分利用过滤之后的小表,在运行时动态的来大幅削减大表的数据扫描量,从整体上提升关联计算的执行性能。
Spark SQL 对分区表做扫描的时候,是完全可以跳过(剪掉)不满足谓词条件的分区目录,这就是分区剪裁。
SELECT t1.id, t2.part_column FROM table1 t1
JOIN table2 t2 ON t1.part_column = t2.part_column
WHERE t2.id < 5没有开启DPP的情况下,执行上述语句需要扫描完整的t1表,这是因为t2.id < 5只是对小表进行了过滤
在Join关系 t1.part_column = t2.part_column的作用下,过滤效果会通过 小表t2.part_column 字段传导到大表的 t1.part_column字段。这样一来,传导后的t1.part_column值,就是大表 part_column 全集中的一个子集。把满足条件的 t1.part_column作为过滤条件,应用到大表的数据源,就可以做到减少数据扫描量,提升 I/O 效率。
spark.sql.optimizer.dynamicPartitionPruning.enabled=true; # 其默认值就是true, spark3 默认是开启DPP的
spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly=true; # 默认是true,这时只会在动态修剪过滤器中重用BroadcastExchange时,才会应用 DPP,如果设置为false可以在非Broadcast场景应用DPP。
spark.sql.optimizer.dynamicPartitionPruning.useStats=true; # 如果为true,则将使用不同计数统计信息来计算动态分区修剪后分区表的数据大小,以评估在广播重用不适用的情况下是否值得添加额外的子查询作为修剪过滤器。
spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio=0.5; # 当统计信息不可用或配置为不使用时,此配置将用作回退过滤器比率,用于计算动态分区修剪后分区表的数据大小,以评估在广播重用不适用的情况下是否值得添加额外的子查询作为修剪过滤器- 大表必须是分区表,并且分区字段必须包含 Join Key;
- 只支持等值 Joins,不支持大于、小于这种不等值关联关系;
- 小表存在过滤谓词;
- 执行动态分区过滤必须是收益的,简单来说大表在乘以过滤比后其大小仍要大于小表。
分区过滤的实现是在逻辑计划的Optimizer阶段,通过注入PartitionPruning规则,将满足条件的待剪裁侧plan中插入自定义了被包装为正则In表达式的DynamicRunning表达式。在物理计划的preparations阶段,调用PlanDynamicPruningFilters规则,根据是否可以重用broadcast,和是否只支持broadcast来区分执行实现,具体为:
- 如果当前开启了exchangeReuseEnabled,同时Plan中存在BroadcastHashJoinExec,则会重用当前的BroadcastExchangeExec,并将其封装为一个InSubqueryExec,在包装为DynamicPruningExpression表达式。
- 如果onlyInBroadcast为false, 表明要么是reuseBroadcastOnly设为false(即非broadcast exchange时也可使用), 要么是有收益。则先按照需要过滤的key做一次聚合, 然后将其封装为一个InSubqueryExec,再包装为DynamicPruningExpression表达式。
- 否则,不会执行Query, 执行回退
Spark RuntimeFilter
与dpp类似,是dpp的补充,不强制要求是分区字段
两种策略: BloomFilter和Semi-Join
BloomFilter有假阳性的问题,另外如果数据量比较大其结果可能会出现判断错误的情况
bloomFilter需要小表满足其sizeInBytes小于阈值(默认10M)
semi-join Filter需要满足小表join keys聚合后可以广播
Spark的runtimeFilter, 在Plan的转换中会存在冗余计算的问题,小表存在两次扫描和过滤的问题
Spark ESS PBS RSS
ESS external shuffle service
spark提供了external shuffle service这个接口,常见的就是spark on yarn中的,YarnShuffleService
在yarn的nodemanager中会常驻一个externalShuffleService服务进程来为所有的executor服务
- 即使 Spark Executor 正在经历 GC 停顿,Spark ESS 也可以为 Shuffle 块提供服
- 即使产生它们的 Spark Executor 挂了,Shuffle 块也能提供服务
- 可以释放闲置的 Spark Executor 来节省集群的计算资源
PBS Push-based shuffle
在Spark3.2中引入了领英设计的一种新的shuffle方案(Magnet)
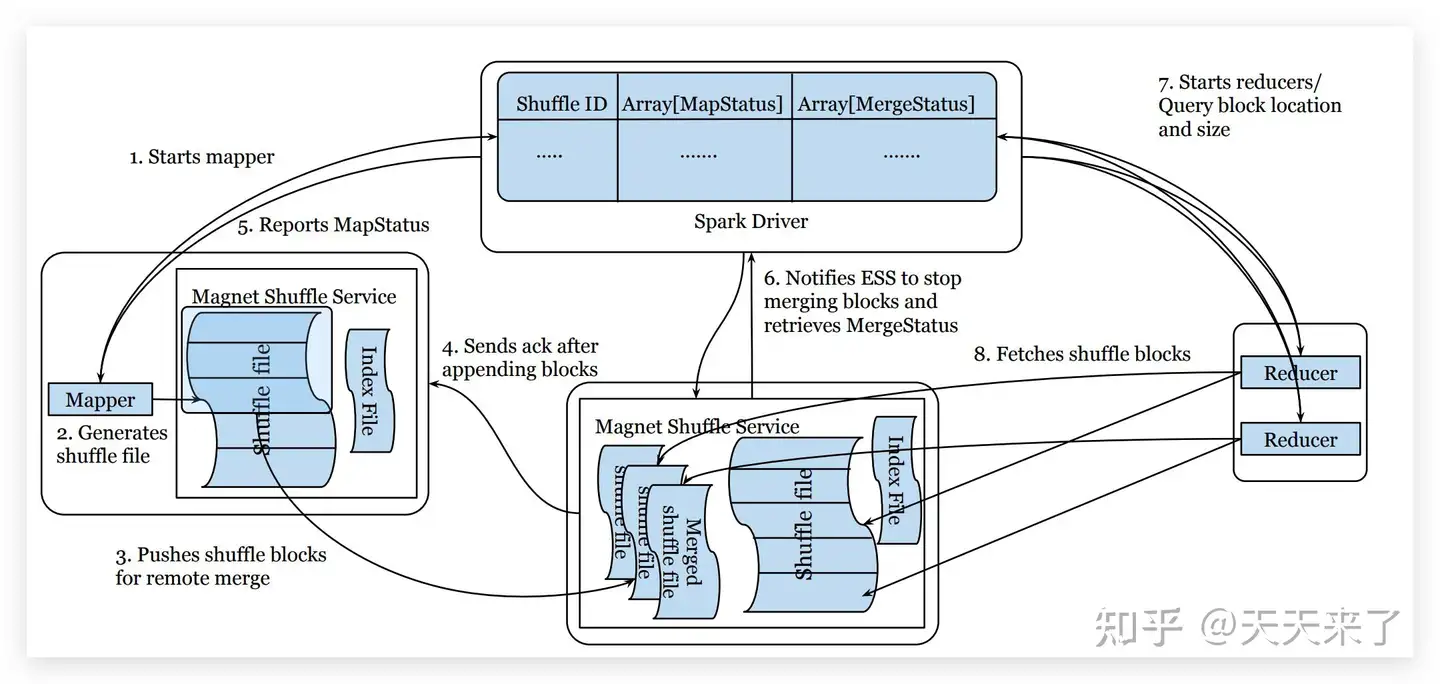
ESS问题:
- Spark ESS 每个 FETCH 请求只会读取一个 Shuffle 块,因此Shuffle 块的平均大小决定了每次盘读的平均数据量,如果存在大量小 Shuffle 块导致磁盘 I/O 低效
- Reduce 任务在建立与远程 Spark ESS 的连接时出现失败的情况,它会立即失败整个的 Shuffle Reduce Stage
PBS特性
- Magnet采用 Push-Merge Shuffle 机制,其中 Mapper 生成的 Shuffle 数据被推送到远程的 Magnet Shuffle Service,从而实现每个 shuffle 分区都能被合并。这允许Magnet将小的 Shuffle 块的随机读取转化成 MB 大小块的顺序读取。此外,此推送操作与 Mapper 分离,这样的话,如果操作失败,也不会增加 Map Task 的运行时间或者导致 Map Task 失败。
- Magnet 通过在顶层构建的方式集成了 Spark 原生的 shuffle。这使得Magnet可以部署在具有相同位置的计算和存储节点的 on-prem 集群中与disaggrecated存储层的cloud-based的集群中。在前一种情况下,随着每次 Reduce Task 的大部分都合并在一个位置,Magnet利用这种本地性来调度 Reduce Task 并实现更好的 Reducer 数据本地性。在后一种情况下,代替数据本地性,Magnet可以选择较少负载的远程 shuffle 服务,从而更好的优化了负载均衡。
RSS remote shuffle service
依赖于外部组件实现
Spark 投影和谓词下推
谓词下推是指将过滤条件(谓词)应用于查询的尽可能早的阶段,以减少需要处理的数据量。
具体而言,当Spark执行查询时,它会尝试将过滤条件应用于数据源本身,而不是将整个数据集加载到内存中后再进行筛选。这样可以避免对不符合条件的数据进行处理,节省了计算资源和时间。
投影下推是指将查询中不需要的列从数据源中过滤掉,只加载查询需要的列。通过减少所需的列数量,可以减少磁盘IO和网络传输的数据量,提高查询性能。(Project节点)
Spark广播原理
创建:
广播变量的创建发生在Driver端,当调用SparkContext#broadcast来创建广播变量时,会把该变量的数据切分成多个数据块,保存到driver端的BlockManger中,使用的存储级别是:MEMORY_AND_DISK_SER。
所以,广播变量的读取也是懒加载的,只有在Executor端需要获取广播变量时才会去获取。初始化时广播变量的数据只在Driver端存在。
读取:
首先从Executor本地的BlockManager中读取广播变量的数据,若存在就直接获取,并返回
从Driver端获取广播变量的状态和位置信息(由于所有的BlockManager slave端都会向Master端汇报数据块状态)
优先从本地目录(数据块就在本地),或者相同主机的其他Executor中读取广播变量数据块。若在本Executor和同主机其他Executor中都不存在,则只能从远端获取数据。从远端获取数据的原则是:先从同一个机架(rack)的主机的Executor端获取。若不能从其他Executor中获取广播变量,则会直接从Driver端获取。
只要有一个worker节点的Executor从Driver端获取到了广播变量的数据,则其他的Executor就不需要从Driver端获取了。
销毁:
从driver端发送一个RemoveBroadcast消息。在Executor上的BlockManager服务接收该消息,就会把广播变量从BlockManager中删除。
若removeFromDriver设置成True,还会从Driver删除该变量的数据。
Spark Accumulator
Accumulator是Spark中的一种分布式变量,用于在并行计算中进行累加操作。它是由MapReduce模型中的“全局计数器”概念演化而来的。
Accumulator提供了一个可写的分布式变量,可以在并行计算中进行累加操作。在Spark中,当一个任务对Accumulator进行累加操作时,这个操作会被序列化并发送到执行任务的节点上进行执行。然后,Spark会将所有节点上的结果合并起来,最终得到Accumulator的最终值。
Accumulator的使用场景包括但不限于:
- 在并行计算中进行全局计数或求和操作;
- 在迭代算法中进行迭代过程中的统计操作;
- 在分布式机器学习中进行模型参数的更新。
Spark Tungsten
提升Spark应用程序的内存和CPU利用率
Memory Management and Binary Processing: application显示的对内存进行高效的管理以消除JVM对象模型和垃圾回收的开销;
- 堆外内存,unsafe api。4字节的字符串在jvm需要48字节的空间来存储
Cache-aware computation:设计算法和数据结构以充分利用memory hierarchy
- 基于顺序扫描的特性,排序通常能获得一个不错的缓存命中率。 然而,排序一组指针的缓存命中率却很低,因为每个比较运算都需要对两个指针解引用,而这两个指针对应的却是内存中两个随机位置的数据。
- 如何提高排序中的缓存本地性?一个方法就是通过指针顺序地储存每个记录的sort key 。举个例子,如果sort key是一个64位的整型,那么我们需要在指针阵列中使用128位(64位指针,64位sort key)来储存每条记录。这个途径下,每个quicksort对比操作只需要线性的查找每对pointer-key,从而不会产生任何的随机扫描。
Code generation:使用code generation去充分利用最新的编译器和CPUs的性能
- Spark在SQL和DataFrame上引入了表达式求值的代码生成技术。表达式求值是在特定记录上计算表达式值的过程(比如”age > 10 and age < 20”),在运行时,Spark会动态生成字节码来计算这些表达式,而不是低效的解释执行每行记录。代码生成相比一行行的解释执行可以减少对基本数据类型的装箱操作,更重要的是,可以避免多态函数的调用 (JIT)
- 消除虚函数调度(多态)
- 将中间数据从内存移动到 CPU 寄存器
- 利用现代 CPU 功能循环展开和使用 SIMD。通过向量化技术,引擎将加快对复杂操作代码生成运行的速度。
Spark Rebalance and Repartition
SELECT /*+ REPARTITION(3) */ * FROM t;
SELECT /*+ REPARTITION(c) */ * FROM t;
SELECT /*+ REBALANCE */ * FROM t;
SELECT /*+ REBALANCE(c) */ * FROM t;Rebalance
在AQE阶段,根据spark.sql.adaptive.advisoryPartitionSizeInBytes进行分区的重新分区,防止数据倾斜。
Repartition
相对于Rebalance,该hint只是根据指定的固定的分区数据或者列进行分区,这个时候每个分区的大小并不能控制,只能说是平均分配或者说是按照列进行hash分区(这种情况存在文件大小不一的情况)
具体的分析,可以参考Rebalance的分析。
注意一点的是在SPARK-35650之后,如果是单纯的REPARTITION hint 也是可以达到Rebalace hint的效果
一般在reparition用到的地方都可以Rebalance来替换
Spark 数据倾斜
1.hive中预处理
hive中也会出现数据倾斜
2.过滤少数key
适用场景不多
3.提高shuffle并行度
没有根除问题,效果有限
4.两阶段聚合
仅适用于聚合类操作,使用范围窄
5.reduce join 转为map join
使用场景少
6.随机前缀
对数据倾斜的key每条数据随机打上1-n的前缀,然后另外一个rdd扩容n倍,每条数据都打上所有1-n前缀
Spark与MR区别
- spark把中间计算结果放内存,并且使用dag引擎划分阶段,mr的mapreduce中间数据需要落盘
- MR task运行在独立的进程,Spark每一个Task是一个线程,对于资源广播共享,资源重用很方便
Spark Shuffle 和MR Shuffle 异同
- 功能上看 差不多
- spark 可以不排序
- spark 合并文件然后加index索引
SparkStreaming
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(1))
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
val words: DStream[String] = lines.flatMap(_.split(" "))
val pairs: DStream[(String, Int)] = words.map(word => (word, 1))
val wordCounts: DStream[(String, Int)] = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminateDStream
离散流或DStream是 Spark Streaming 提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的处理后的数据流。在内部,DStream 由一系列连续的 RDD 表示,这是 Spark 对不可变分布式数据集的抽象
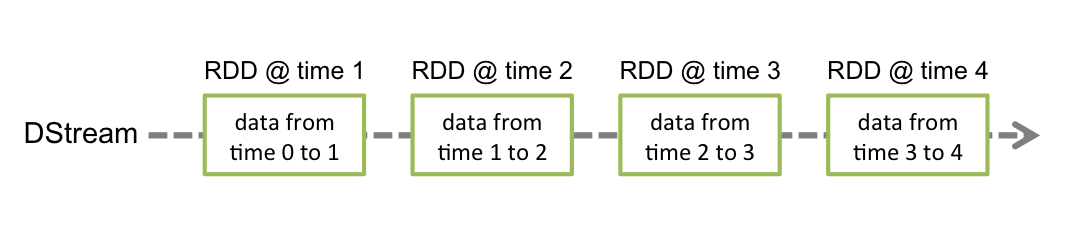
UpdateStateByKey 有状态操作
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)窗口操作
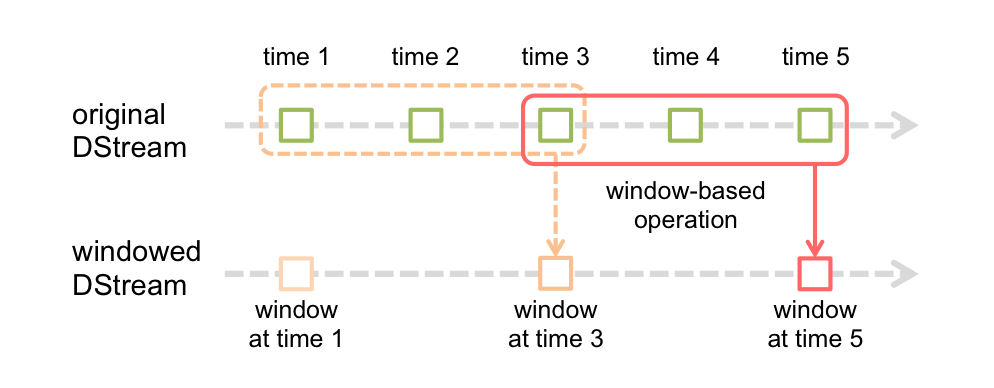
每次窗口在源 DStream 上滑动时,都会对位于窗口内的源 RDD 进行组合和操作,以生成窗口 DStream 的 RDD。图中,操作应用于最后 3 个时间单位的数据,并滑动 2 个时间单位。这表明任何窗口操作都需要指定两个参数。
- 窗口长度——窗口的持续时间(图中的 3)。
- 滑动间隔——执行窗口操作的间隔(图中为 2)。
这两个参数必须是源DStream的批处理间隔的倍数(图中为1)。
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))Checkpoint
Spark Streaming应用程序如果不手动停止,则将一直运行下去,在实际中应用程序一般是24小时*7天不间断运行的,因此Streaming必须对诸如系统错误,JVM出错等与程序逻辑无关的错误(failures)具体很强的弹性,具备一定的非应用程序出错的容错性。Spark Streaming的Checkpoint机制便是为此设计的,它将足够多的信息checkpoint到某些具备容错性的存储系统如hdfs上,以便出错时能够迅速恢复。有两种数据可以checkpoint:
Metadata checkpointing:
- 将流式计算的信息保存到具备容错性的存储上比如HDFS,Metadata Checkpointing适用于当streaming应用程序Driver所在的节点出错时能够恢复,元数据包括:
- Configuration(配置信息) : 创建streaming应用程序的配置信息
- Dstream operations : 在streaming应用程序中定义的DStreaming操作
- Incomplete batches : 在队列中没有处理完的作业
Data checkpointing:
- 对有状态的transformation操作进行checkpointing
Spark Structured Streaming
结构化流式处理是一种基于 Spark SQL 引擎构建的可扩展且容错的流式处理引擎。
可以像在静态数据上表达批量计算一样表达流式计算。
Spark SQL 引擎将负责逐步和连续地运行它,并在流数据不断到达时更新最终结果
默认情况下,结构化流查询使用微批处理引擎进行处理,该引擎将数据流作为一系列小批量作业进行处理,从而实现低至 100 毫秒的端到端延迟和恰好一次的容错保证。但是,自 Spark 2.3 以来,我们引入了一种称为连续处理的新低延迟处理模式,它可以实现低至 1 毫秒的端到端延迟,并保证至少一次。无需更改查询中的数据集/数据帧操作,您将能够根据应用程序需求选择模式。
val spark: SparkSession = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words: Dataset[String] = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts: DataFrame = words.groupBy("value").count()
val query: StreamingQuery = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()输出模式
- 完整模式(Complete)- 整个更新的结果表将写入外部存储。由存储连接器决定如何处理整个表的写入。
- 追加模式(Append)- 只有自上次触发以来追加到结果表中的新行才会写入外部存储。这仅适用于结果表中现有行预计不会发生变化的查询。
- 更新模式(Update)- 仅将自上次触发以来在结果表中更新的行写入外部存储(自 Spark 2.1.1 起可用)。请注意,这与完整模式不同,因为此模式仅输出自上次触发以来已更改的行。如果查询不包含聚合,则它将相当于追加模式。
事件时间下的窗口处理
- 窗口10 min ,步长 5min ,在12:10需要计算的有两个窗口 12:00 - 12:10、12:05 - 12:15
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()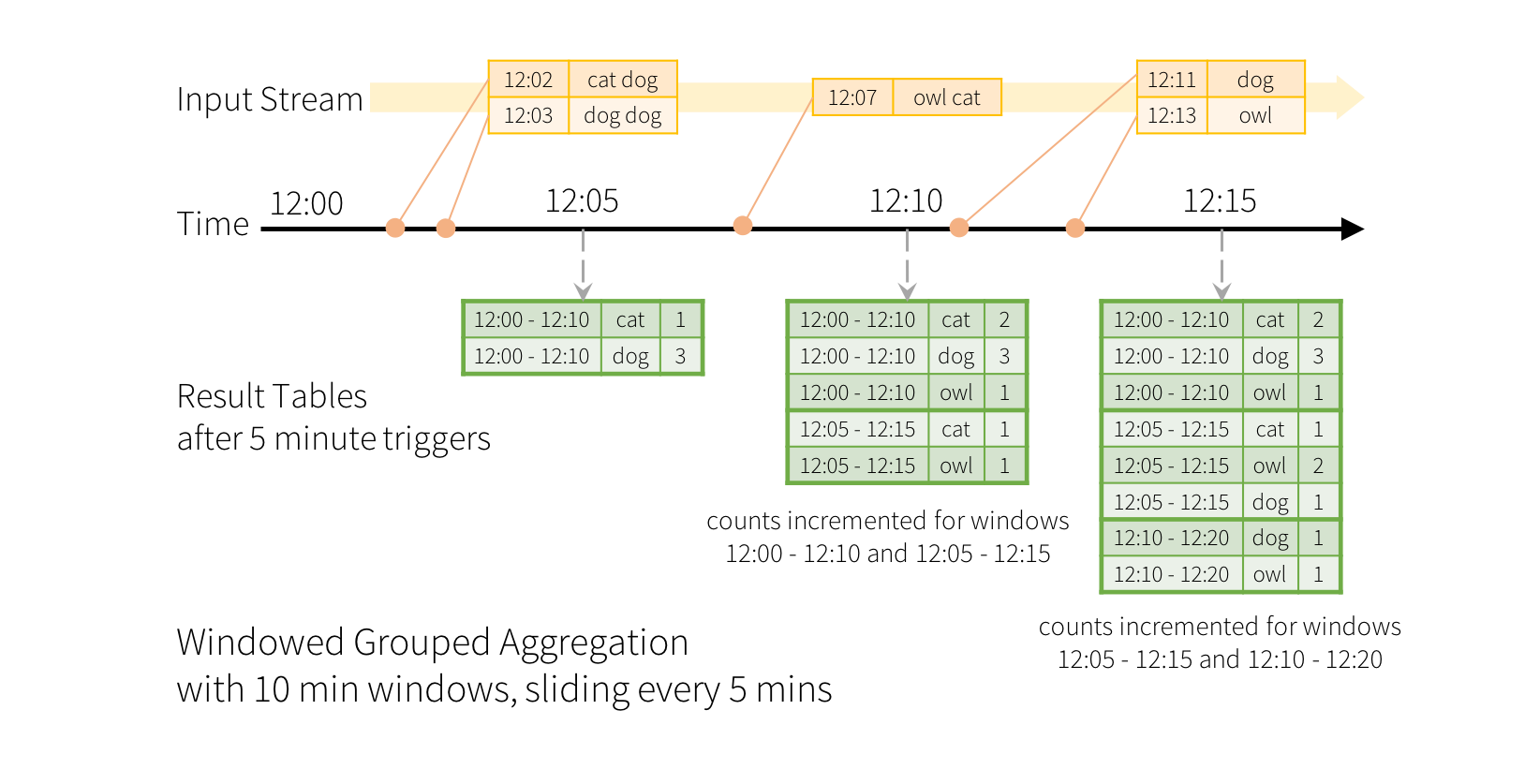
2.延迟数据和水印
水印可以让引擎自动跟踪数据中的当前事件时间并尝试相应地清理旧状态。 可以通过指定事件时间列和数据在事件时间方面预计有多晚的阈值来定义查询的水印
阈值内的晚期数据将被聚合,但晚于阈值的数据将开始被删除
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()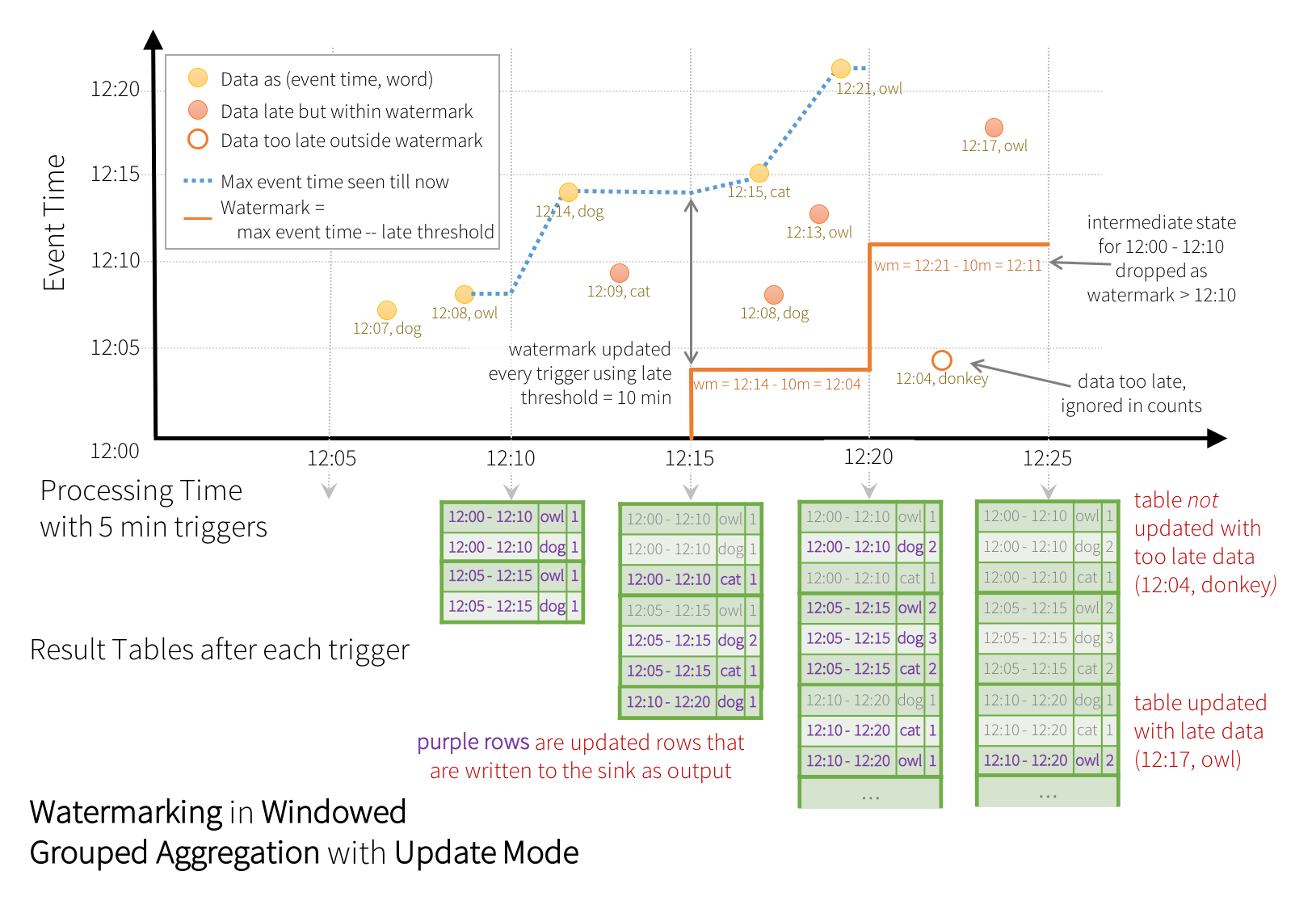
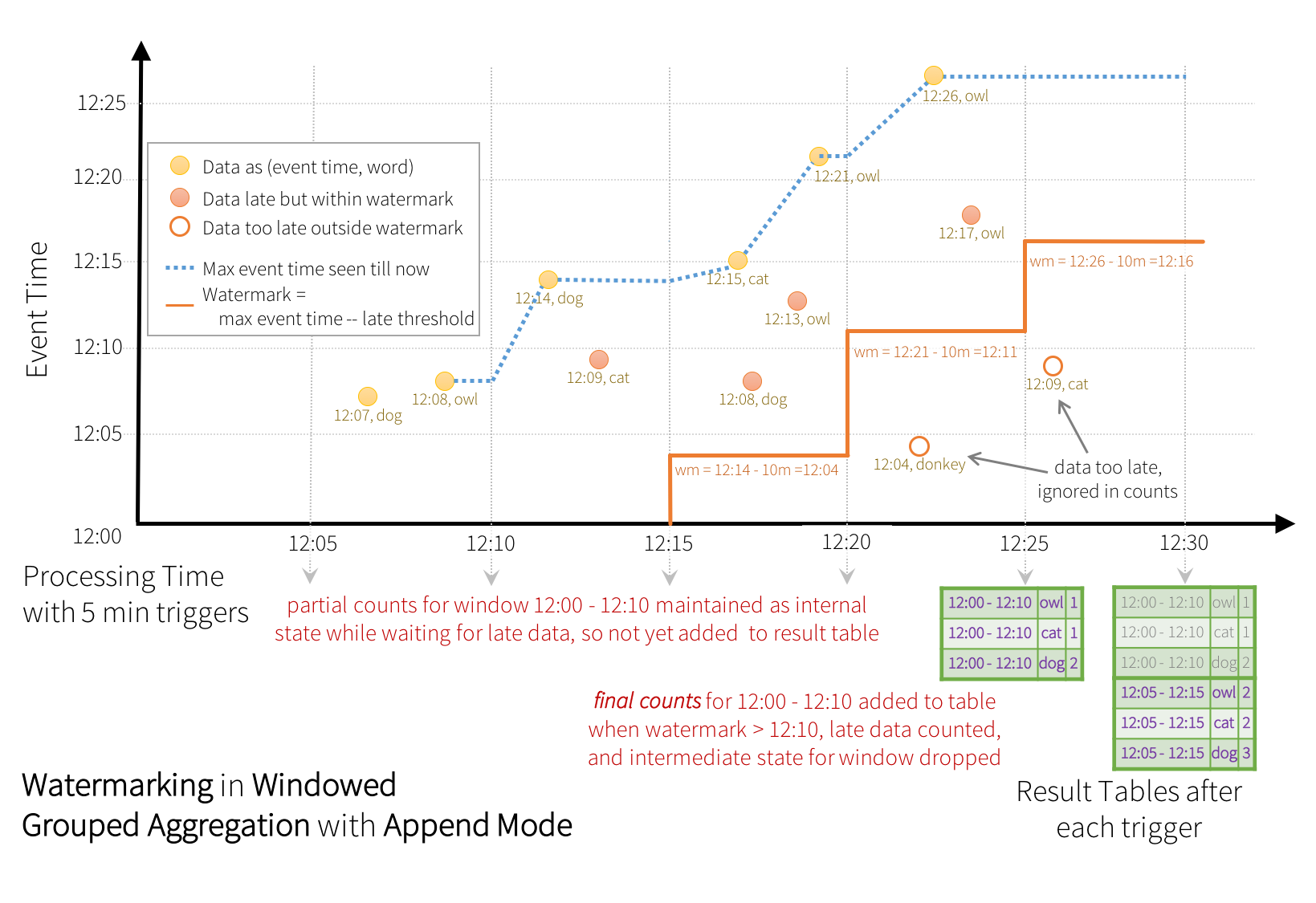
窗口类型
滚动(固定)、滑动和会话
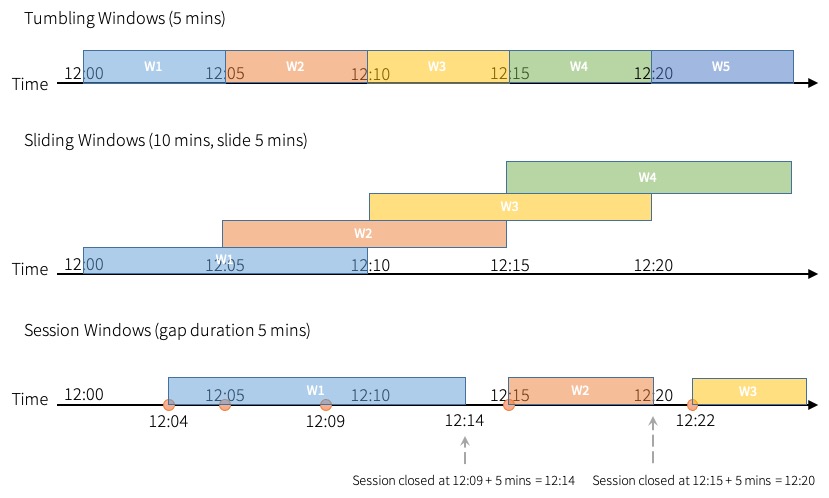
Spark Stream 背压
batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;
越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积
Spark 1.5 版本之前,对于 Receiver-based 数据接收器,我们可以通过配置 spark.streaming.receiver.maxRate 参数来限制每个 receiver 每秒最大可以接收的记录的数据;对于 Direct Approach 的数据接收,我们可以通过配置 spark.streaming.kafka.maxRatePerPartition 参数来限制每次作业中每个 Kafka 分区最多读取的记录条数
- 我们需要事先估计好集群的处理速度以及消息数据的产生速度;
- 这两种方式需要人工参与,修改完相关参数之后,我们需要手动重启 Spark Streaming 应用程序;
- 如果当前集群的处理能力高于我们配置的 maxRate,而且 producer 产生的数据高于 maxRate,这会导致集群资源利用率低下,而且也会导致数据不能够及时处理。
背压组件
RateController(driver): RateController 组件是 JobScheduler 的监听器,主要监听集群所有作业的提交、运行、完成情况,并从 BatchInfo 实例中获取以下信息,交给速率估算器(RateEstimator)做速率的估算
RateEstimator(driver):Spark 2.x 只支持基于 PID 的速率估算器
RateLimiter(executor):RateLimiter是一个抽象类,它并不是Spark本身实现的,而是借助了第三方Google的GuavaRateLimiter来产生的。它实质上是一个限流器,也可以叫做令牌,如果Executor中task每秒计算的速度大于该值则阻塞
MySQL
ACID
- Atomicity(原子性):一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚.
- Consistency(一致性):数据库总是从一个一致性状态转换到另一个一致状态。
- Isolation(隔离性):通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。
- Durability(持久性):一旦事务提交,则其所做的修改就会永久保存到数据库中。
事务隔离级别
读未提交(READ UNCOMMITTED)
所有事务都可以看到其他未提交事务的执行结果
引发的问题是——**脏读(Dirty Read)**:读取到了未提交的数据
读提交 (READ COMMITTED)
只能读取到已经提交的事务的数据
引发的问题是——**不可重复读(Nonrepeatable Read)**:在同一个事务中两次查询结果可能不同
可重复读 (REPEATABLE READ)
在同一个事务中多次查询的结果一致,
使用行级锁,锁定该行,事务A多次读取操作完成后才释放该锁,这个时候才允许其他事务更改刚才的数据,针对update操作
引发的问题是——幻读(Phantom Read):读取到了其他事务新增的数据,针对insert delete操作
innoDB通过mvcc和间隙锁解决幻读问题
串行化 (SERIALIZABLE)
强制事务排序,使之不可能相互冲突
锁机制
共享锁与排他锁
- 共享锁(S 读锁):其他事务可以读,但不能写。
- 排他锁(X 写锁) :其他事务不能读取,也不能写。
锁粒度
MyISAM 支持表级锁
InnoDB 支持行锁和表锁 的多粒度锁
为了实现多粒度锁机制,内部使用两种意向锁 意向共享锁(IS)和 意向排他锁(IX) 这两种锁都是表锁
意向共享锁/读锁(IS Lock):当事务想要获得一张表中某几行的读锁(行级读锁)时,InnoDB 存储引擎会自动地先获取该表的意向读锁(表级锁)
意向排他锁/写锁(IX Lock):当事务想要获得一张表中某几行的写锁(行级写锁)时,InnoDB 存储引擎会自动地先获取该表的意向写锁(表级锁)
如果想要申请表锁,则可以判断是否有意向锁或者有表锁,不用一行数据一行数据判断是有有行锁,提高效率
InnoDB间隙锁:
- 用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁
- 使用间隙锁可以防止幻读
InnoDB行锁
InnoDB 行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB 才使用行级锁,否则,InnoDB 将使用表锁
两段锁
加锁分为两个步骤,begin 最后commit释放所有锁
一开始并不知道后续执行的sql,所以没有办法对所有用到的数据加锁,所以可能会导致死锁
- 死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源
- 数据库系统实现了死锁检测和死锁超时的机制。InnoDB存储引擎能检测到死锁的循环依赖并立即返回一个错误
- 在涉及外部锁,或涉及表锁的情况下,InnoDB 并不能完全自动检测到死锁, 这需要通过设置锁等待超时参数 innodb_lock_wait_timeout 来解决
- 死锁发生以后,只有部分或完全回滚其中一个事务,才能打破死锁,InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚。
乐观锁&悲观锁
乐观锁(Optimistic Lock):假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性,在业务中插入时判断版本号或时间戳
悲观锁(Pessimistic Lock):假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
MVCC
mvcc的实现原理主要依赖于记录中的隐藏字段,undolog,read view来实现的
隐藏字段
DB_ROW_ID是数据库默认为该行记录生成的唯一隐式主键
DB_TRX_ID是当前操作该记录的事务ID
DB_ROLL_PTR是一个回滚指针,用于配合undo日志,指向上一个旧版本
如果是删除数据会用Delete_Bit标识
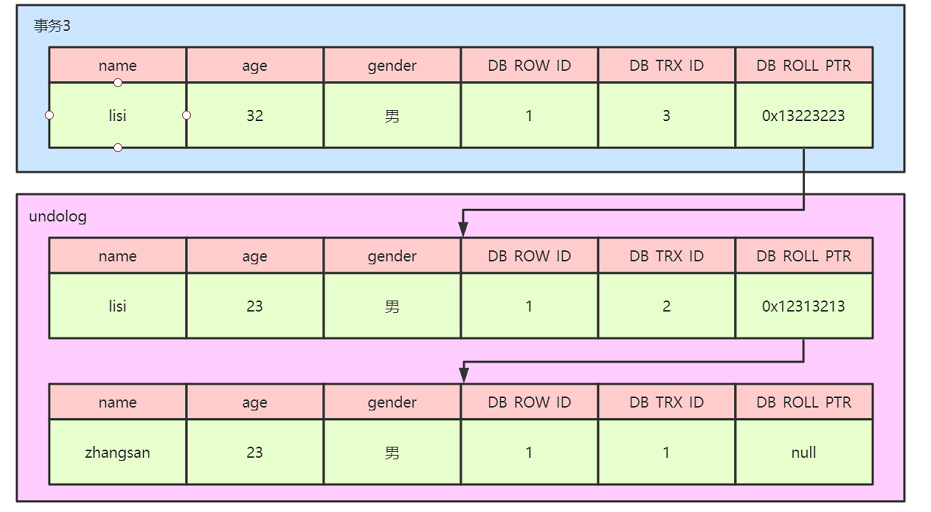
ReadView
Read View是事务进行快照读操作的时候生产的读视图,在该事务执行快照读的那一刻,会生成一个数据系统当前的快照,记录并维护系统当前活跃事务的id,事务的id值是递增的,Read View的最大作用是用来做可见性判断的
Read View中的三个全局属性:
m_ids:一个数值列表,用来维护Read View生成时刻系统正活跃的事务ID
min_trx_id:记录trx_list列表中事务ID最小的ID
max_trx_id:Read View生成时刻系统尚未分配的下一个事务ID
creator_trx_id:当前事务id
具体的比较规则如下:
1、如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
2、如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
按照ReadView中的比较规则(后两条):
3、如果被访问版本的trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
4、如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间(min_trx_id < trx_id < max_trx_id),那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
读已提交和可重复度区别
可重复读:某个事务的对某条记录的第一次快照读会创建一个快照即Read View,将当前系统活跃的其他事务记录起来,此后在调用快照读的时候,还是使用的是同一个Read View
读已提交:每次快照读都会新生成一个快照和Read View,这就是我们在RC级别下的事务中可以看到别的事务提交的更新的原因
redo log
InnoDB存储引擎是以页为单位来管理存储空间的。在访问真正的页面之前,需要把在 磁盘上的页 缓存到内存中的 Buffer Pool 之后才可以访问。所有的变更都必须新更新缓冲池中的数据,然后缓冲池中的脏页会以一定的频率被刷入磁盘(checkPoint机制),通过缓冲池来优化CPU和磁盘之间的鸿沟,这样就可以保证整体的性能不会下降太快。
为什么需要redolog
对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失
怎么保证持久性:
- 在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘
- 修改量与刷新磁盘工作量严重不成比例:有时候我们仅仅修改了某个页面中的一个字节,但是我们知道在InnoDB中是以页为单位来进行磁盘IO的,也就是说我们在该事务提交时不得不将一个完整的页面从内存中刷新到磁盘。我们又知道一个页面默认是16KB大小,只修改一个字节就要刷新16KB的数据到磁盘上显然是太小题大做了。
- 随机IO刷新较慢:一个事务可能包含很多语句,即使是一条语句也可能修改许多页面,假如该卖务修改的这些页面可能并不相邻,这就意味着在将某个事务修改的Buffer Pool中的页面刷新到磁盘时,需要进行很多的随机IO,随机IO比顺序IO要慢,尤其对于传统的机械硬盘来说
- 每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好
redo log 用来实现事务的持久性,即事务 ACID 中的 D。其由两部分组成:
- 一是内存中的重做缓冲日志(redo log buffer),其是 **
易失的**; - 二是**重做日志文件 (redo log file)**,其是 **
持久的**。
redo log刷盘策略:innodb_flush_log_at_trx_commit
redo log buffer刷盘到redo log file的过程并不是真正的刷到磁盘中去,只是刷入到文件系统缓存(page cache)中去(这是现代操作系统为了提高文件写入效率做的一个优化),真正的写入会交给系统自己来决定(比如page cache足够大了)。那么对于InnoDB来说就存在一个问题,如果交给系统来同步,同样如果系统宕机,那么数据也丢失了(虽然整个系统宕机的概率还是比较小的)
设置为0 :表示每次事务提交时不触发刷盘操作(都没有将redo log buffer中的内容写入 page cache中,其实就是啥也没做)。(系统默认master thread每隔1s进行一次重做日志的同步)
设置为1 :表示每次事务提交时都将进行同步,刷盘操作( 默认值)
设置为2 :表示每次事务提交时都 只把 redo log buffer 内容写入 page cache,不进行同步。由os自己决定什么时候同步到磁盘文件
checkpoint
磁盘上的redo日志文件不止一个,而是以一个日志文件组的形式出现的。在redo日志写入日志文件组的时候,是从 ib_logfile0 开始写,如果写满了,就接着 ib_logfile1 写,以此类推。那如果最后一个文件写满了,那就重新转到 ib_logfile0 继续写
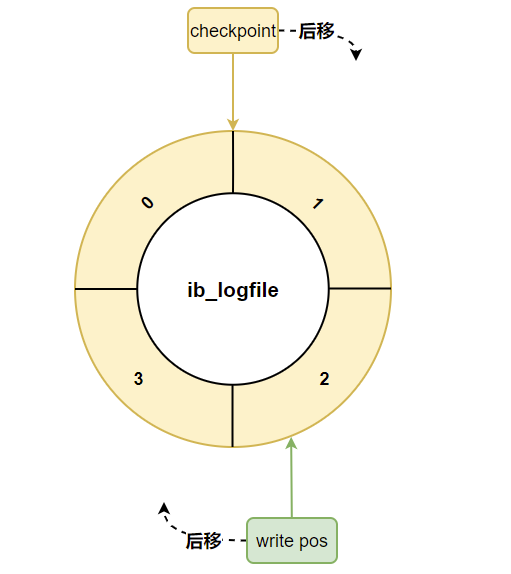
MySQL索引
按数据结构分类可分为:B+tree索引、Hash索引、Full-text索引。
按物理存储分类可分为:聚簇索引、二级索引(辅助索引)。
按字段特性分类可分为:主键索引、普通索引、前缀索引。
按字段个数分类可分为:单列索引、联合索引
B+Tree聚簇索引
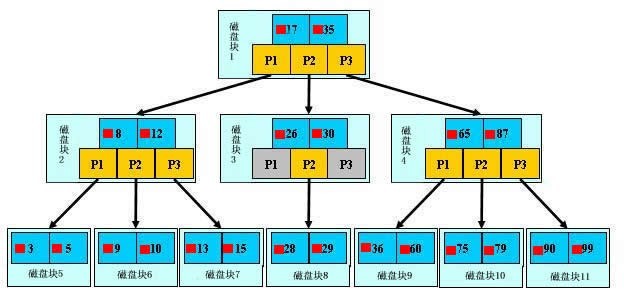
浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示)
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低
B+tree 非叶子节点只存储键值信息, 数据记录都存放在叶子节点中
B+tree 所有叶子节点之间都采用单链表连接。适合MySQL中常见的基于范围的顺序检索场景
二级索引
二级索引的叶子节点并不存储一行完整的表数据,而是存储了聚簇索引所在列的值
二级索引的叶子节点不存储完整的表数据,索引当通过二级索引查询到聚簇索引列值后,还需要回到聚簇索引也就是表数据本身进一步获取数据 (回表)
OTHER
一致性hash
普通hash hash(key)%N 当扩容或服务不可用是 N值变化 对hash结果影响很大
一致性hash:
将服务节点映射到一个 0 ~ (2^32)-1 大小的环形空间中,然后目标值通过计算出来的hash顺时针找第一个服务节点hash
并且为了避免 数据不均衡的情况,可以将一个服务节点虚拟出多个节点(虚拟出多个hash值)
CAP理论
- 一致性(C):在分布式系统分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 弱一致性(Weak):写入一个数据a成功后,在数据副本上可能读出来,也可能读不出来。不能保证多长时间之后每个副本的数据一定是一致的。
- 最终一致性(Eventually):写入一个数据a成功后,在其他副本有可能读不到a的最新值,但在某个时间窗口之后保证最终能读到。可以看做弱一致性的一个特例。这里面的重点是这个时间窗口。
- 强一致性(Strict):数据a一旦写入成功,在任意副本任意时刻都能读到a的最新值。
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
BASE理论
BASE理论是在CAP定理上,依据行业实践经验,逐渐演化出来的一种分布式方案。
- (BA)基本可用:分布式系统故障时,允许损失部分可用性,提供基本可用的服务。
- 允许在响应时间上的可用性损失:正常情况下,外卖下单需要0.5s;异常情况下,外卖下单需要3s。
- 允许在功能上的可用性损失:正常情况下,订单、评价服务都正常;异常情况下,只保证订单服务正常。
- (S)软状态:分布式系统中,允许存在的一种中间状态,也叫弱状态或柔性状态。
- 举例:在下单支付时,让页面显示
支付中,直到支付数据同步完成。
- 举例:在下单支付时,让页面显示
- (E)最终一致性:在出现软状态的情况下,经过一段时间后,各项数据最终到底一致。
- 举例:在
支付中这个软状态时,数据并未一致,软状态结束后,最终支付数据达到一致。
- 举例:在
MPP数据库
Massively Parallel Processing 大规模并行处理
MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果
MPP与HADOOP对比
两类系统运行的硬件架构是相同的,都是普通服务器组成的集群,但从资源管理角度来说,它们并行化软件实现的设计思路却是相反的。
MPP架构相当于对单机的各类资源进行垂直综合管理,再将多个单机系统横向连接进行集成,可以说是先垂直后水平。
Hadoop架构相当于将所有机器的存储资源与计算资源抽象出来,分开管理,再进行组件级的垂直集成,可以说是先水平后垂直
Flink
Flink Zookeeper 高可用
- Application Master:
YarnApplicationClusterEntryPoint
// 参数 yarnApplicationClusterEntrypoint 为 YarnSessionClusterEntrypoint
ClusterEntrypoint.runClusterEntrypoint(yarnApplicationClusterEntrypoint);
// clusterEntrypoint 为参数yarnApplicationClusterEntrypoint 即 YarnSessionClusterEntrypoint
clusterEntrypoint.startCluster();
//ClusterEntrypoint的方法
runCluster();
//ClusterEntrypoint的方法
initializeServices();
//ClusterEntrypoint的方法
//返回值是 HighAvailabilityServices实现类
haServices = createHaServices();
HighAvailabilityServicesUtils.createHighAvailabilityServices();
//判断是zookeeper调用下面方法
createZooKeeperHaServices(configuration, executor, fatalErrorHandler);
//创建并CuratorFramework 并调用CuratorFramework.start
//Apache Curator 可以更容易的使用ZooKeeper,并且对leader选举等做了封装
// 然后将Curator作为作为构造器参数 创建ZooKeeperLeaderElectionHaServices实例并返回
public ZooKeeperLeaderElectionHaServices(
CuratorFrameworkWithUnhandledErrorListener curatorFrameworkWrapper,
Configuration configuration,
Executor executor,
BlobStoreService blobStoreService)
throws Exception {
super(
configuration,
new ZooKeeperLeaderElectionDriverFactory(
ZooKeeperUtils.useNamespaceAndEnsurePath(
curatorFrameworkWrapper.asCuratorFramework(),
ZooKeeperUtils.getLeaderPath())), // leaderPath --> leader
executor,
blobStoreService,
FileSystemJobResultStore.fromConfiguration(configuration, executor));
this.curatorFrameworkWrapper = checkNotNull(curatorFrameworkWrapper);
}
// 父类构造器方法
protected AbstractHaServices(
Configuration config,
LeaderElectionDriverFactory driverFactory,
Executor ioExecutor,
BlobStoreService blobStoreService,
JobResultStore jobResultStore) {
this.configuration = checkNotNull(config);
this.ioExecutor = checkNotNull(ioExecutor);
this.blobStoreService = checkNotNull(blobStoreService);
this.jobResultStore = checkNotNull(jobResultStore);
this.leaderElectionService = new DefaultLeaderElectionService(driverFactory);
}
//ZooKeeperLeaderElectionDriverFactory创建ZooKeeperLeaderElectionDriver
ZooKeeperLeaderElectionDriver implements LeaderElectionDriver, LeaderLatchListener
//curator接口
LeaderLatchListener
//调用leaderElectionListener.onGrantLeadership(leaderSessionID); LeaderElectionDriver.Listener
void isLeader();
//调用leaderElectionListener.onRevokeLeadership();
void notLeader();
//由上面构造器可以看出 leaderElectionService leader选举服务 实现类DefaultLeaderElectionService
public class DefaultLeaderElectionService extends DefaultLeaderElection.ParentService
implements LeaderElectionService, LeaderElectionDriver.Listener, AutoCloseable
DefaultLeaderElection.ParentService
//如果判断leaderElectionDriver是空值 leaderElectionDriver = leaderElectionDriverFactory.create(this);
//放到map里面 leaderContenderRegistry.put(componentId, contender)
//如果当前是leader ,调用leaderContenderRegistry.get(componentId).grantLeadership(issuedLeaderSessionID);
abstract void register(String componentId, LeaderContender contender) throws Exception; //注册竞选者
//leaderContenderRegistry.remove(componentId);
//如果当前是leader ,调用contender.revokeLeadership();
abstract void remove(String componentId) throws Exception;//移除竞选者
abstract void confirmLeadership(String componentId, UUID leaderSessionID, String leaderAddress);
abstract boolean hasLeadership(String componentId, UUID leaderSessionID);
LeaderElectionService
//返回DefaultLeaderElection
LeaderElection createLeaderElection(String componentId);
LeaderElectionDriver.Listener
// leaderContenderRegistry.get(componentId).grantLeadership(issuedLeaderSessionID);
// 调用所有竞选者的grantLeadership
void onGrantLeadership(UUID leaderSessionID);
// 调用所有竞选者的contender.revokeLeadership();
void onRevokeLeadership();
void onLeaderInformationChange(String componentId, LeaderInformation leaderInformation);
void onLeaderInformationChange(LeaderInformationRegister leaderInformationRegister);
void onError(Throwable t);